
programa
Científico especializado en machine learning en Python
85 h
cuML de NVIDIA es una biblioteca de aprendizaje automático acelerado en la GPU que forma parte del ecosistema de IA RAPIDS. Y ahora, en beta abierta, cuML 25.02 hace posible disponer de aceleración por GPU en scikit-learn, UMAP y HDBSCAN sin cambiar tu código Python. Esto va a resultar una noticia muy interesante para los ingenieros de aprendizaje automático de Python, los científicos de datos e investigación, los desarrolladores y muchos más profesionales que esperan ver un aumento del rendimiento de sus modelos.
No te preocupes si no estás al día con cuML o incluso con la idea de la aceleración por GPU. Te llevaré de excursión y, al final de este artículo, serás capaz de utilizar la aceleración en la GPU para tus problemas de regresión, clasificación, reducción dimensional o clustering.
Tomémonos un momento para colocar todas las piezas en su sitio.
NVIDIA desarrolla tecnologías de vanguardia que potencian la computación de alto rendimiento, la IA y la ciencia de datos. Quizá recuerdes que salieron mucho en las noticias cuando Deepseek lanzó Deepseek-R1 y la gente se preguntaba si Deepseek utilizaba chips NVIDIA.
Pues bien, NVIDIA vuelve a ser noticia, esta vez por las innovaciones de su ecosistema de IA RAPIDS. RAPIDS AI, por si no lo conoces, es un conjunto de bibliotecas de código abierto aceleradas en la GPU diseñadas para acelerar los flujos de trabajo de la ciencia de datos y el aprendizaje automático. RAPIDS se basa en CUDA (Compute Unified Device Architecture), que es una plataforma de cálculo paralelo y un modelo de API desarrollado también por NVIDIA. Las bibliotecas aceleradas en la GPU de RAPIDS incluyen:
Ahora, sobre cuML: cuML proporciona implementaciones altamente optimizadas de algoritmos clásicos de aprendizaje automático. Como NVIDIA tiene los mejores chips de IA, estos algoritmos, que se ejecutan en GPUs NVIDIA, tienen un aumento de velocidad significativo. Las GPU, a diferencia de las CPU, destacan en el procesamiento paralelo, lo que prácticamente significa que pueden manejar miles de cálculos al mismo tiempo, haciéndolas ideales para tareas como (lo has adivinado) el aprendizaje profundo y el aprendizaje automático.
Si no estás familiarizado con scikit-learn y te tomas en serio el aprendizaje automático y la ciencia de datos, deberías matricularte en nuestro curso de Aprendizaje Supervisado con scikit-learn. Digo esto porque scikit-learn es la biblioteca número uno para datos tabulares en el lenguaje de programación número uno más popular para el aprendizaje automático. Además, scikit-learn es bastante fácil de aprender y tiene una API sencilla, y también funciona bien con pandas y NumPy. No es de extrañar, por tanto, que el equipo de IA de RAPIDS se centre en los algoritmos scikit-learn como elección estratégica y natural.
NVIDIA y cuML ofrecen ahora la gran novedad a scikit-learn, y también a UMAP y HDBSCAN, de un aumento masivo de la velocidad de rendimiento. Según el equipo de IA de RAPIDS, esto supone una velocidad de hasta 50x cuando se utiliza scikit-learn, 60x para UMAP y 175x para HDBSCAN.
Mis cálculos retrospectivos me dicen que un algoritmo que podría tardar cinco minutos en ejecutarse en scikit-learn podría reducirse teóricamente a tan sólo seis segundos. Es una gran diferencia. Dedicaré un poco más de tiempo a esto cuando examine los puntos de referencia más abajo.
Si todo esto te parece complejo, no te preocupes. RAPIDS AI se compromete a no realizar ningún cambio en el código API de scikit-learn. En realidad, sólo tienes que cargar la extensión, así:
%load_ext cuml.accel
$ python -m cuml.accel script.pyEsto no supone un cambio tan grande en el flujo de trabajo al que estás acostumbrado, que es de lo que se trata. En ocasiones, tal vez, tengas que reiniciar el núcleo y volver a cargar la extensión.
En mi opinión, este aspecto del cambio de código cero es, a primera vista, una afirmación realmente emocionante. La idea aquí es que no tengas que cambiar tus scripts scikit-learn ya creados, no la primera vez, pero tampoco nunca. cuML aceleraría automáticamente los componentes compatibles con en las GPUs NVIDIA, pero si hay algo en tu código que no es compatible con las GPUs NVIDIA, tu script volverá a la ejecución "normal" en la CPU. Tú, como programador, sólo verás el resultado y no tendrás que preocuparte de la gestión de errores ni de nada más.
Dicho esto, yo seguiría esperando casos extremos que pueden requerir ajustes. En la codificación, las cosas pueden salir mal, y nada es tan fácil como parece. La documentación de referencia tiene ciertas cosas que casi desmienten la afirmación de "sin cambios de código", o al menos le añaden un poco de fricción. Tienes que convertir las listas en matrices NumPY o Pandas DataFrames, y las etiquetas de cadena no son compatibles, por lo que los usuarios tienen que precodificar las etiquetas categóricas. Puede que hagas estas cosas de todos modos, pero la cuestión es que hay otras cosas a las que también tendrás que acostumbrarte, además de cargar la extensión.
Si estuvieras practicando estadística básica ejecutando una simple regresión lineal en el conjunto de datos mtcars, no serviría de mucho utilizar la aceleración de la GPU para encontrar la pendiente y la intersección de la línea un poquito más rápido. Ahorrar fracciones de segundo ni siquiera merecería la pena cargar la extensión, la verdad. Pero si en lugar de eso estuvieras ejecutando un algoritmo más complejo, el tiempo ahorrado realmente importa por dos razones principales.
Por un lado, el tiempo que ahorras es significativo para muchos flujos de trabajo. Mencioné que un aumento de velocidad de hasta 50 veces se traduciría, hipotéticamente, en reducir un tiempo de entrenamiento de cinco minutos a seis segundos. Eso supone un ahorro de casi cinco minutos. Pero considera el flujo de trabajo del ingeniero de aprendizaje automático, donde el modelo puede requerir ejecutarlo unas cuantas veces para hacerlo bien. Sumado, hablar de ahorrar tiempo en cada ejecución es hablar de la productividad global de un científico de datos.
En segundo lugar, y relacionado con lo anterior, el científico o ingeniero podría ahora empezar a intentar modelos más complejos. En el ejemplo anterior, estamos suponiendo una velocidad de tiempo para un modelo que produce el mismo nivel de precisión. Pero, ¿y si pensaras que en realidad tendrías mayor precisión con un modelo más complejo? Imagina que haces una búsqueda en cuadrícula de diferentes parámetros del modelo y entrenas un modelo. (Intentaré poner mi propio mini ejemplo, más abajo). Las permutaciones crecen exponencialmente, lo que hace que el coste computacional sea prohibitivo en una CPU. Pero eso no es un problema si tienes un aumento de velocidad de 50x.
Estos beneficios van juntos. Si configuras bien tu proyecto, podrías tener un modelo más preciso que también se produjera más rápidamente o, como podría pensar un ingeniero de aprendizaje automático, podrías tener una arquitectura de modelo más sofisticada sin tiempos de entrenamiento excesivos.
NVIDIA se esfuerza en hablar de cómo las GPUs revelarían resultados numéricamente equivalentes. Es bueno oírlo, porque significa que las ventajas no conllevan inconvenientes en cuanto a la precisión del modelo.
Pero esto también me hizo pensar: ¿Por qué los resultados son numéricamente equivalentes y no iguales? Bueno, probablemente, como resultado del procesamiento paralelo, hay algunas pequeñas diferencias en el resultado, o hay algunas diferencias en la estabilidad numérica de un método dado. Quizá en el caso de UMAP la proyección UMAP sea ligeramente diferente. Saco esto a colación por si vieras diferencias sutiles en el resultado entre la ejecución en CPU y en GPU. NVIDIA parece sugerir que debes esperar ver algo de eso, y que es normal.
Dicho todo esto, si realmente te estás retando a ti mismo y ejecutas un modelo en GPUs porque el modelo es lo suficientemente complejo como para que las CPUs no funcionen en la práctica, entonces comparar el resultado de dicho modelo con un equivalente en CPU resultaría difícil.
He mencionado antes que ahora hay soporte en esta versión cuML 25. 02 para scikit-learn, UMAP y HDBSCAN. Pero si estás familiarizado con scikit-learn, sabrás que hay muchos algoritmos diferentes en scikit-learn. Actualmente, RAPIDS AI admite algunas de las bibliotecas, pero no todas. Éstos son los principales gritos, según el equipo:
En esta lista, lo que más me entusiasmaría sería un aumento de la velocidad de k-Nearest Neighbors, que se sabe que es muy intensivo desde el punto de vista computacional porque hay que calcular distancias entre todos los puntos de datos.
La siguiente tabla te muestra los estimadores que se ejecutan en su mayor parte o en su totalidad con cuML.
| Algoritmo | Biblioteca / Función Nombre | Categoría |
|---|---|---|
| UMAP | umap.UMAP |
Reducción de la dimensionalidad |
| ACP (Análisis de Componentes Principales) | sklearn.decomposition.PCA |
Reducción de la dimensionalidad |
| SVD truncado | sklearn.decomposition.TruncatedSVD |
Reducción de la dimensionalidad |
| t-SNE | sklearn.manifold.TSNE |
Reducción de la dimensionalidad |
| HDBSCAN | hdbscan.HDBSCAN |
Agrupación |
| K-Means | sklearn.cluster.KMeans |
Agrupación |
| DBSCAN | sklearn.cluster.DBSCAN |
Agrupación |
| Clasificador Random Forest | sklearn.ensemble.RandomForestClassifier |
Clasificación |
| Regresión logística | sklearn.linear_model.LogisticRegression |
Clasificación |
| Clasificador K-Nearest Neighbors | sklearn.neighbors.KNeighborsClassifier |
Clasificación |
| Regresor forestal aleatorio | sklearn.ensemble.RandomForestRegressor |
Regresión |
| Regresión lineal | sklearn.linear_model.LinearRegression |
Regresión |
| Red elástica | sklearn.linear_model.ElasticNet |
Regresión |
| Regresión Ridge | sklearn.linear_model.Ridge |
Regresión |
| Regresión Lasso | sklearn.linear_model.Lasso |
Regresión |
| Regresión Kernel Ridge | sklearn.kernel_ridge.KernelRidge |
Regresión |
| K-Nearest Neighbors Regresor | sklearn.neighbors.KNeighborsRegressor |
Regresión |
| Búsqueda de vecinos más cercanos | sklearn.neighbors.NearestNeighbors |
Búsqueda de vecinos más cercanos |
La lista completa de métodos compatibles está disponible en la documentación de RAPIDS AI. Esperamos que pronto se añadan más algoritmos. (También puedes aportar algún comentario para ayudar al equipo a establecer prioridades). Algunas de las que noté que faltaban: regresor de vector de soporte (sklearn.svm.SVR), regresor de Theil-Sen (sklearn.linear_model.TheilSenRegressor), agrupación por desplazamiento de medias (sklearn.cluster.MeanShift) y escalado multidimensional (sklearn.manifold.MDS).
Quizá te preguntes cómo funciona todo esto. Desde 30k pies, debes saber que, cada vez más, las bibliotecas modernas se diseñan para detectar y utilizar automáticamente el mejor hardware disponible, ya sea una CPU o una GPU. Ahora vemos que, cuando se llama a una función en scikit-learn (cuando cuml.accel está activado), el software comprueba si hay disponible una GPU compatible y redirige la ejecución a una versión acelerada por GPU si la hay.
RAPIDS AI habla de este mecanismo para hacer que cuml.accel actúe como sklearn como capa de compatibilidad. En este caso, la capa de compatibilidad de cuML permite ejecutar código scikit-learn en GPUs NVIDIA sin cambios. Está construido como un reemplazo drop-in y actúa como un proxy e intercepta las llamadas de función a scikit-learn y las redirige a cuML.
El equipo RAPIDS AI de NVIDIA comparte un gráfico útil que también compartiré aquí:
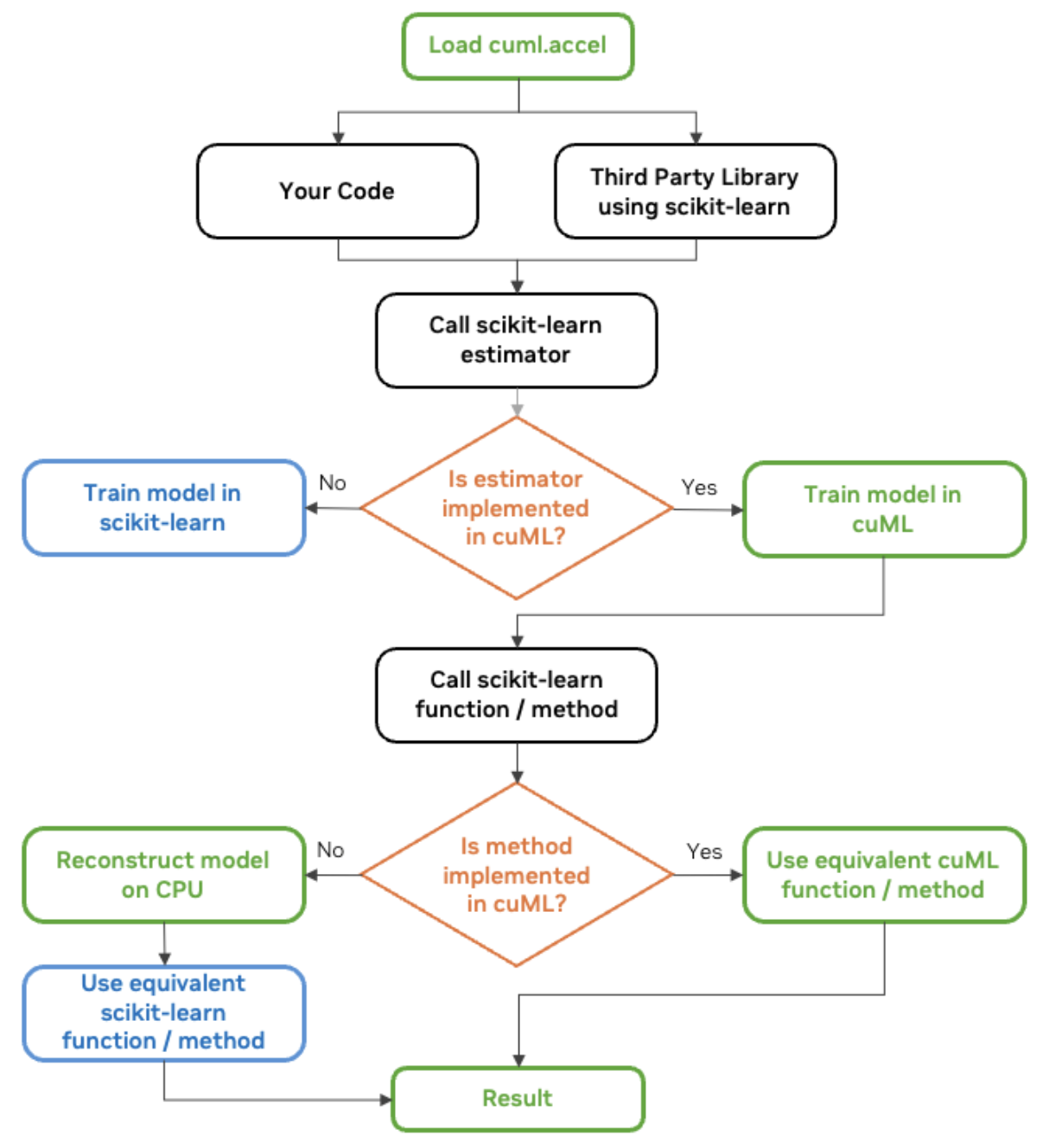
diagrama de flujo de trabajo cuML scikit-learn. Fuente: NVIDIA
cuML ya está preinstalado en Google Colab, pero si utilizas un cuaderno Jupyter, actívalo con este comando antes de importar scikit-learn:
%load_ext cuml.accel
import sklearnAhora, nuestro código Python utilizando sklearn te va a resultar familiar, que es de lo que se trata. Aquí tienes un ejemplo de regresión MCO.
# Import necessary libraries
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# Generate synthetic regression data
X, y = make_regression(n_samples=500000, n_features=50, noise=0.1, random_state=0)
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Create and train an OLS regression model
ols = LinearRegression()
ols.fit(X_train, y_train)Si quiero ver qué partes se han ejecutado en la GPU en lugar de en la CPU, podría utilizar logger.
%load_ext cuml.accel
from cuml.common import logger;
logger.set_level(logger.level_enum.debug)cuML: Installed accelerator for sklearn.
cuML: Successfully initialized accelerator.
cuML: Performing fit in GPUYa te haces una idea. Ahora, probemos con un ejemplo más convincente. De todas formas, la regresión lineal no es especialmente paralelizable, ya que resolver la ecuación normal o descomposición QR implica algunas operaciones secuenciales.
Una extensión más compleja de la regresión OLS es la regresión ridge. Cuando se utiliza la regresión ridge en Python, al llamar a Ridge() se aplican hiperparámetros por defecto, que pueden no ser óptimos. El valor alpha controla cuánta regularización se aplica. Si es demasiado pequeño, el modelo se ajusta demasiado; si es demasiado grande, el modelo se ajusta demasiado poco.
%load_ext cuml.accel
import sklearn
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate synthetic data
X, y = make_regression(n_samples=100000, n_features=50, noise=0.1, random_state=0)
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Train a Ridge Regression model with default settings
ridge_default = Ridge()
ridge_default.fit(X_train, y_train)
# Make predictions and evaluate
y_pred_default = ridge_default.predict(X_test)
mse_default = mean_squared_error(y_test, y_pred_default)
El código anterior entrena un modelo, utilizando un único valor alfa y solucionador. (Creo que por defecto es 'auto'.) Así que, aunque esto funciona, no optimiza la fuerza de regularización ni la elección del solucionador.
En lugar de confiar en los valores por defecto, podríamos intentar otra cosa. Podríamos crear una búsqueda reticular que probara múltiples combinaciones de hiperparámetros y seleccionara la mejor.
from sklearn.model_selection import GridSearchCV
# Define Ridge Regression model
ridge = Ridge()
# Define a grid of hyperparameters to search
param_grid = {
'alpha': [0.01, 0.1, 1.0, 10.0, 100.0], # Different regularization strengths
'solver': ['auto', 'svd', 'cholesky', 'lsqr', 'saga'] # Test multiple solvers
}
# Perform Grid Search with cross-validation
grid_search = GridSearchCV(ridge, param_grid, scoring='neg_mean_squared_error', cv=2, n_jobs=-1)
grid_search.fit(X_train, y_train)
# Get the best model from the search
best_ridge = grid_search.best_estimator_
# Make predictions and evaluate
y_pred_best = best_ridge.predict(X_test)
mse_best = mean_squared_error(y_test, y_pred_best)
Nuestra búsqueda en cuadrícula prueba aquí todas las combinaciones posibles de hiperparámetros. Si definimos 5 valores para alfa ([0.01, 0.1, 1.0, 10.0, 100.0]), 5 opciones de solucionador (['auto', 'svd', 'cholesky', 'lsqr', 'saga']), y utilizamos la validación cruzada doble, el número total de entrenamientos del modelo necesarios es 5x5x2, es decir, 50. Esto significa que en lugar de entrenar un modelo, entrenamos 50 modelos. Esto es mucho, mucho más complejo, y por eso las GPU serán tan estupendas de utilizar, porque son mucho, mucho más rápidas. Como sklearn tiene (hasta) 50 veces más velocidad, entrenar estos 50 modelos puede llevar el mismo tiempo que entrenar sólo uno. (He elegido estas cifras intencionadamente para ilustrar este punto. Reconozco que no todos los modelos tendrán el mismo aumento de velocidad).
NVIDIA comparó el rendimiento de los algoritmos scikit-learn ejecutados en CPUs Intel frente a sus propias GPUs NVIDIA. Examinaron distintas cargas de trabajo de aprendizaje automático, como la clasificación y la regresión.
La conclusión es que los modelos sencillos, como los bosques aleatorios, pasaron de requerir minutos de entrenamiento en la CPU a segundos en la GPU, y los modelos más complejos, como el clustering, pasaron de requerir horas de entrenamiento a minutos. Los flujos de trabajo fueron más rápidos en todos los casos, pero en el caso de los modelos computacionalmente pesados con datos de alta dimensión, las ventajas fueron aún más claras. E aquí es donde brillan las GPU porque utilizan el procesamiento paralelo y se sabe que eso marca una gran diferencia en los modelos que requieren extensas operaciones matriciales, cálculos de distancias u optimizaciones que se realizan de forma iterativa.
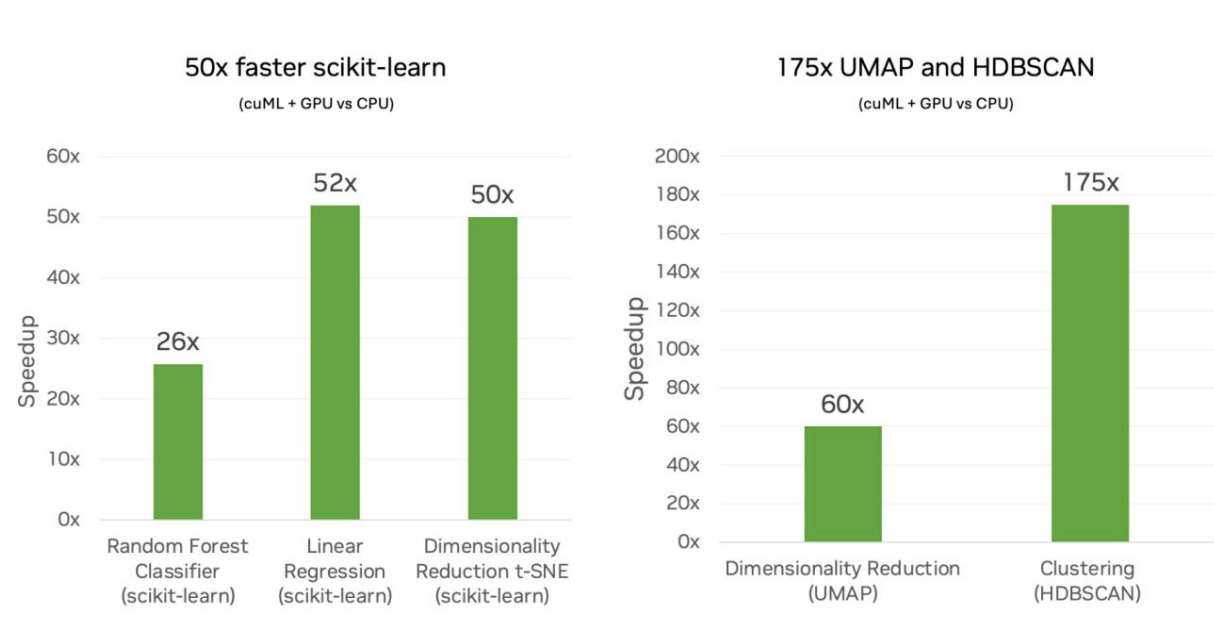
cuML scikit-learn en GPU vs scikit-learn en CPU. Fuente: NVIDIA
Me alejé de la regresión lineal en el ejemplo de codificación anterior porque pensé que debía probar otra cosa para mostrar la potencia. Pero aquí, veo una aceleración de 52x para la regresión lineal. Reconozco que estoy sorprendido porque eso parece un gran múltiplo. Es un buen recordatorio de que NVIDIA también está haciendo otras cosas avanzadas, como asegurarse de que se puedan intercalar diferentes pasos para que la GPU no esté inactiva.
Gracias a la versión 25.02 de cuML, ejecutarun algoritmo scitkit-learn con GPUs ya no es tan difícil. Sólo tienes que cargar la extensión, como he mostrado antes. Sin embargo, si estás más metido en el flujo de trabajo y te interesa aprovechar al máximo la aceleración de la GPU, deberás tener en cuenta cosas muy concretas.
NVIDIA recomienda minimizar las transferencias de datos entre la CPU y la GPU como parte de tu pipeline. En otras palabras, realiza los pasos de preprocesamiento, entrenamiento e inferencia en las GPU antes de enviar los resultados a la memoria host. No mezcles los pasos haciendo el preprocesamiento en las CPU y luego la inferencia en las GPU.
Además, para maximizar la eficiencia, deberías considerar CUDA-X, que es una colección de librerías aceleradas en la GPU desarrolladas por NVIDIA. Para los bosques aleatorios, podrías utilizar la biblioteca de inferencia de bosques de cuML, por ejemplo, en lugar de la de scikit-learn.
Lo que está haciendo el equipo de IA de RAPIDS es complejo, así que habrá algunos problemas. Afortunadamente, la documentación sobre las limitaciones conocidas está bien conservada. No quiero necesariamente incluir aquí todas las limitaciones, ni siquiera algunas de ellas, porque muchos de los problemas están bastante relacionados con algoritmos concretos. Además, las actualizaciones o parches se mueven con rapidez. En su lugar, te daré las categorías más generales de cosas a tener en cuenta.
Hay algunas restricciones que se aplican a todo el cuML, no sólo a algoritmos específicos. Los ejemplos aquí parecen incluir restricciones en los formatos de entrada de datos (algunos problemas con las listas de Python), compatibilidad de versiones y manejo de la memoria.
Existen algunas limitaciones únicas para los algoritmos individuales de aprendizaje automático. Estas diferencias pueden afectar a cómo se entrenan los modelos, cómo se comportan los parámetros o cómo se calculan los resultados. Por ejemplo, el algoritmo de bosque aleatorio de cuML utiliza un método diferente para elegir los umbrales de división, lo que da lugar a estructuras de árbol ligeramente diferentes.
Hay algunas diferencias con los parámetros, solucionadores y métodos de inicialización compatibles. Por ejemplo, PCA admite solucionadores SVD "completos" y "automáticos", pero no "aleatorios". Y KNN admite la métrica de Minkowski, pero no la de Mahalanobis.
Hay veces en que los resultados pueden diferir ligeramente debido al paralelismo o a las diferencias del solucionador. Ya lo he mencionado antes. Por ejemplo, las incrustaciones UMAP pueden no ser idénticas, pero la puntuación de fiabilidad debe seguir siendo alta. En otros casos, los signos de los componentes del PCA pueden invertirse, lo que requiere una normalización. De nuevo, esto es algo específico, y debes consultar la documentación más reciente cuando ejecutes un algoritmo concreto.
Me entusiasma la perspectiva de una aceleración en la GPU superfácil de usar para los algoritmos bien conocidos de las bibliotecas de aprendizaje automático más comunes de Python. Esto va a suponer una gran diferencia en la precisión del modelo, y es cómodo y nada difícil de aplicar.
Mantente al día de lo último en aprendizaje automático. Sigue nuestro itinerario profesional de Científico de Aprendizaje Automático en Python para familiarizarte con todas las técnicas adecuadas. Hazlo para poder aprovechar al máximo los últimos avances. Suscríbete también a nuestro podcast DataFramed. Incluso tenemos un episodio con Jean-Francois Puget, Ingeniero Distinguido de NVIDIA y Chris Deotte, Científico Senior de Datos de NVIDIA, que hablan, entre otras cosas, del impacto de la aceleración en la GPU.
Aprende Python y scikit-Learn con DataCamp
programa
Curso
Curso
Tutorial
Kevin Babitz
Tutorial
Abid Ali Awan
Tutorial
Avinash Navlani
Tutorial
Abid Ali Awan
Tutorial
Adam Shafi
Tutorial
Bekhruz Tuychiev

