
Track
Machine Learning Scientist in Python
85 hr
NVIDIA's cuML is a GPU-accelerated machine learning library that is part of the RAPIDS AI ecosystem. And now, in open beta, cuML 25.02 makes it possible to have GPU acceleration in scikit-learn, UMAP, and HDBSCAN without changing your Python code. This is going to prove very interesting news for Python machine learning engineers, data and research scientists, developers, and so many more professionals who look forward to seeing an increase in the performance of their models.
Don’t worry if you aren’t up to speed with cuML or even the idea of GPU acceleration. I’ll take you on a tour and, by the end of this article, you’ll be able to use GPU acceleration for your regression, classification, dimensionality reduction, or clustering problems.
Let’s take a quick moment to get all the pieces in the right place.
NVIDIA develops cutting-edge technologies that power high-performance computing, AI, and data science. You might remember they were in the news a lot when Deepseek dropped Deepseek-R1 and people were asking if Deepseek used NVIDIA chips.
Well, NVIDIA is in the news again, this time for innovations in its RAPIDS AI ecosystem. RAPIDS AI, if you aren't familiar, is an open-source suite of GPU-accelerated libraries designed to speed up data science and machine learning workflows. RAPIDS is built on CUDA (Compute Unified Device Architecture) which is a parallel computing platform and API model, also developed by NVIDIA. RAPIDS GPU-accelerated libraries include:
Now, about cuML: cuML provides highly optimized implementations of classical machine learning algorithms. Because NVIDIA has the best AI chips, these algorithms, which run on NVIDIA GPUs, have a significant speedup. GPUs, unlike CPUs, excel at parallel processing, which practically means they can handle thousands of computations at the same time, making them ideal for tasks like (you guessed it) deep learning and machine learning.
If you aren’t familiar with scikit-learn and you are serious about machine learning and data science, you should definitely enroll in our Supervised Learning with scikit-learn course. I’m saying this because scikit-learn is the number one library for tabular data in the number one most popular programming language for machine learning. What is more, scikit-learn is fairly easy to learn and has a simple API and it also works well with pandas and NumPy. It's no surprise, therefore, that the RAPIDS AI team is focusing on scikit-learn algorithms as a strategic and natural choice.
NVIDIA and cuML now offer the big innovation to scikit-learn, and also UMAP and HDBSCAN, of a massive boost in performance speed. According to the RAPIDS AI team, this means up to 50x speed when using scikit-learn, 60x for UMAP, and 175x for HDBSCAN.
My back-of-the-envelope math tells me that an algorithm that might take five minutes to run on scikit-learn could theoretically be cut down to as little as six seconds. That's a big difference. I'll spend a bit more time on this when looking at benchmarks down below.
If all this sounds complex, don’t worry. RAPIDS AI is committed to zero code changes required to the API code for scikit-learn. Really, you just need to load the extension, like this:
%load_ext cuml.accel
$ python -m cuml.accel script.pyThis is not such a big change to the workflow that you are used to, which is the whole idea. On occasion, maybe, you have to restart the kernel and load the extension again.
This zero-code-change aspect is actually, in my opinion, at first glance a really exciting claim. The idea here is that you don’t have to change your already-created scikit-learn scripts - not the first time, but also not ever. cuML would automatically accelerate compatible components on NVIDIA GPUs, but if there is something happening in your code that is not compatible with NVIDIA’s GPUs, your script will fall back to the ‘normal’ CPU execution. You, as the coder, will just see the result and you don't have to worry about error handling or anything else.
All that said, I still would expect edge cases that may require adjustments. In coding, things can go wrong, and nothing is ever quite as easy as it seems. The reference documentation has certain things that almost belie the 'no code changes' claim, or at least add a bit of friction to it. You have to convert lists to NumPY arrays or Pandas DataFrames, and string labels aren't supported, so users have to pre-encode categorical labels. You might do this stuff anyway, but the point is there are other things you might also have to get used to besides just loading the extension.
If you were practicing basic statistics by running a simple linear regression on the mtcars dataset, there wouldn’t be much use in using GPU acceleration to find the slope and intercept of the line just a tiny bit faster. Saving fractions of a second wouldn’t even be worth loading the extension, really. But if instead you were running a more complex algorithm, the time saved really matters for two main reasons.
For one thing, the time you save is significant for many workflows. I mentioned that up to a 50x speed boost would translate, hypothetically, to reducing a five-minute training time down to six seconds. That’s a savings of almost five minutes. But consider the machine learning engineer’s workflow, where the model might require running it a few times to get it right. Added up, talking about saving time on each run is to talk about a data scientist’s overall productivity.
Secondly, and relatedly, the scientist or engineer could now start trying for more complex models. In the previous example, we are assuming a time speed for a model that yields the same level of accuracy. But what if you thought you would actually have higher accuracy with a more complex model? Imagine doing a grid search of different model parameters and training a model. (I'll try my own mini example, below.) The permutations grow exponentially, making the computational cost prohibitive on a CPU. But that’s not such a problem if you have a 50x boost in speed.
These benefits go together. If you set up your project right, you might have a more accurate model that is also produced faster or, as a machine learning engineer might think of it, you could have a more sophisticated model architecture without excessive training times.
NVIDIA takes some effort to talk about how the GPUs would reveal numerically equivalent results. That's good to hear because it means that the benefits don't come with drawbacks in terms of model accuracy.
But this also got me thinking: Why are the results numerically equivalent and not the same? Well, probably, as a result of parallel processing, there are some small differences in the output, or there are some differences in the numerical stability of a given method. Maybe in the case of UMAP the UMAP projection is slightly different. I’m bringing this up in case you were to see subtle differences in the output between the CPU and GPU run. NVIDIA seems to suggest that you should expect to see some of that, and that it's normal.
All that said, if you are really challenging yourself and you run a model on GPUs because the model is complex enough that CPUs don't practically work, then comparing said model's output to a CPU equivalent would become difficult.
I mentioned earlier that there is now support in this cuML 25.02 release for scikit-learn, UMAP, and HDBSCAN. But if you are familiar with scikit-learn, you know there are a many different algorithms in scikit-learn. Currently, RAPIDS AI supports some of the libraries, but not all of them. Here are the main shoutouts, according to the team:
In this list, I would be most excited for a speed boost in k-Nearest Neighbors, which is known to be highly computationally intensive because you have to calculate distances between all data points.
The following table shows you the estimators that are mostly or entirely run with cuML.
| Algorithm | Library / Function Name | Category |
|---|---|---|
| UMAP | umap.UMAP |
Dimensionality Reduction |
| PCA (Principal Component Analysis) | sklearn.decomposition.PCA |
Dimensionality Reduction |
| Truncated SVD | sklearn.decomposition.TruncatedSVD |
Dimensionality Reduction |
| t-SNE | sklearn.manifold.TSNE |
Dimensionality Reduction |
| HDBSCAN | hdbscan.HDBSCAN |
Clustering |
| K-Means | sklearn.cluster.KMeans |
Clustering |
| DBSCAN | sklearn.cluster.DBSCAN |
Clustering |
| Random Forest Classifier | sklearn.ensemble.RandomForestClassifier |
Classification |
| Logistic Regression | sklearn.linear_model.LogisticRegression |
Classification |
| K-Nearest Neighbors Classifier | sklearn.neighbors.KNeighborsClassifier |
Classification |
| Random Forest Regressor | sklearn.ensemble.RandomForestRegressor |
Regression |
| Linear Regression | sklearn.linear_model.LinearRegression |
Regression |
| Elastic Net | sklearn.linear_model.ElasticNet |
Regression |
| Ridge Regression | sklearn.linear_model.Ridge |
Regression |
| Lasso Regression | sklearn.linear_model.Lasso |
Regression |
| Kernel Ridge Regression | sklearn.kernel_ridge.KernelRidge |
Regression |
| K-Nearest Neighbors Regressor | sklearn.neighbors.KNeighborsRegressor |
Regression |
| Nearest Neighbors Search | sklearn.neighbors.NearestNeighbors |
Nearest Neighbors Search |
A full list of supported methods is available in RAPIDS AI documentation. We expect more algorithms will be added soon. (You can also provide some feedback to help the team prioritize.) Some of the ones I noticed missing: support vector regressor (sklearn.svm.SVR), Theil-Sen Regressor (sklearn.linear_model.TheilSenRegressor), mean shift clustering (sklearn.cluster.MeanShift), and multidimensional scaling (sklearn.manifold.MDS).
You might be wondering how all this works. From 30k feet, know that, more and more, modern libraries are being designed to automatically detect and use the best available hardware, whether it's a CPU or a GPU. We are seeing now that, when a function is called in scikit-learn (when cuml.accel is enabled), the software is checking if a compatible GPU is available and redirects execution to a GPU-accelerated version if it is.
RAPIDS AI talks about this mechanism to make cuml.accel act like sklearn as a compatibility layer. In this case, cuML’s compatibility layer lets scikit-learn code run on NVIDIA GPUs without changes. It’s built as a drop-in replacement and acts as a proxy and intercepts function calls to scikit-learn and redirects them to cuML.
NVIDIA's RAPIDS AI team shares a helpful graphic which I'll share here, also:
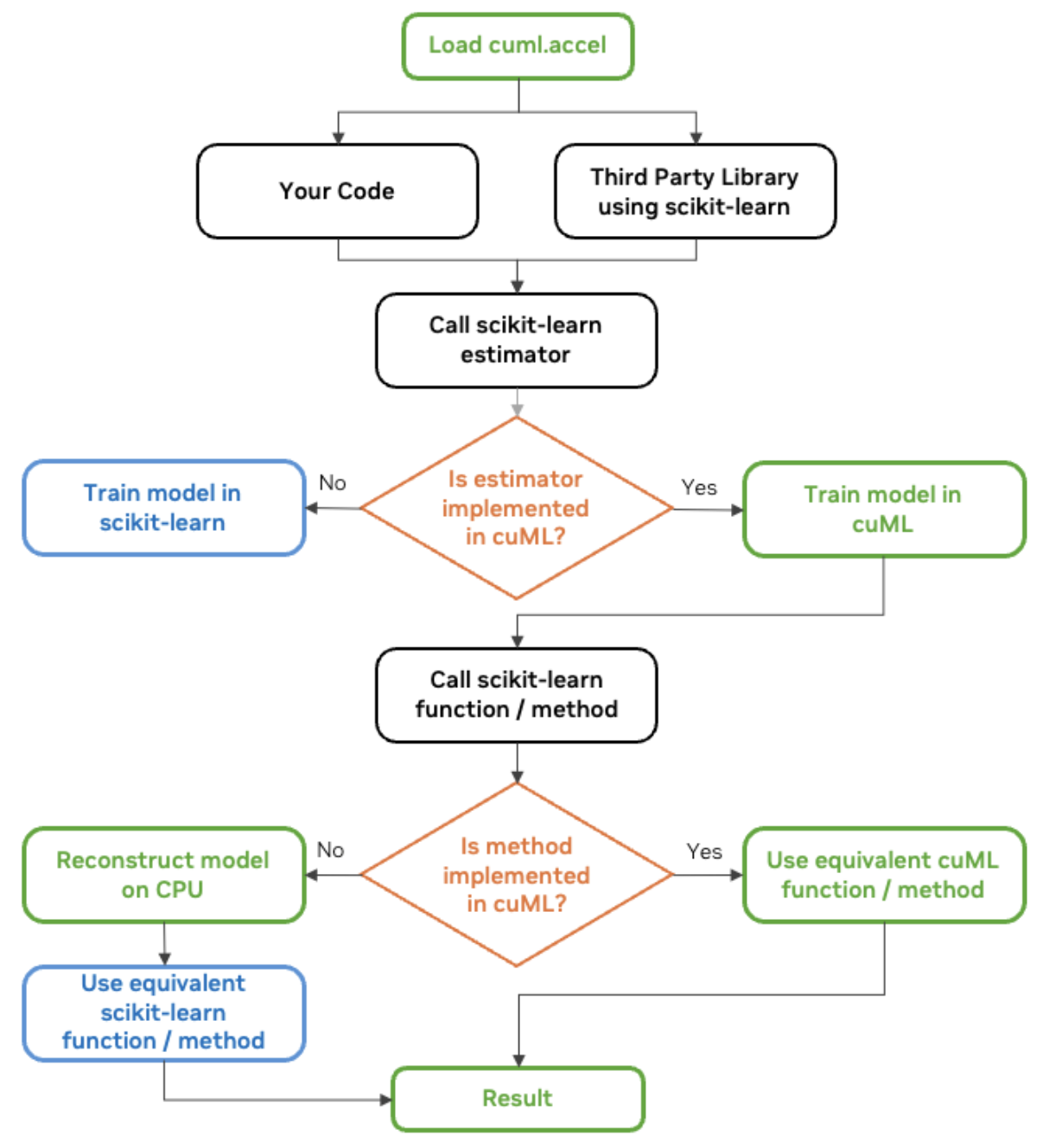
cuML scikit-learn workflow diagram. Source: NVIDIA
cuML is already pre-installed in Google Colab, but if you’re using a Jupyter notebook, activate it with this command before importing scikit-learn:
%load_ext cuml.accel
import sklearnNow, our Python code using sklearn is going to look familiar, which is the whole point. Here is an example of an OLS regression.
# Import necessary libraries
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# Generate synthetic regression data
X, y = make_regression(n_samples=500000, n_features=50, noise=0.1, random_state=0)
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Create and train an OLS regression model
ols = LinearRegression()
ols.fit(X_train, y_train)If I want to see which parts had run on GPU instead of CPU, I could use logger.
%load_ext cuml.accel
from cuml.common import logger;
logger.set_level(logger.level_enum.debug)cuML: Installed accelerator for sklearn.
cuML: Successfully initialized accelerator.
cuML: Performing fit in GPUYou get the idea. Now, let's try a more convincing example. Linear regression is not especially parallelizable anyway since solving the normal equation or QR decomposition involves some sequential operations.
A more complex extension of OLS regression is ridge regression. When using ridge regression in Python, calling Ridge() applies default hyperparameters, which may not be optimal. The alpha value controls how much regularization is applied. Too small and the model overfits; too large and the model underfits.
%load_ext cuml.accel
import sklearn
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate synthetic data
X, y = make_regression(n_samples=100000, n_features=50, noise=0.1, random_state=0)
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Train a Ridge Regression model with default settings
ridge_default = Ridge()
ridge_default.fit(X_train, y_train)
# Make predictions and evaluate
y_pred_default = ridge_default.predict(X_test)
mse_default = mean_squared_error(y_test, y_pred_default)
The code above trains one model, using a single alpha value and solver. (I believe it defaults to 'auto'.) So, while this works, it doesn’t optimize the regularization strength or solver choice.
Instead of relying on defaults, we could try something else. We could create a grid search that tests multiple hyperparameter combinations and selects the best one.
from sklearn.model_selection import GridSearchCV
# Define Ridge Regression model
ridge = Ridge()
# Define a grid of hyperparameters to search
param_grid = {
'alpha': [0.01, 0.1, 1.0, 10.0, 100.0], # Different regularization strengths
'solver': ['auto', 'svd', 'cholesky', 'lsqr', 'saga'] # Test multiple solvers
}
# Perform Grid Search with cross-validation
grid_search = GridSearchCV(ridge, param_grid, scoring='neg_mean_squared_error', cv=2, n_jobs=-1)
grid_search.fit(X_train, y_train)
# Get the best model from the search
best_ridge = grid_search.best_estimator_
# Make predictions and evaluate
y_pred_best = best_ridge.predict(X_test)
mse_best = mean_squared_error(y_test, y_pred_best)
Our grid search here tests all possible combinations of hyperparameters. If we define 5 values for alpha ([0.01, 0.1, 1.0, 10.0, 100.0]), 5 solver options (['auto', 'svd', 'cholesky', 'lsqr', 'saga']), and use 2-fold cross-validation, the total number of model trainings required is 5x5x2, or 50. This means instead of training one model, we train 50 models. This is much, much more complex, which is why GPUs will be so great to use because they are much, much faster. Because sklearn has (up to) a 50x boost in speed, training these 50 models might be the same amount of time as training just one. (I chose these numbers intentionally to illustrate that point. I recognize that not all models will have the same increase in speed.)
NVIDIA compared the performance of scikit-learn algorithms running on Intel CPUs versus its own NVIDIA GPUs. They looked at different machine learning workloads, including classification and regression.
The takeaway is that simple models like random forests went from minutes of training time on CPUs down to seconds of training time on GPUs, and more complex models like clustering went down from hours of training time to minutes. The workflows were faster in every case, but for the computationally heavy models with high-dimensional data, the benefits were even more clear. This is where GPUs shine because they use parallel processing and that is known to make a huge difference in models that require extensive matrix operations, distance calculations, or optimization that is done in an iterative way.
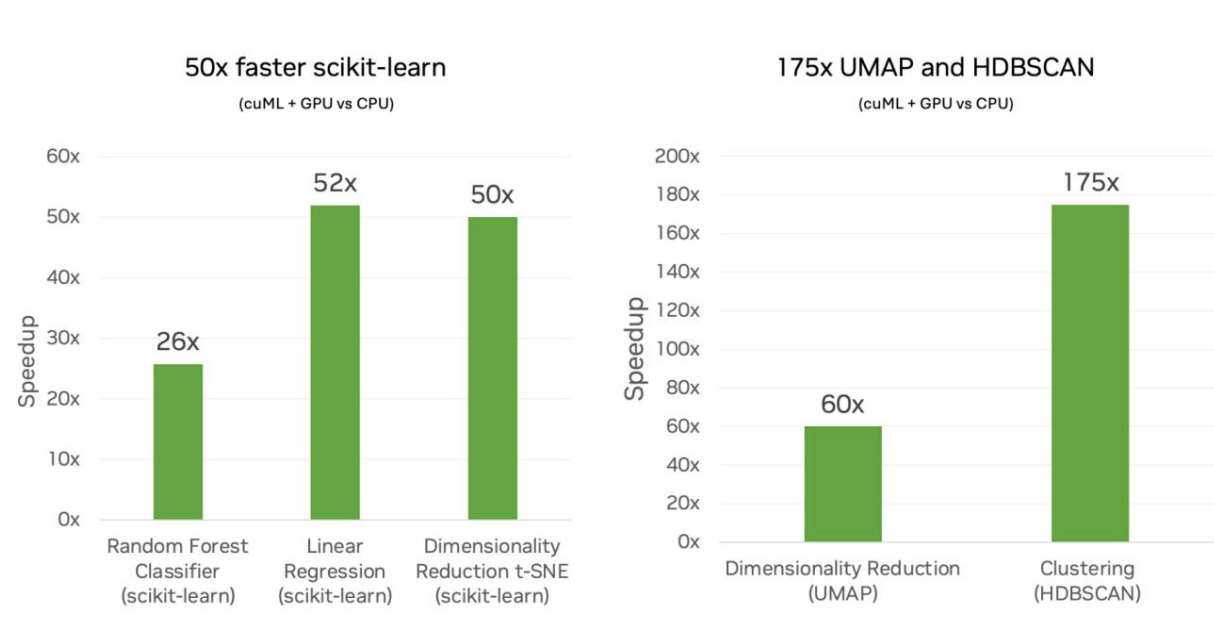
cuML scikit-learn on GPU vs scikit-learn on CPU. Source: NVIDIA
I stepped away from linear regression in the earlier coding example because I thought I should try something else to show the power. But here, I see a 52x speed up for linear regression. I admit I'm surprised because that sounds like a big multiple. It's a good reminder that NVIDIA is doing other advanced stuff also, like making sure different steps can be interleaved so the GPU isn’t idle.
Thanks to cuML version 25.02, running a scitkit-learn algorithm with GPUs is now not too difficult. You just have to load the extension, as I showed earlier. However, if you are deeper in the workflow and are interested in making the most of GPU acceleration, you will want to consider very specific things.
NVIDIA recommends minimizing data transfers between the CPUs and GPUs as part of your pipeline. In other words, do the pre-processing, training, and inference steps in GPUs before sending the results back to host memory. Don’t mishmash the steps by doing preprocessing in the CPUs and then inference in the GPUs.
Also, to maximize efficiency, you should consider CUDA-X, which is a collection of GPU-accelerated libraries developed by NVIDIA. For random forests, you could use cuML’s forest inference library, for example, instead of the one from scikit-learn.
What the RAPIDS AI team is doing is complex, so there's going to be some issues. Thankfully, the documentation for known limitations is well kept. I don't necessarily want to include all or even some of the limitations here because many of the issues are pretty much in-the-weeds of specific algorithms. Also, the updates or patches are moving fast. Instead, I'll give you the more general categories of things to consider.
There are some restrictions that apply across cuML, not just to specific algorithms. Examples here seem to include restrictions on data input formats (some problems with Python lists), version compatibility, and memory handling.
There are some unique constraints for individual machine learning algorithms. These differences may affect how models are trained, how parameters behave, or how results are computed. As an example, the random forest algorithm in cuML uses a different method for choosing split thresholds, leading to slightly different tree structures.
There are some differences with the parameters, solvers, and initialization methods that are supported. For example, PCA supports "full" and "auto" SVD solvers, but not "randomized." And KNN supports Minkowski metrics, but not Mahalanobis.
There are times when results may differ slightly due to parallelism or solver differences. I mentioned this earlier. For example, UMAP embeddings may not be identical, but the trustworthiness score should still be high. In other cases, PCA component signs may flip, requiring normalization. Again, this is a specific thing, and you should refer to the latest documentation when running a specific algorithm.
I'm excited about the prospect of super easy-to-use GPU acceleration for the well-known algorithms in the most common Python machine learning libraries. This is going to make a big difference in model accuracy, and it's convenient and not hard to implement.
Stay up to date with the latest in machine learning. Take our Machine Learning Scientist in Python career track to familiarize yourself with all the right techniques. Do this so you are able to make the most use of the latest advances. Also, subscribe to our DataFramed podcast. We even have an episode with Jean-Francois Puget, Distinguished Engineer at NVIDIA & Chris Deotte, Senior Data Scientist at NVIDIA, who discuss, among other things, the impact of GPU acceleration.
Learn Python and scikit-Learn with DataCamp
Track
Course
Course
blog
Richie Cotton
8 min
blog
Thalia Barrera
11 min
podcast
Tutorial
Arunn Thevapalan
Tutorial
Avinash Navlani
code-along
George Boorman



