
Cursus
Chercheur en apprentissage automatique en Python
85 h
cuML de NVIDIA est une bibliothèque d'apprentissage automatique accélérée par le GPU qui fait partie de l'écosystème RAPIDS AI. Et maintenant, en bêta ouverte, cuML 25.02 permet d'avoir l'accélération GPU dans scikit-learn, UMAP, et HDBSCAN sans changer votre code Python. Cela va s'avérer une nouvelle très intéressante pour les ingénieurs en apprentissage automatique de Python, les scientifiques des données et de la recherche, les développeurs, et tant d'autres professionnels qui attendent avec impatience de voir une augmentation de la performance de leurs modèles.
Ne vous inquiétez pas si vous n'êtes pas familier avec cuML ou même avec l'idée de l'accélération GPU. Je vais vous faire visiter et, à la fin de cet article, vous serez en mesure d'utiliser l'accélération GPU pour vos problèmes de régression, de classification, de réduction de la dimensionnalité ou de clustering.
Prenons quelques instants pour mettre toutes les pièces en place.
NVIDIA développe des technologies de pointe qui alimentent l'informatique haute performance, l'IA et la science des données. Vous vous souvenez peut-être qu'ils ont fait couler beaucoup d'encre lorsque Deepseek a abandonné Deepseek-R1 et que les gens ont demandé si Deepseek utilisait des puces NVIDIA.
NVIDIA fait à nouveau parler d'elle, cette fois pour les innovations de son écosystème d'IA RAPIDS. Si vous ne connaissez pas RAPIDS AI, il s'agit d'une suite open-source de bibliothèques accélérées par le GPU et conçues pour accélérer les flux de travail de la science des données et de l'apprentissage automatique. RAPIDS repose sur CUDA (Compute Unified Device Architecture), une plateforme de calcul parallèle et un modèle d'API également développés par NVIDIA. Les bibliothèques RAPIDS accélérées par le GPU sont les suivantes :
A propos de cuML : cuML fournit des implémentations hautement optimisées d'algorithmes classiques d'apprentissage automatique. Comme NVIDIA possède les meilleures puces d'IA, ces algorithmes, qui tournent sur les GPU NVIDIA, bénéficient d'une accélération significative. Les GPU, contrairement aux CPU, excellent dans le traitement parallèle, ce qui signifie en pratique qu'ils peuvent traiter des milliers de calculs en même temps, ce qui les rend idéaux pour des tâches telles que (vous l'avez deviné) l'apprentissage en profondeur et l'apprentissage automatique.
Si vous ne connaissez pas scikit-learn et que vous vous intéressez sérieusement à l'apprentissage automatique et à la science des données, vous devriez absolument vous inscrire à notre cours Apprentissage supervisé avec scikit-learn. Je dis cela parce que scikit-learn est la bibliothèque numéro un pour les données tabulaires dans le langage de programmation le plus populaire pour l'apprentissage automatique. De plus, scikit-learn est assez facile à apprendre et possède une API simple. Il fonctionne également bien avec pandas et NumPy. Il n'est donc pas surprenant que l'équipe RAPIDS AI se concentre sur les algorithmes scikit-learn en tant que choix stratégique et naturel.
NVIDIA et cuML offrent désormais à scikit-learn, ainsi qu'à UMAP et HDBSCAN, la grande nouveauté d'une augmentation massive de la vitesse de performance. Selon l'équipe RAPIDS AI, cela signifie une vitesse jusqu'à 50x pour scikit-learn, 60x pour UMAP et 175x pour HDBSCAN.
D'après mes calculs, un algorithme qui prendrait cinq minutes à exécuter sur scikit-learn pourrait théoriquement être réduit à six secondes. C'est une grande différence. Je m'attarderai un peu plus sur ce point lors de l'examen des benchmarks ci-dessous.
Si tout cela vous semble complexe, ne vous inquiétez pas. RAPIDS AI s'engage à ne pas modifier le code de l'API de scikit-learn. En réalité, il vous suffit de charger l'extension, comme suit :
%load_ext cuml.accel
$ python -m cuml.accel script.pyIl ne s'agit pas d'un changement majeur par rapport au flux de travail auquel vous êtes habitué, ce qui est l'idée même. Il peut arriver que vous deviez redémarrer le noyau et charger à nouveau l'extension.
Cet aspect "zéro changement de code" est en fait, à mon avis, à première vue, une revendication très intéressante. L'idée ici est que vous n'ayez pas à modifier vos scripts scikit-learn déjà créés - pas la première fois, mais jamais non plus. cuML accélère automatiquement les composants compatibles sur les GPU NVIDIA, mais s'il se passe quelque chose dans votre code qui n'est pas compatible avec les GPU NVIDIA, votre script reviendra à l'exécution CPU "normale". En tant que codeur, vous ne verrez que le résultat et vous n'aurez pas à vous préoccuper de la gestion des erreurs ou de quoi que ce soit d'autre.
Cela dit, je m'attends toujours à ce que présente des cas particuliers pouvant nécessiter des ajustements. Dans le domaine du codage, les choses peuvent mal tourner et rien n'est jamais aussi simple qu'il n'y paraît. La documentation de référence contient certains éléments qui démentent presque l'affirmation selon laquelle il n'y a pas de changement de code, ou du moins qui ajoutent un peu de friction à cette affirmation. Vous devez convertir les listes en tableaux NumPY ou en DataFrame Pandas, et les étiquettes en chaîne ne sont pas prises en charge, de sorte que les utilisateurs doivent pré-encoder les étiquettes catégorielles. Il se peut que vous fassiez ces choses de toute façon, mais le fait est qu'il y a d'autres choses auxquelles vous devez vous habituer en plus du simple chargement de l'extension.
Si vous vous entraîniez aux statistiques de base en effectuant une simple régression linéaire sur le jeu de données mtcars, il ne serait pas très utile d'utiliser l'accélération GPU pour trouver la pente et l'ordonnée à l'origine de la ligne un tout petit peu plus rapidement. L'économie de quelques fractions de seconde ne vaudrait même pas la peine de charger l'extension. Mais si vous exécutez un algorithme plus complexe, le temps gagné est vraiment important pour deux raisons principales.
Tout d'abord, le temps que vous gagnez est considérable pour de nombreux flux de travail. J'ai mentionné qu'une augmentation de la vitesse de 50 fois se traduirait, hypothétiquement, par la réduction d'un temps d'entraînement de cinq minutes à six secondes. Cela représente un gain de près de cinq minutes. Mais considérez le flux de travail de l'ingénieur en apprentissage automatique, où le modèle peut devoir être exécuté plusieurs fois avant d'être parfait. En somme, parler de gain de temps à chaque exécution revient à parler de la productivité globale d'un scientifique des données.
Deuxièmement, et dans le même ordre d'idées, le scientifique ou l'ingénieur peut maintenant commencer à essayer d'élaborer des modèles plus complexes. Dans l'exemple précédent, nous supposons que la vitesse d'un modèle permet d'obtenir le même niveau de précision. Mais que se passerait-il si vous pensiez qu'un modèle plus complexe vous apporterait une plus grande précision ? Imaginez que vous fassiez une recherche en grille de différents paramètres de modèle et que vous entraîniez un modèle. (Je vais essayer mon propre mini exemple, ci-dessous). Les permutations augmentent de façon exponentielle, ce qui rend le coût de calcul prohibitif pour une unité centrale. Mais ce n'est pas un problème si votre vitesse est multipliée par 50.
Ces avantages vont de pair. Si vous configurez correctement votre projet, vous pouvez obtenir un modèle plus précis qui est également produit plus rapidement ou, comme un ingénieur en apprentissage automatique pourrait le penser, vous pouvez avoir une architecture de modèle plus sophistiquée sans temps d'apprentissage excessif.
NVIDIA s'efforce d'expliquer comment les GPU donneraient des résultats numériquement équivalents. C'est une bonne nouvelle, car cela signifie que les avantages ne s'accompagnent pas d'inconvénients en termes de précision du modèle.
Mais cela m'a aussi fait réfléchir : Pourquoi les résultats sont-ils numériquement équivalents et non identiques ? Il est probable qu'en raison du traitement parallèle, il y ait de petites différences dans le résultat ou dans la stabilité numérique d'une méthode donnée. Peut-être que dans le cas de l'UMAP, la projection de l'UMAP est légèrement différente. J'en parle au cas où vous constateriez des différences subtiles dans les résultats entre l'exécution par le CPU et par le GPU. NVIDIA semble suggérer que vous devez vous attendre à ce que cela se produise, et que c'est normal.
Cela dit, si vous vous lancez un véritable défi et que vous exécutez un modèle sur des GPU parce que le modèle est suffisamment complexe pour que les CPU ne fonctionnent pas en pratique, il devient alors difficile de comparer les résultats de ce modèle à un équivalent CPU.
J'ai mentionné plus haut que la version 25.02 de cuML supporte désormais scikit-learn, UMAP et HDBSCAN. Mais si vous êtes familier avec scikit-learn, vous savez qu'il existe de nombreux algorithmes différents dans scikit-learn. Actuellement, RAPIDS AI prend en charge certaines de ces bibliothèques, mais pas toutes. Voici les principales mentions, selon l'équipe :
Dans cette liste, je serais plus enthousiaste à l'idée d'une accélération de la vitesse des k-voisins les plus proches, qui sont connus pour leur forte intensité de calcul, car vous devez calculer les distances entre tous les points de données.
Le tableau suivant vous montre les estimateurs qui sont principalement ou entièrement exécutés avec cuML.
| Algorithme | Bibliothèque / Nom de la fonction | Catégorie |
|---|---|---|
| UMAP | umap.UMAP |
Réduction de la dimensionnalité |
| ACP (analyse en composantes principales) | sklearn.decomposition.PCA |
Réduction de la dimensionnalité |
| SVD tronquée | sklearn.decomposition.TruncatedSVD |
Réduction de la dimensionnalité |
| t-SNE | sklearn.manifold.TSNE |
Réduction de la dimensionnalité |
| HDBSCAN | hdbscan.HDBSCAN |
Regroupement |
| K-Means | sklearn.cluster.KMeans |
Regroupement |
| DBSCAN | sklearn.cluster.DBSCAN |
Regroupement |
| Classificateur de forêt aléatoire | sklearn.ensemble.RandomForestClassifier |
Classification |
| Régression logistique | sklearn.linear_model.LogisticRegression |
Classification |
| Classificateur des plus proches voisins (K-Nearest Neighbors) | sklearn.neighbors.KNeighborsClassifier |
Classification |
| Régresseur Random Forest | sklearn.ensemble.RandomForestRegressor |
Régression |
| Régression linéaire | sklearn.linear_model.LinearRegression |
Régression |
| Filet élastique | sklearn.linear_model.ElasticNet |
Régression |
| Régression de la crête | sklearn.linear_model.Ridge |
Régression |
| Régression Lasso | sklearn.linear_model.Lasso |
Régression |
| Régression de Kernel Ridge | sklearn.kernel_ridge.KernelRidge |
Régression |
| K-Voisins les plus proches Régresseur | sklearn.neighbors.KNeighborsRegressor |
Régression |
| Recherche des plus proches voisins | sklearn.neighbors.NearestNeighbors |
Recherche des plus proches voisins |
Une liste complète des méthodes prises en charge est disponible dans la documentation de RAPIDS AI. D'autres algorithmes devraient être ajoutés prochainement. (Vous pouvez également donner votre avis pour aider l'équipe à établir des priorités). Parmi ceux dont j'ai remarqué l'absence, citons le régresseur à vecteur de support (sklearn.svm.SVR), le régresseur Theil-Sen (sklearn.linear_model.TheilSenRegressor), le regroupement par déplacement de la moyenne (sklearn.cluster.MeanShift) et la mise à l'échelle multidimensionnelle (sklearn.manifold.MDS).
Vous vous demandez peut-être comment tout cela fonctionne. À 30 000 pieds d'altitude, sachez que, de plus en plus, les bibliothèques modernes sont conçues pour détecter et utiliser automatiquement le meilleur matériel disponible, qu'il s'agisse d'un processeur ou d'un processeur graphique (GPU). Nous constatons aujourd'hui que, lorsqu'une fonction est appelée dans scikit-learn (lorsque cuml.accel est activé), le logiciel vérifie si un GPU compatible est disponible et redirige l'exécution vers une version accélérée par le GPU si c'est le cas.
RAPIDS AI parle de ce mécanisme qui permet à cuml.accel d'agir comme Sklearn en tant que couche de compatibilité. Dans ce cas, la couche de compatibilité de cuML permet au code scikit-learn de fonctionner sur les GPU NVIDIA sans modification. Il est construit comme un remplacement direct et agit comme un proxy qui intercepte les appels de fonction à scikit-learn et les redirige vers cuML.
L'équipe RAPIDS AI de NVIDIA partage un graphique utile que je vais également partager ici :
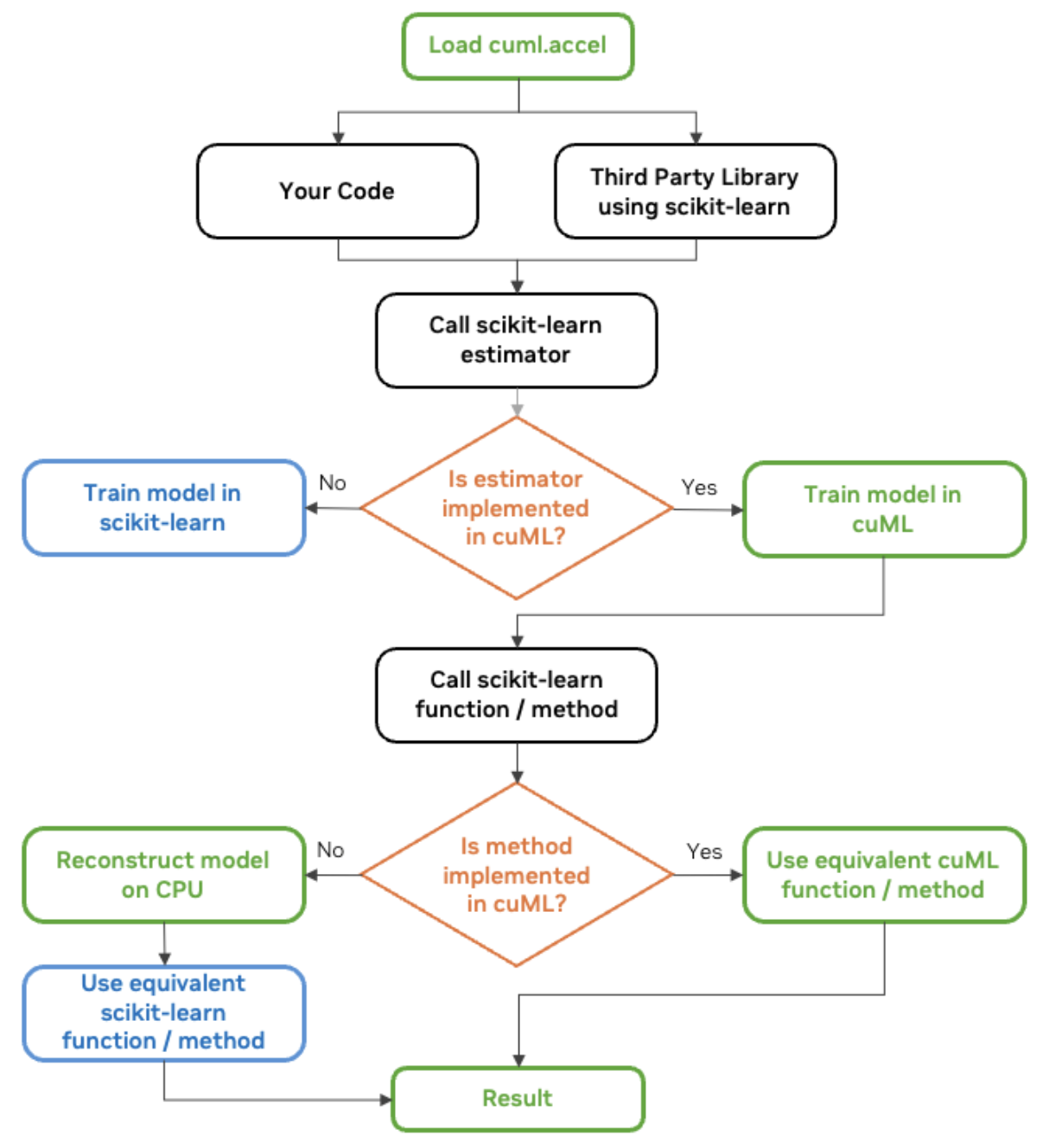
Diagramme de flux de travail cuML scikit-learn. Source : NVIDIA
cuML est déjà pré-installé dans Google Colab, mais si vous utilisez un notebook Jupyter, activez-le avec cette commande avant d'importer scikit-learn :
%load_ext cuml.accel
import sklearnMaintenant, notre code Python utilisant sklearn va vous sembler familier, ce qui est tout l'intérêt. Voici un exemple de régression par les MCO.
# Import necessary libraries
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# Generate synthetic regression data
X, y = make_regression(n_samples=500000, n_features=50, noise=0.1, random_state=0)
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Create and train an OLS regression model
ols = LinearRegression()
ols.fit(X_train, y_train)Si je veux voir quelles parties ont été exécutées sur le GPU plutôt que sur le CPU, je peux utiliser logger.
%load_ext cuml.accel
from cuml.common import logger;
logger.set_level(logger.level_enum.debug)cuML: Installed accelerator for sklearn.
cuML: Successfully initialized accelerator.
cuML: Performing fit in GPUVous l'aurez compris. Essayons maintenant un exemple plus convaincant. De toute façon, la régression linéaire n'est pas particulièrement parallélisable, puisque la résolution de l'équation équation normale ou de la décomposition QR implique des opérations séquentielles.
Une extension plus complexe de la régression par les MCO est la régression par crête. Lorsque vous utilisez la régression ridge en Python, l'appel à Ridge() applique des hyperparamètres par défaut, qui peuvent ne pas être optimaux. La valeur alpha détermine le degré de régularisation appliqué. Si le modèle est trop petit, il est trop grand ; s'il est trop grand, il n'est pas assez grand.
%load_ext cuml.accel
import sklearn
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate synthetic data
X, y = make_regression(n_samples=100000, n_features=50, noise=0.1, random_state=0)
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Train a Ridge Regression model with default settings
ridge_default = Ridge()
ridge_default.fit(X_train, y_train)
# Make predictions and evaluate
y_pred_default = ridge_default.predict(X_test)
mse_default = mean_squared_error(y_test, y_pred_default)
Le code ci-dessus entraîne un modèle, en utilisant une seule valeur alpha et un seul solveur. (Je crois que la valeur par défaut est 'auto'.) Ainsi, bien que cette méthode fonctionne, elle n'optimise pas la force de régularisation ou le choix du solveur.
Au lieu de s'appuyer sur les valeurs par défaut, nous pourrions essayer quelque chose d'autre. Nous pourrions créer une grille de recherche qui testerait plusieurs combinaisons d'hyperparamètres et sélectionnerait la meilleure.
from sklearn.model_selection import GridSearchCV
# Define Ridge Regression model
ridge = Ridge()
# Define a grid of hyperparameters to search
param_grid = {
'alpha': [0.01, 0.1, 1.0, 10.0, 100.0], # Different regularization strengths
'solver': ['auto', 'svd', 'cholesky', 'lsqr', 'saga'] # Test multiple solvers
}
# Perform Grid Search with cross-validation
grid_search = GridSearchCV(ridge, param_grid, scoring='neg_mean_squared_error', cv=2, n_jobs=-1)
grid_search.fit(X_train, y_train)
# Get the best model from the search
best_ridge = grid_search.best_estimator_
# Make predictions and evaluate
y_pred_best = best_ridge.predict(X_test)
mse_best = mean_squared_error(y_test, y_pred_best)
Notre recherche sur la grille teste ici toutes les combinaisons possibles d'hyperparamètres. Si nous définissons 5 valeurs pour alpha ([0.01, 0.1, 1.0, 10.0, 100.0]), 5 options de résolution (['auto', 'svd', 'cholesky', 'lsqr', 'saga']) et que nous utilisons la validation croisée à deux niveaux, le nombre total d'entraînements de modèles requis est de 5x5x2, soit 50. Cela signifie qu'au lieu de former un modèle, nous en formons 50. C'est beaucoup, beaucoup plus complexe, et c'est pourquoi les GPU seront si utiles, car ils sont beaucoup, beaucoup plus rapides. La vitesse de sklearn pouvant être multipliée par 50, l'apprentissage de ces 50 modèles peut prendre le même temps que l'apprentissage d'un seul modèle. (J'ai choisi ces chiffres à dessein pour illustrer ce point. Je reconnais que tous les modèles n'auront pas la même augmentation de vitesse).
NVIDIA a comparé les performances des algorithmes scikit-learn exécutés sur des CPU Intel à celles de ses propres GPU NVIDIA. Ils ont examiné différentes charges de travail d'apprentissage automatique, notamment la classification et la régression.
Il en ressort que les modèles simples tels que les forêts aléatoires sont passés de quelques minutes de temps d'entraînement sur les CPU à quelques secondes sur les GPU, et que les modèles plus complexes tels que le clustering sont passés de quelques heures de temps d'entraînement à quelques minutes. Les flux de travail étaient plus rapides dans tous les cas, mais pour les modèles lourds en calcul avec des données de haute dimension, les avantages étaient encore plus clairs. Test là que les GPU brillent parce qu'ils utilisent le traitement parallèle et que l'on sait que cela fait une énorme différence dans les modèles qui nécessitent des opérations matricielles importantes, des calculs de distance ou une optimisation qui est effectuée de manière itérative.
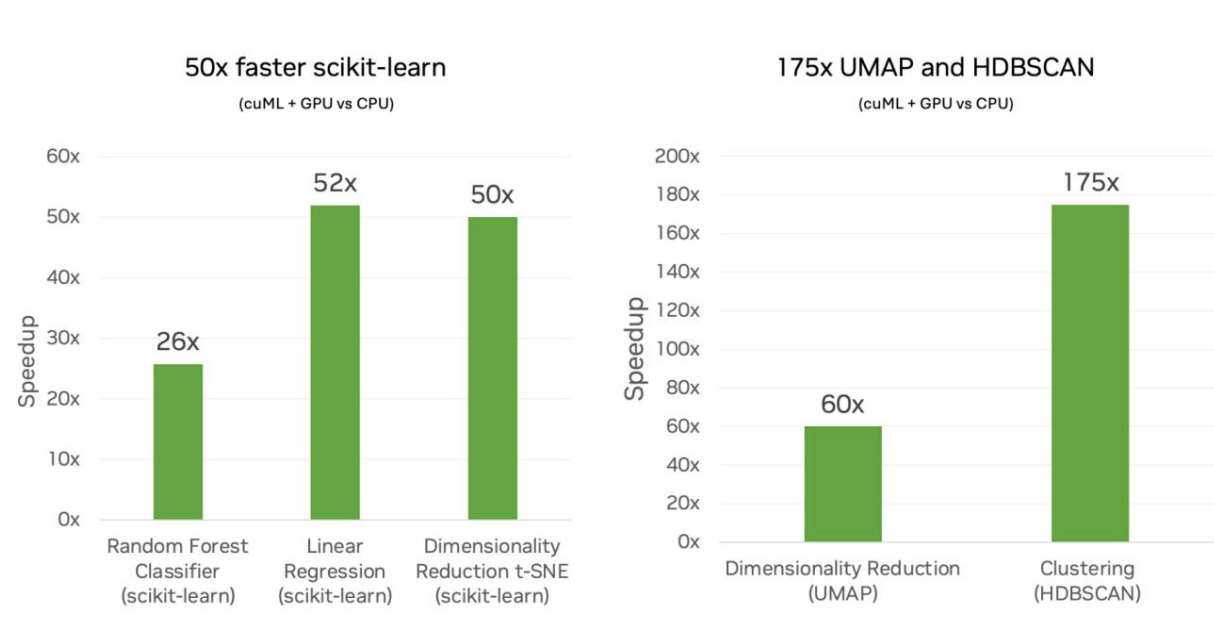
cuML scikit-learn sur GPU vs scikit-learn sur CPU. Source : NVIDIA
Je me suis éloigné de la régression linéaire dans l'exemple de codage précédent parce que j'ai pensé qu'il fallait essayer autre chose pour montrer la puissance. Mais ici, je constate une accélération de 52x pour la régression linéaire. J'avoue que je suis surpris parce que cela semble être un grand multiple. C'est un bon rappel que NVIDIA fait aussi d'autres choses avancées, comme s'assurer que différentes étapes peuvent être entrelacées pour que le GPU ne soit pas inactif.
Grâce à cuML version 25.02, l'exécution d'un algorithme scitkit-learn avec des GPU n'est plus trop difficile. Il vous suffit de charger l'extension, comme je l'ai montré précédemment. Cependant, si vous êtes plus loin dans le flux de travail et que vous souhaitez tirer le meilleur parti de l'accélération GPU, vous devrez prendre en compte des éléments très spécifiques.
NVIDIA recommande de minimiser les transferts de données entre les CPU et les GPU dans le cadre de votre pipeline. En d'autres termes, effectuez les étapes de prétraitement, d'entraînement et d'inférence dans les GPU avant de renvoyer les résultats dans la mémoire de l'hôte. Ne mélangez pas les étapes en effectuant le prétraitement dans les CPU et l'inférence dans les GPU.
En outre, pour maximiser l'efficacité, vous devriez envisager CUDA-X, qui est une collection de bibliothèques accélérées par le GPU et développées par NVIDIA. Pour les forêts aléatoires, vous pouvez utiliser la bibliothèque d'inférence forestière de cuML, par exemple, au lieu de celle de scikit-learn.
Le travail de l'équipe RAPIDS AI est complexe, il y aura donc des problèmes. Heureusement, la documentation relative aux limitations connues est bien conservée. Je ne souhaite pas nécessairement inclure toutes les limitations, ni même certaines d'entre elles, dans le présent document, car de nombreux problèmes sont liés à des algorithmes spécifiques. De plus, les mises à jour ou les correctifs sont rapides. Je vais plutôt vous donner les catégories les plus générales de choses à prendre en considération.
Certaines restrictions s'appliquent à l'ensemble de cuML, et pas seulement à des algorithmes spécifiques. Les exemples ici semblent inclure des restrictions sur les formats d'entrée des données (certains problèmes avec les listes Python), la compatibilité des versions et la gestion de la mémoire.
Certains algorithmes d'apprentissage automatique sont soumis à des contraintes particulières. Ces différences peuvent affecter la formation des modèles, le comportement des paramètres ou le calcul des résultats. Par exemple, l'algorithme de forêt aléatoire dans cuML utilise une méthode différente pour choisir les seuils de séparation, ce qui conduit à des structures d'arbre légèrement différentes.
Il existe quelques différences au niveau des paramètres, des solveurs et des méthodes d'initialisation qui sont pris en charge. Par exemple, l'ACP prend en charge les solveurs SVD "complets" et "automatiques", mais pas les solveurs "aléatoires". Et KNN prend en charge les métriques de Minkowski, mais pas celles de Mahalanobis.
Il peut arriver que les résultats diffèrent légèrement en raison de différences de parallélisme ou de solveur. Je l'ai déjà mentionné. Par exemple, les encastrements UMAP peuvent ne pas être identiques, mais le score de fiabilité doit rester élevé. Dans d'autres cas, les signes des composantes de l'ACP peuvent s'inverser, ce qui nécessite une normalisation. Encore une fois, il s'agit d'une chose spécifique, et vous devez vous référer à la documentation la plus récente lorsque vous exécutez un algorithme spécifique.
Je suis enthousiasmé par la perspective d'une accélération GPU super facile à utiliser pour les algorithmes bien connus des bibliothèques d'apprentissage automatique Python les plus courantes. Cela va faire une grande différence dans la précision du modèle, et c'est pratique et facile à mettre en œuvre.
Restez au courant des dernières nouveautés en matière d'apprentissage automatique. Suivez notre cursus professionnel de scientifique en apprentissage automatique en Python pour vous familiariser avec toutes les bonnes techniques. Vous pourrez ainsi tirer le meilleur parti des dernières avancées. Abonnez-vous également à notre podcast DataFrame. Nous avons même un épisode avec Jean-François Puget, Distinguished Engineer chez NVIDIA et Chris Deotte, Senior Data Scientist chez NVIDIA, qui discutent, entre autres, de l'impact de l'accélération GPU.
Apprenez Python et scikit-Learn avec DataCamp
Cursus
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
Tutoriel
DataCamp Team
Tutoriel
Stephen Gruppetta
Tutoriel
Matt Crabtree