
Programa
Cientista de machine learning em Python
85 h
O cuML da NVIDIA é uma biblioteca de machine learning acelerada por GPU que faz parte do ecossistema RAPIDS AI. E agora, em versão beta aberta, o cuML 25.02 possibilita que você tenha aceleração de GPU no scikit-learn, UMAP e HDBSCAN sem alterar seu código Python. Essa será uma notícia muito interessante para engenheiros de machine learning Python, cientistas de dados e de pesquisa, desenvolvedores e muitos outros profissionais que esperam ver um aumento no desempenho de seus modelos.
Não se preocupe se você não estiver familiarizado com o cuML ou mesmo com a ideia de aceleração de GPU. Farei um tour e, ao final deste artigo, você poderá usar a aceleração de GPU para seus problemas de regressão, classificação, redução de dimensionalidade ou clustering.
Vamos parar um pouco para colocar todas as peças no lugar certo.
A NVIDIA desenvolve tecnologias de ponta que potencializam a computação de alto desempenho, a IA e a ciência de dados. Você deve se lembrar que eles foram muito noticiados quando a Deepseek abandonou o Deepseek-R1 e as pessoas perguntaram se a Deepseek usava chips NVIDIA.
Bem, a NVIDIA está nas notícias novamente, desta vez pelas inovações em seu ecossistema de IA RAPIDS. O RAPIDS AI, se você não conhece, é um conjunto de código aberto de bibliotecas aceleradas por GPU projetado para acelerar a ciência de dados e os fluxos de trabalho de machine learning. O RAPIDS foi desenvolvido com base na CUDA (Compute Unified Device Architecture), que é uma plataforma de computação paralela e um modelo de API, também desenvolvido pela NVIDIA. As bibliotecas aceleradas por GPU do RAPIDS incluem:
Agora, sobre o cuML: o cuML fornece implementações altamente otimizadas de algoritmos clássicos de machine learning. Como a NVIDIA tem os melhores chips de IA, esses algoritmos, que são executados em GPUs NVIDIA, têm um aumento significativo de velocidade. As GPUs, ao contrário das CPUs, são excelentes em processamento paralelo, o que praticamente significa que elas podem lidar com milhares de cálculos ao mesmo tempo, tornando-as ideais para tarefas como (você adivinhou) aprendizagem profunda e machine learning.
Se você não está familiarizado com o scikit-learn e leva a sério o machine learning e a ciência de dados, com certeza deve se inscrever em nosso curso Aprendizado supervisionado com o scikit-learn. Estou dizendo isso porque o scikit-learn é a biblioteca número um para dados tabulares na linguagem de programação número um mais popular para machine learning. Além disso, o scikit-learn é bastante fácil de aprender, tem uma API simples e também funciona bem com o pandas e o NumPy. Portanto, não é de surpreender que a equipe de IA do RAPIDS esteja se concentrando nos algoritmos do scikit-learn como uma escolha estratégica e natural.
A NVIDIA e o cuML agora oferecem a grande inovação para o scikit-learn e também para o UMAP e o HDBSCAN, com um grande aumento na velocidade de desempenho. De acordo com a equipe de IA do RAPIDS, isso significa uma velocidade de até 50 vezes ao usar o scikit-learn, 60 vezes para o UMAP e 175 vezes para o HDBSCAN.
Minha matemática de bastidores me diz que um algoritmo que pode levar cinco minutos para ser executado no scikit-learn poderia, teoricamente, ser reduzido para apenas seis segundos. Essa é uma grande diferença. Vou falar um pouco mais sobre isso quando analisar os benchmarks abaixo.
Se tudo isso parecer complexo, não se preocupe. O RAPIDS AI está comprometido com zero alterações de código necessárias ao código da API do scikit-learn. Na verdade, você só precisa carregar a extensão, assim:
%load_ext cuml.accel
$ python -m cuml.accel script.pyEssa não é uma mudança tão grande no fluxo de trabalho com o qual você está acostumado, que é a ideia principal. Ocasionalmente, talvez você precise reiniciar o kernel e carregar a extensão novamente.
Esse aspecto de mudança de código zero é, na verdade, na minha opinião, à primeira vista, uma afirmação realmente empolgante. A ideia aqui é que você não precise alterar seus scripts scikit-learn já criados - nem na primeira vez, mas também nunca. O cuML aceleraria automaticamente os componentes compatíveis com nas GPUs NVIDIA, mas se houver algo acontecendo no seu código que não seja compatível com as GPUs NVIDIA, seu script voltará à execução "normal" da CPU. Você, como programador, verá apenas o resultado e não precisará se preocupar com o tratamento de erros ou qualquer outra coisa.
Dito isso, eu ainda esperaria casos extremos que podem exigir ajustes. Na codificação, as coisas podem dar errado, e nada é tão fácil quanto parece. A documentação de referência tem alguns aspectos que quase desmentem a afirmação de que "não há alterações no código" ou, pelo menos, adicionam um pouco de atrito a ela. Você precisa converter as listas em arrays NumPY ou DataFrames Pandas, e os rótulos de string não são suportados, portanto, os usuários precisam pré-codificar os rótulos categóricos. Você pode fazer isso de qualquer maneira, mas a questão é que há outras coisas com as quais você também precisa se acostumar, além de apenas carregar a extensão.
Se você estivesse praticando estatísticas básicas executando uma regressão linear simples no conjunto de dados mtcars, não haveria muita utilidade em usar a aceleração da GPU para encontrar a inclinação e a interceptação da linha um pouquinho mais rápido. Na verdade, economizar frações de segundo nem valeria a pena carregar a extensão. Mas se, em vez disso, você estivesse executando um algoritmo mais complexo, o tempo economizado seria realmente importante por dois motivos principais.
Por um lado, o tempo que você economiza é significativo para muitos fluxos de trabalho. Mencionei que um aumento de velocidade de até 50 vezes se traduziria, hipoteticamente, na redução de um tempo de treinamento de cinco minutos para seis segundos. Isso representa uma economia de quase cinco minutos. Mas considere o fluxo de trabalho do engenheiro de machine learning, em que o modelo pode exigir que você o execute algumas vezes para acertar. Somado a isso, falar sobre economia de tempo em cada execução é falar sobre a produtividade geral de um cientista de dados.
Em segundo lugar, e relacionado a isso, o cientista ou engenheiro pode agora começar a tentar modelos mais complexos. No exemplo anterior, estamos supondo uma velocidade de tempo para um modelo que produz o mesmo nível de precisão. Mas e se você achasse que realmente teria maior precisão com um modelo mais complexo? Imagine fazer uma pesquisa em grade de diferentes parâmetros de modelo e treinar um modelo. (Vou tentar meu próprio mini exemplo, abaixo). As permutações crescem exponencialmente, tornando o custo computacional proibitivo em uma CPU. Mas isso não é um problema se você tiver um aumento de 50 vezes na velocidade.
Esses benefícios andam juntos. Se você configurar seu projeto corretamente, poderá ter um modelo mais preciso que também será produzido mais rapidamente ou, como um engenheiro de machine learning poderia pensar, você poderia ter uma arquitetura de modelo mais sofisticada sem tempos de treinamento excessivos.
A NVIDIA se esforça para falar sobre como as GPUs revelariam resultados numericamente equivalentes. É bom ouvir isso, pois significa que os benefícios não vêm com desvantagens em termos de precisão do modelo.
Mas isso também me fez pensar: Por que os resultados são numericamente equivalentes e não os mesmos? Bem, provavelmente, como resultado do processamento paralelo, há algumas pequenas diferenças no resultado, ou há algumas diferenças na estabilidade numérica de um determinado método. Talvez no caso da UMAP a projeção da UMAP seja ligeiramente diferente. Estou mencionando isso para o caso de você perceber diferenças sutis na saída entre a execução da CPU e da GPU. A NVIDIA parece sugerir que você deve esperar ver um pouco disso, e que isso é normal.
Dito isso, se você estiver realmente se desafiando e executar um modelo em GPUs porque o modelo é complexo o suficiente para que as CPUs não funcionem na prática, será difícil comparar o resultado desse modelo com um equivalente em CPU.
Mencionei anteriormente que agora há suporte nesta versão 25.02 do cuML para scikit-learn, UMAP e HDBSCAN. Mas se você estiver familiarizado com o scikit-learn, saberá que há muitos algoritmos diferentes no scikit-learn. Atualmente, o RAPIDS AI oferece suporte a algumas bibliotecas, mas não a todas elas. Aqui estão os principais destaques, de acordo com a equipe:
Nessa lista, eu ficaria mais animado com um aumento de velocidade no k-Nearest Neighbors, que é conhecido por ser altamente intensivo em termos de computação porque você precisa calcular as distâncias entre todos os pontos de dados.
A tabela a seguir mostra a você os estimadores que são executados, em sua maioria ou totalmente, com o cuML.
| Algoritmo | Nome da biblioteca/função | Categoria |
|---|---|---|
| UMAP | umap.UMAP |
Redução de dimensionalidade |
| PCA (Análise de Componentes Principais) | sklearn.decomposition.PCA |
Redução de dimensionalidade |
| SVD truncado | sklearn.decomposition.TruncatedSVD |
Redução de dimensionalidade |
| t-SNE | sklearn.manifold.TSNE |
Redução de dimensionalidade |
| HDBSCAN | hdbscan.HDBSCAN |
Agrupamento |
| K-Means | sklearn.cluster.KMeans |
Agrupamento |
| DBSCAN | sklearn.cluster.DBSCAN |
Agrupamento |
| Classificador Random Forest | sklearn.ensemble.RandomForestClassifier |
Classificação |
| Regressão logística | sklearn.linear_model.LogisticRegression |
Classificação |
| Classificador K-Nearest Neighbors | sklearn.neighbors.KNeighborsClassifier |
Classificação |
| Regressor de floresta aleatória | sklearn.ensemble.RandomForestRegressor |
Regressão |
| Regressão linear | sklearn.linear_model.LinearRegression |
Regressão |
| Rede elástica | sklearn.linear_model.ElasticNet |
Regressão |
| Regressão Ridge | sklearn.linear_model.Ridge |
Regressão |
| Regressão Lasso | sklearn.linear_model.Lasso |
Regressão |
| Regressão Kernel Ridge | sklearn.kernel_ridge.KernelRidge |
Regressão |
| Regressor K-Nearest Neighbors | sklearn.neighbors.KNeighborsRegressor |
Regressão |
| Pesquisa de vizinhos mais próximos | sklearn.neighbors.NearestNeighbors |
Pesquisa de vizinhos mais próximos |
Uma lista completa dos métodos compatíveis está disponível na documentação do RAPIDS AI. Esperamos que mais algoritmos sejam adicionados em breve. (Você também pode fornecer algum feedback para ajudar a equipe a priorizar). Alguns dos que notei estarem faltando: regressor de vetor de suporte (sklearn.svm.SVR), regressor Theil-Sen (sklearn.linear_model.TheilSenRegressor), agrupamento de deslocamento médio (sklearn.cluster.MeanShift) e escalonamento multidimensional (sklearn.manifold.MDS).
Você deve estar se perguntando como tudo isso funciona. A 30k pés de distância, saiba que, cada vez mais, as bibliotecas modernas estão sendo projetadas para detectar e usar automaticamente o melhor hardware disponível, seja uma CPU ou uma GPU. Estamos vendo agora que, quando uma função é chamada no scikit-learn (quando cuml.accel está ativado), o software verifica se uma GPU compatível está disponível e redireciona a execução para uma versão acelerada por GPU, se estiver.
O RAPIDS AI fala sobre esse mecanismo para fazer com que o cuml.accel funcione como o sklearn como uma camada de compatibilidade. Nesse caso, a camada de compatibilidade do cuML permite que o código do scikit-learn seja executado em GPUs NVIDIA sem alterações. Ele foi criado como um substituto imediato e atua como um proxy, interceptando chamadas de função para o scikit-learn e redirecionando-as para o cuML.
A equipe de IA RAPIDS da NVIDIA compartilha um gráfico útil que eu também compartilharei aqui:
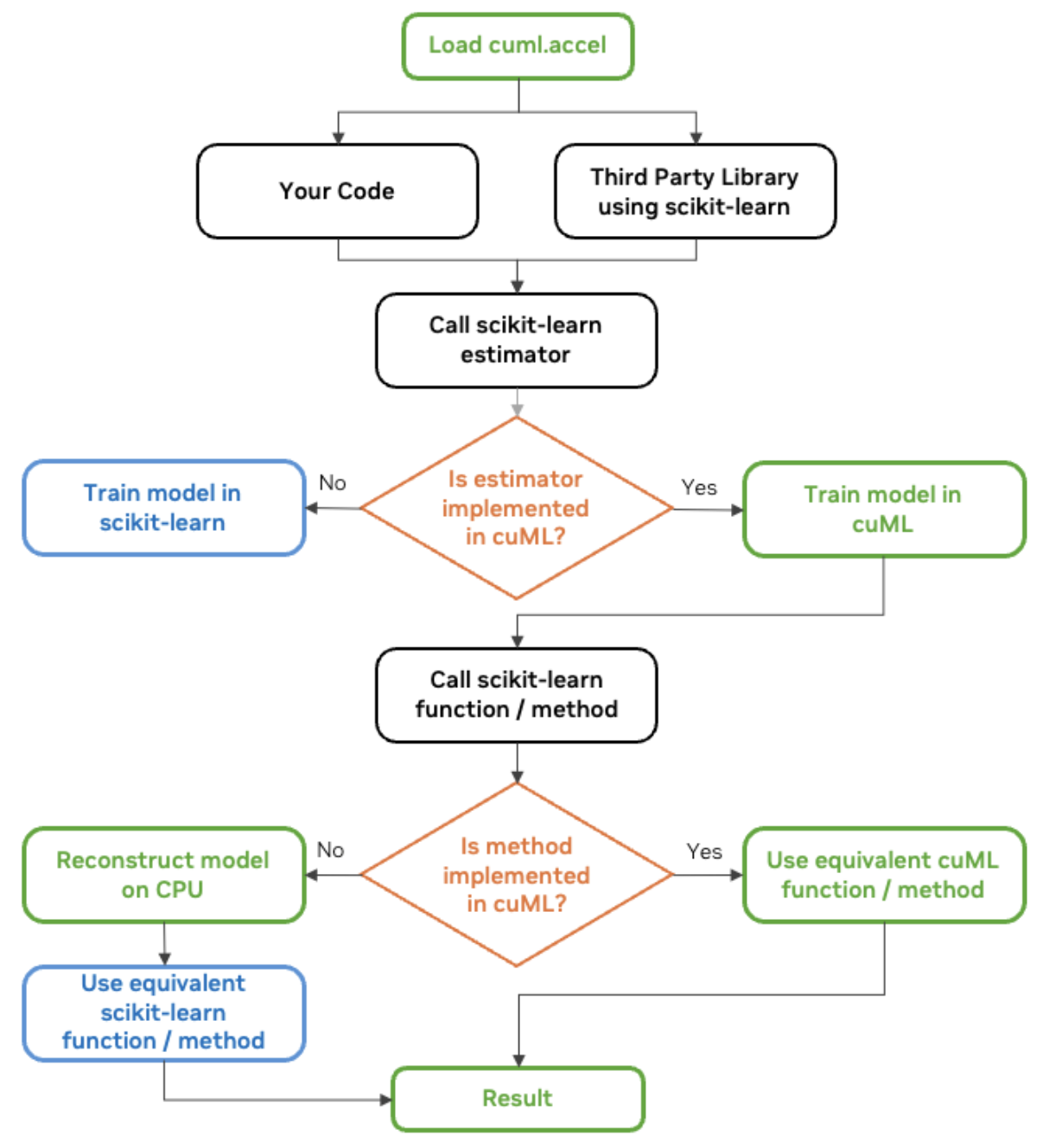
Diagrama de fluxo de trabalho do cuML scikit-learn. Fonte: NVIDIA
O cuML já vem pré-instalado no Google Colab, mas se você estiver usando um notebook Jupyter, ative-o com este comando antes de importar o scikit-learn:
%load_ext cuml.accel
import sklearnAgora, nosso código Python usando o sklearn parecerá familiar, e esse é o objetivo. Aqui está um exemplo de uma regressão OLS.
# Import necessary libraries
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# Generate synthetic regression data
X, y = make_regression(n_samples=500000, n_features=50, noise=0.1, random_state=0)
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Create and train an OLS regression model
ols = LinearRegression()
ols.fit(X_train, y_train)Se eu quiser ver quais partes foram executadas na GPU em vez da CPU, posso usar logger.
%load_ext cuml.accel
from cuml.common import logger;
logger.set_level(logger.level_enum.debug)cuML: Installed accelerator for sklearn.
cuML: Successfully initialized accelerator.
cuML: Performing fit in GPUVocê entendeu a ideia. Agora, vamos tentar um exemplo mais convincente. De qualquer forma, a regressão linear não é especialmente paralelizável, pois a solução da equação normal ou a decomposição QR envolve algumas operações sequenciais.
Uma extensão mais complexa da regressão OLS é a regressão de cumeeira. Ao usar a regressão ridge em Python, chamar Ridge() aplica hiperparâmetros padrão, que podem não ser ideais. O valor alpha controla o grau de regularização aplicado. Se você for muito pequeno, o modelo ficará muito apertado; se for muito grande, o modelo ficará muito apertado.
%load_ext cuml.accel
import sklearn
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate synthetic data
X, y = make_regression(n_samples=100000, n_features=50, noise=0.1, random_state=0)
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Train a Ridge Regression model with default settings
ridge_default = Ridge()
ridge_default.fit(X_train, y_train)
# Make predictions and evaluate
y_pred_default = ridge_default.predict(X_test)
mse_default = mean_squared_error(y_test, y_pred_default)
O código acima treina um modelo, usando um único valor alfa e um solucionador. (Acredito que o padrão seja 'auto'.) Portanto, embora isso funcione, não otimiza a força da regularização nem a escolha do solucionador.
Em vez de confiar nos padrões, podemos tentar outra coisa. Poderíamos criar uma pesquisa em grade que testasse várias combinações de hiperparâmetros e selecionasse a melhor.
from sklearn.model_selection import GridSearchCV
# Define Ridge Regression model
ridge = Ridge()
# Define a grid of hyperparameters to search
param_grid = {
'alpha': [0.01, 0.1, 1.0, 10.0, 100.0], # Different regularization strengths
'solver': ['auto', 'svd', 'cholesky', 'lsqr', 'saga'] # Test multiple solvers
}
# Perform Grid Search with cross-validation
grid_search = GridSearchCV(ridge, param_grid, scoring='neg_mean_squared_error', cv=2, n_jobs=-1)
grid_search.fit(X_train, y_train)
# Get the best model from the search
best_ridge = grid_search.best_estimator_
# Make predictions and evaluate
y_pred_best = best_ridge.predict(X_test)
mse_best = mean_squared_error(y_test, y_pred_best)
Nossa pesquisa de grade aqui testa todas as combinações possíveis de hiperparâmetros. Se definirmos 5 valores para alfa ([0.01, 0.1, 1.0, 10.0, 100.0]), 5 opções de solver (['auto', 'svd', 'cholesky', 'lsqr', 'saga']) e usarmos a validação cruzada de 2 vezes, o número total de treinamentos de modelo necessários será 5x5x2, ou 50. Isso significa que, em vez de treinar um modelo, treinamos 50 modelos. Isso é muito, muito mais complexo, e é por isso que as GPUs serão tão boas de usar, pois são muito, muito mais rápidas. Como o sklearn tem (até) um aumento de 50 vezes na velocidade, o treinamento desses 50 modelos pode levar o mesmo tempo que o treinamento de apenas um. (Escolhi esses números intencionalmente para ilustrar esse ponto. Reconheço que nem todos os modelos terão o mesmo aumento de velocidade).
A NVIDIA comparou o desempenho dos algoritmos do scikit-learn executados em CPUs Intel com o de suas próprias GPUs NVIDIA. Eles analisaram diferentes cargas de trabalho de machine learning, incluindo classificação e regressão.
A conclusão é que modelos simples, como florestas aleatórias, passaram de minutos de tempo de treinamento em CPUs para segundos de tempo de treinamento em GPUs, e modelos mais complexos, como clustering, passaram de horas de tempo de treinamento para minutos. Os fluxos de trabalho ficaram mais rápidos em todos os casos, mas para os modelos computacionalmente pesados com dados de alta dimensão, os benefícios foram ainda mais claros. É nesse ponto que as GPUs se destacam, pois usam o processamento paralelo, o que faz uma grande diferença em modelos que exigem operações de matriz extensas, cálculos de distância ou otimização que é feita de forma iterativa.
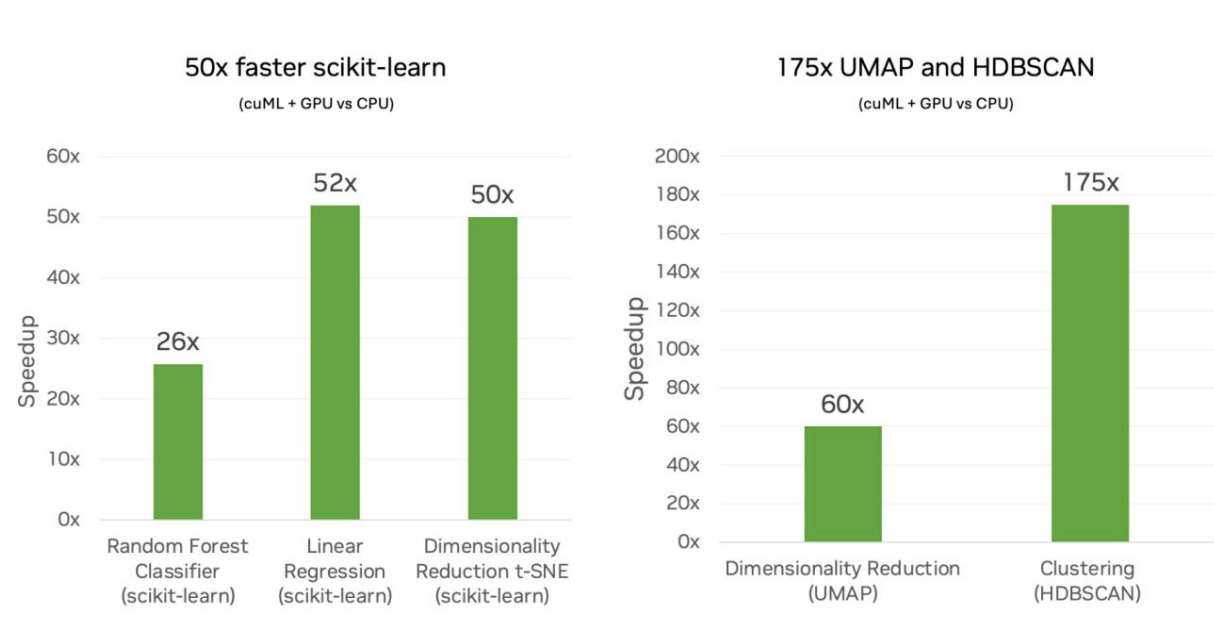
cuML scikit-learn na GPU versus scikit-learn na CPU. Fonte: NVIDIA
Afastei-me da regressão linear no exemplo de codificação anterior porque achei que deveria tentar outra coisa para mostrar o poder. Mas aqui, vejo uma aceleração de 52x para a regressão linear. Admito que estou surpreso porque isso parece ser um grande múltiplo. É um bom lembrete de que a NVIDIA também está fazendo outras coisas avançadas, como garantir que diferentes etapas possam ser intercaladas para que a GPU não fique ociosa.
Graças ao cuML versão 25.02, a execução deum algoritmo scitkit-learn com GPUs agora não é mais tão difícil. Você só precisa carregar a extensão, como mostrei anteriormente. No entanto, se você estiver mais a fundo no fluxo de trabalho e estiver interessado em aproveitar ao máximo a aceleração da GPU, deverá considerar aspectos muito específicos.
A NVIDIA recomenda que você minimize as transferências de dados entre as CPUs e as GPUs como parte do pipeline. Em outras palavras, realize as etapas de pré-processamento, treinamento e inferência nas GPUs antes de enviar os resultados de volta à memória do host. Não misture as etapas fazendo o pré-processamento nas CPUs e depois a inferência nas GPUs.
Além disso, para maximizar a eficiência, você deve considerar o CUDA-X, que é uma coleção de bibliotecas aceleradas por GPU desenvolvidas pela NVIDIA. Para florestas aleatórias, você pode usar a biblioteca de inferência de florestas do cuML, por exemplo, em vez da biblioteca do scikit-learn.
O que a equipe de IA do RAPIDS está fazendo é complexo, portanto, haverá alguns problemas. Felizmente, a documentação das limitações conhecidas é bem guardada. Não quero necessariamente incluir todas ou até mesmo algumas das limitações aqui, pois muitos dos problemas estão muito presentes em algoritmos específicos. Além disso, as atualizações ou patches são rápidos. Em vez disso, darei a você as categorias mais gerais de coisas a serem consideradas.
Há algumas restrições que se aplicam a todo o cuML, não apenas a algoritmos específicos. Os exemplos aqui parecem incluir restrições nos formatos de entrada de dados (alguns problemas com listas Python), compatibilidade de versão e manuseio de memória.
Existem algumas restrições exclusivas para algoritmos individuais de machine learning. Essas diferenças podem afetar a forma como os modelos são treinados, como os parâmetros se comportam ou como os resultados são computados. Por exemplo, o algoritmo de floresta aleatória no cuML usa um método diferente para escolher limites de divisão, o que resulta em estruturas de árvore ligeiramente diferentes.
Existem algumas diferenças com relação aos parâmetros, solucionadores e métodos de inicialização que são suportados. Por exemplo, o PCA oferece suporte a solucionadores SVD "completos" e "automáticos", mas não "randomizados". E o KNN é compatível com a métrica Minkowski, mas não com a Mahalanobis.
Em alguns casos, os resultados podem ser ligeiramente diferentes devido a diferenças de paralelismo ou de solver. Mencionei isso anteriormente. Por exemplo, os embeddings UMAP podem não ser idênticos, mas a pontuação de confiabilidade ainda deve ser alta. Em outros casos, os sinais dos componentes PCA podem se inverter, exigindo normalização. Novamente, isso é algo específico, e você deve consultar a documentação mais recente ao executar um algoritmo específico.
Estou animado com a perspectiva de uma aceleração de GPU muito fácil de usar para os algoritmos conhecidos das bibliotecas de machine learning mais comuns do Python. Isso fará uma grande diferença na precisão do modelo, além de ser conveniente e não ser difícil de implementar.
Mantenha-se atualizado com as últimas novidades em machine learning. Faça nosso programa de carreira de Cientista de Machine Learning em Python para que você se familiarize com todas as técnicas certas. Faça isso para que você possa aproveitar ao máximo os últimos avanços. Além disso, assine nosso podcast DataFrame. Temos até um episódio com Jean-Francois Puget, engenheiro renomado da NVIDIA, e Chris Deotte, cientista de dados sênior da NVIDIA, que discutem, entre outras coisas, o impacto da aceleração de GPU.
Aprenda Python e scikit-Learn com a DataCamp
Programa
Curso
Curso
blog
Abid Ali Awan
7 min
Tutorial
Kevin Babitz
Tutorial
Tutorial
Abid Ali Awan
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan


