

programa
Desarrollar grandes modelos lingüísticos
16 h
A finales de 2017, un artículo de investigación titulado Attention Is All You Need presentó un mecanismo revolucionario que transformaría de raíz la inteligencia artificial. En el centro de ese avance estaba la autoatención, una idea sencilla pero poderosa que permite a los modelos comprender las relaciones dentro de los datos determinando qué elementos merecen más atención.
Hoy, la autoatención impulsa desde la capacidad conversacional de ChatGPT hasta sistemas avanzados de reconocimiento de imágenes. Es, sin duda, una de las innovaciones más transformadoras en la historia del aprendizaje automático.
En esta guía, te llevaré desde los fundamentos conceptuales de la autoatención hasta sus aplicaciones, y verás cómo este mecanismo ayuda a los modelos a captar dependencias de largo alcance y a procesar información en paralelo, capacidades que antes eran inalcanzables con las redes neuronales tradicionales.
Si eres nuevo en los transformers, plantéate empezar con alguno de nuestros cursos introductorios sobre Large Language Models (LLMs) Concepts y Transformer Models with PyTorch.
Por mi experiencia enseñando este concepto, el mejor punto de partida es un reto fundamental del procesamiento de secuencias: ¿cómo puede un modelo determinar qué partes de su entrada son más relevantes en cada momento?
Empecemos con la intuición antes de meternos en matemáticas.
La autoatención es un mecanismo que pondera la importancia de los distintos elementos de una secuencia en relación unos con otros. Al procesar la frase "The animal didn't cross the road because it was too tired", la autoatención ayuda al modelo a entender que "it" se refiere a "animal" y no a "road", una relación que abarca varias palabras.
De hecho, este es el ejemplo que siempre uso cuando presento el concepto al alumnado. Les encaja al instante porque refleja cómo leemos de forma natural.
Lo que hace especialmente potente a la autoatención es su capacidad para calcular estas relaciones para todas las posiciones de una secuencia de forma simultánea. A diferencia de las redes neuronales recurrentes, que procesan las secuencias paso a paso, la autoatención examina cada elemento en relación con todos los demás en una sola pasada.
Este cómputo en paralelo reduce drásticamente el tiempo de entrenamiento a la vez que capta dependencias sin importar su distancia en la secuencia.
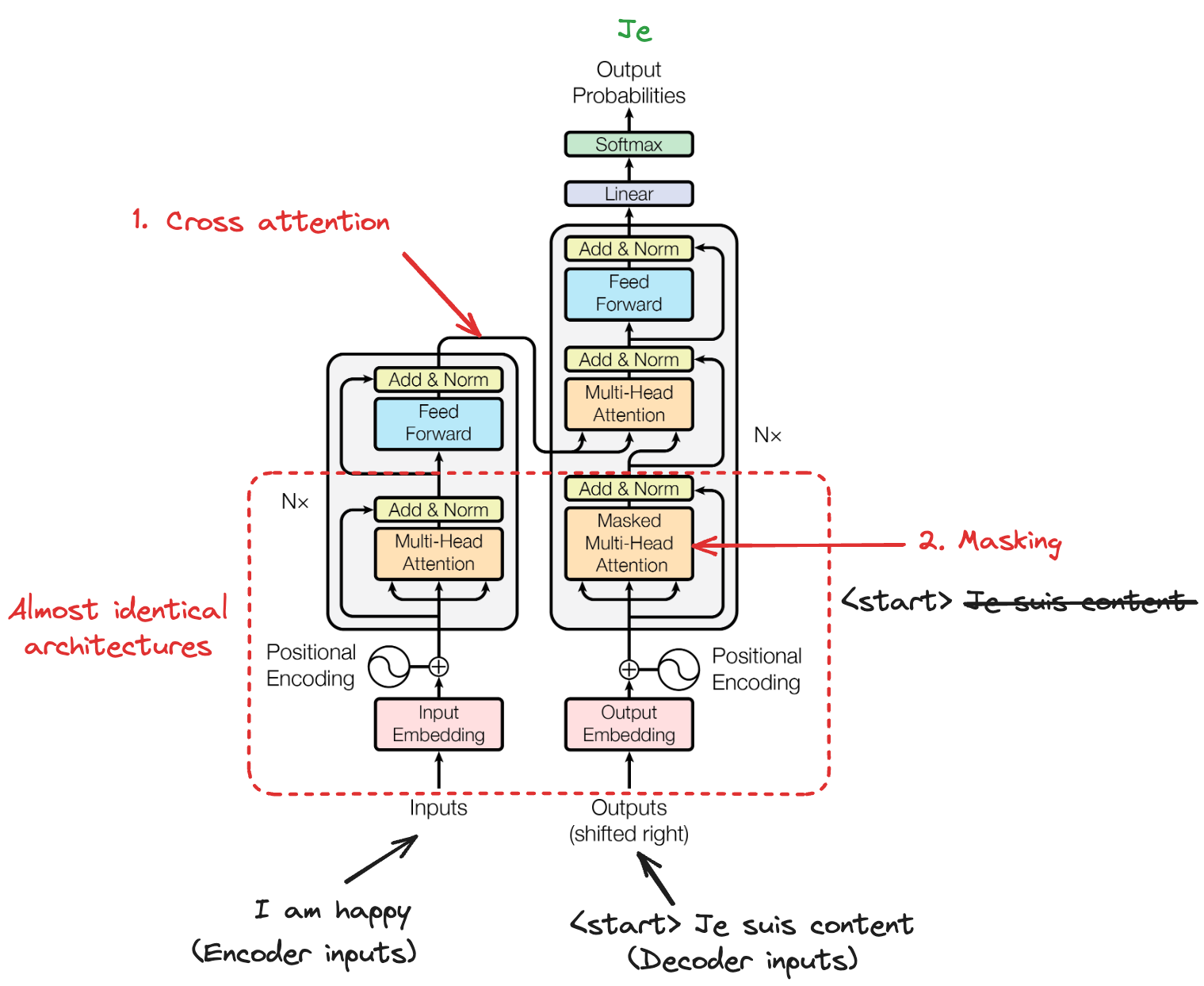
Es importante distinguir la autoatención de mecanismos relacionados. En autoatención, una secuencia se atiende a sí misma. Cada elemento consulta información de todas las posiciones dentro de la misma secuencia.
La atención cruzada (cross-attention), en cambio, permite que una secuencia atienda a otra, como cuando un decodificador atiende a las salidas del codificador durante la traducción automática.
La autoatención enmascarada (masked self-attention) añade una restricción adicional: impide que una posición atienda a posiciones posteriores, garantizando que las predicciones dependan solo de salidas conocidas, algo esencial en la generación autorregresiva de texto.
Pero, ¿de dónde salió realmente esta idea y qué problemas pretendía resolver?
Antes de que surgiera la autoatención, el campo lidiaba con limitaciones importantes en el modelado de secuencias.
Las redes neuronales recurrentes, incluidas LSTM y GRU, procesan las secuencias de forma secuencial, creando un cuello de botella fundamental: les cuesta manejar dependencias de largo alcance porque la información debe pasar por muchos estados intermedios, lo que provoca gradientes que se desvanecen y pérdida de contexto.
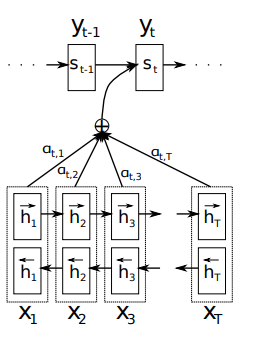
La evolución hacia la autoatención comenzó con los mecanismos de atención en arquitecturas codificador-decodificador basadas en RNN. En 2014, Bahdanau y colaboradores introdujeron un mecanismo de atención que permitía a los decodificadores acceder a todos los estados ocultos del codificador en lugar de depender de un único vector de contexto de longitud fija.
Este avance abordó el problema de la compresión de información, por el cual secuencias de entrada de longitud variable se comprimían en representaciones de longitud fija independientemente de su complejidad.
Bahdanau's graphical illustration of the proposed model
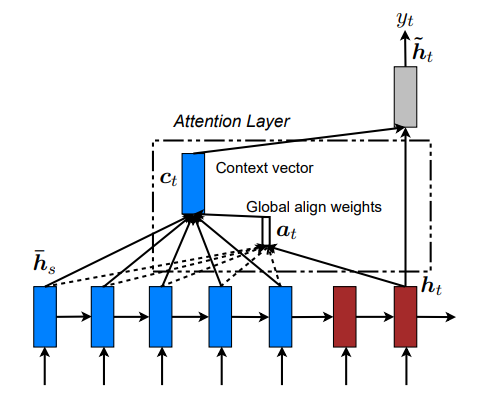
Un año después, Luong propuso mecanismos de atención simplificados, incluido el enfoque de producto escalar escalado que más tarde influiría en el diseño de los transformers. Aunque estos primeros mecanismos de atención mejoraron el rendimiento, seguían dependiendo del procesamiento secuencial de las RNN.
Global attentional model (Luong)
La verdadera revolución llegó cuando los investigadores se preguntaron: ¿y si eliminamos la recurrencia y confiamos únicamente en la atención? Esta pregunta dio lugar a la arquitectura transformer, donde la autoatención se convirtió en el mecanismo principal para entender relaciones secuenciales.
Ahora que hemos visto por qué importa la autoatención, veamos cómo funciona realmente a nivel matemático.
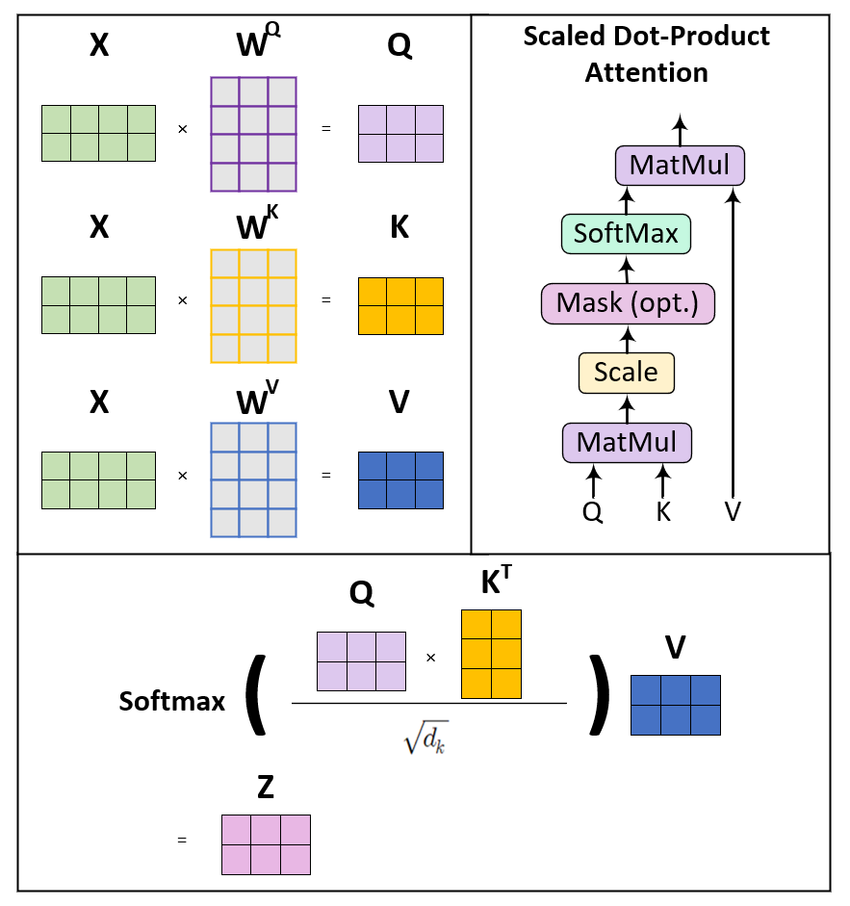
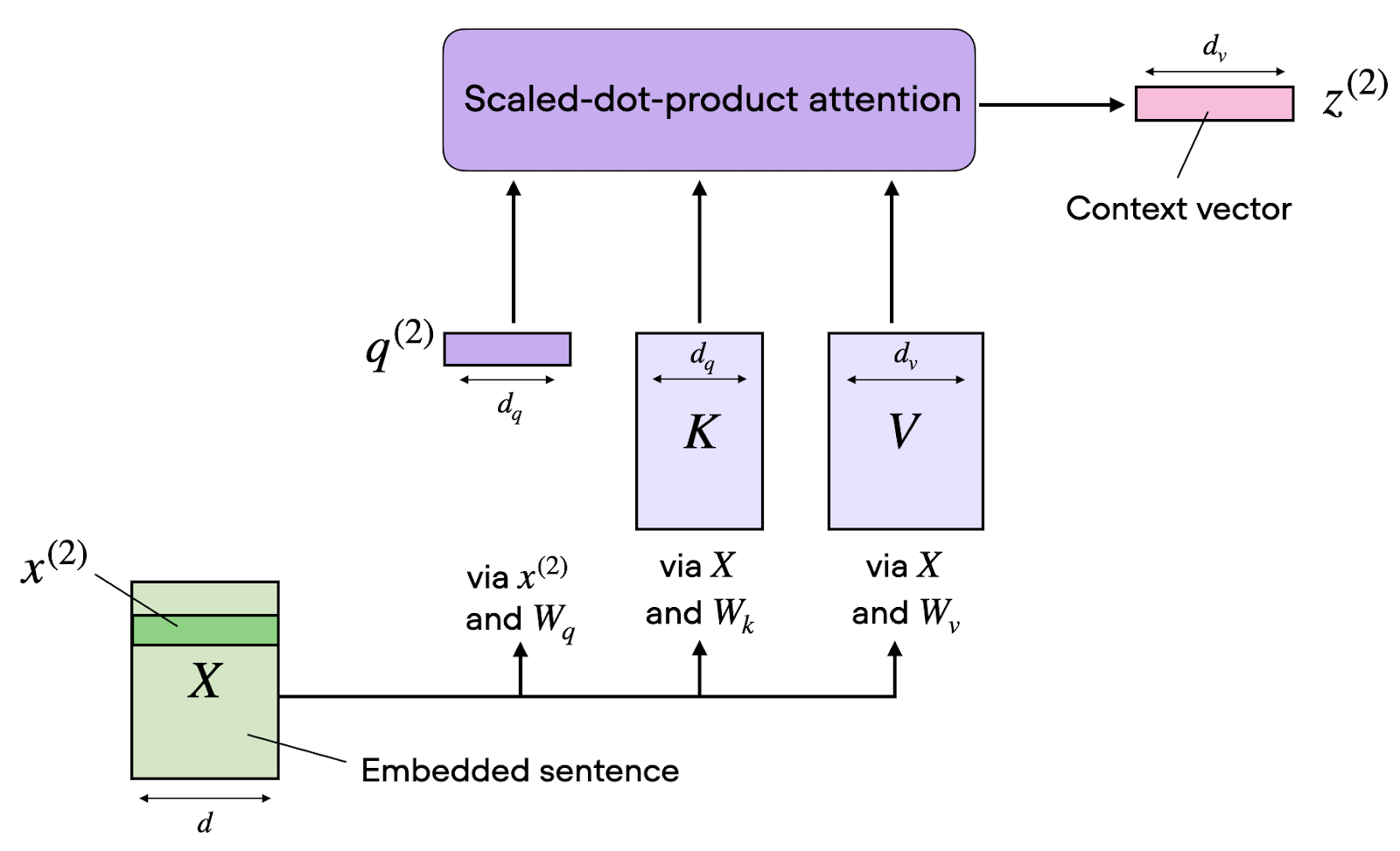
La autoatención transforma las secuencias de entrada mediante tres proyecciones aprendidas: consultas (queries), claves (keys) y valores (values). Piensa en ellas como distintas "vistas" de la misma información, cada una con un propósito específico en el cálculo de la atención.
Para una secuencia de entrada con dimensión de embedding d_model, creamos tres matrices de pesos: W_Q, W_K y W_V. Al multiplicar nuestra matriz de entrada X por estos pesos, obtenemos:
Matriz de consultas Q = X · W_Q: representa "lo que busco"
Matriz de claves K = X · W_K: representa "lo que ofrezco"
Matriz de valores V = X · W_V: representa "lo que realmente contengo"
Me resulta útil esta analogía con una biblioteca: entras con una consulta en mente, las fichas del índice son tus claves y los libros en sí son tus valores.
Normalmente, estas matrices proyectan a una dimensión menor d_k (a menudo d_model dividido por el número de cabezas de atención), lo que controla la complejidad computacional manteniendo la capacidad de representación. Esta reducción de dimensionalidad cobra especial importancia al escalar a secuencias más largas.
Con Q, K y V en la mano, ya podemos calcular la atención.
El cálculo de la atención sigue una fórmula elegante. Primero, calculamos las puntuaciones de atención tomando el producto escalar entre consultas y claves. Esta operación mide la compatibilidad entre lo que cada posición busca y lo que cada otra posición ofrece.
Sin embargo, al aumentar la dimensionalidad, estos productos escalares pueden crecer mucho en magnitud, empujando la función softmax a regiones con gradientes extremadamente pequeños. Para evitar esta inestabilidad numérica, escalamos dividiendo por la raíz cuadrada de la dimensión de las claves.
Scaled dot-product attention
Este factor de escala mantiene una varianza adecuada en toda la red, garantizando gradientes estables durante el entrenamiento. Sin él, los modelos con embeddings de alta dimensión tendrían dificultades para aprender de forma efectiva, ya que el softmax produciría distribuciones casi one-hot que no reparten la atención de manera significativa.
Antes de continuar, hay una pieza importante que debemos abordar: el codificado posicional.
Esto fue lo que más me sorprendió cuando lo estudié por primera vez: la autoatención es completamente invariante a permutaciones. Si barajas los tokens de entrada, obtendrás la misma salida, solo que barajada en consecuencia.
Me costó un poco asimilar la implicación: el mecanismo es potente, pero esencialmente ciego al orden. Para tareas donde el orden importa (como entender el lenguaje), debemos inyectar explícitamente información posicional.
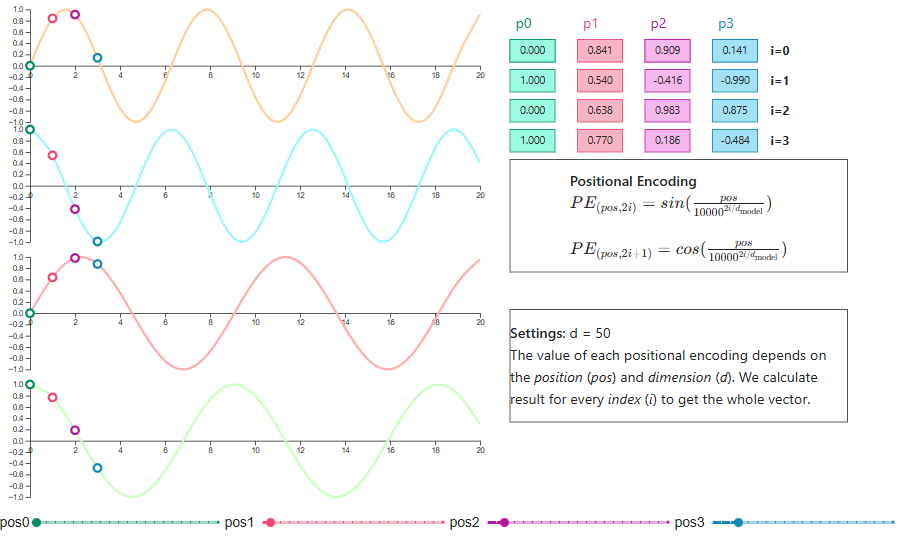
El transformer original utilizó codificaciones posicionales sinusoidales, aplicando funciones seno y coseno de distintas frecuencias a cada dimensión. Esta elección no fue arbitraria. Los patrones ondulatorios permiten que los modelos aprendan a atender a posiciones relativas y la codificación se extiende de forma natural a longitudes de secuencia no vistas.
Positional encoding visualization
Innovaciones más recientes incluyen RoPE (Rotary Position Embedding), que rota los vectores de consulta y clave en un espacio multidimensional con ángulos proporcionales a sus posiciones. Tras la rotación, el producto escalar entre consultas y claves codifica de forma natural la distancia relativa.
RoPE se ha adoptado ampliamente en modelos como LLaMA por su gran capacidad de extrapolación.
Otro enfoque, ALiBi (Attention with Linear Biases), sigue un camino distinto añadiendo penalizaciones dependientes de la posición directamente a las puntuaciones de atención. En lugar de modificar los embeddings, ALiBi sesga los pesos de atención para favorecer los tokens cercanos, con una intensidad de sesgo que varía entre cabezas de atención.
Este método demuestra una extrapolación impresionante a longitudes de secuencia muy superiores a las vistas durante el entrenamiento.
Tras calcular las puntuaciones de atención escaladas, aplicamos softmax a lo largo de la dimensión de las claves. Esta normalización convierte las puntuaciones en una distribución de probabilidad, asegurando que los pesos de atención sumen uno para cada posición de consulta.
La función softmax enfatiza las relaciones con mayor puntuación y suprime las conexiones irrelevantes. No obstante, a veces puede generar distribuciones demasiado picudas, especialmente en las primeras fases del entrenamiento cuando el modelo aún no ha aprendido patrones de atención matizados.
Para mitigarlo, a menudo se aplica dropout a los pesos de atención, anulando aleatoriamente algunas conexiones para fomentar la robustez.
Con los pesos de atención, calculamos la salida final como una suma ponderada de los vectores de valor.
Cada posición recibe una representación sensible al contexto que agrega información de toda la secuencia, con contribuciones proporcionales a los pesos de atención. Esta combinación ponderada permite que la información fluya de manera dinámica en función de relaciones aprendidas y no de patrones fijos.
La atención de una sola cabeza nos lleva sorprendentemente lejos, pero tiene techo. Aquí es donde se pone más interesante.
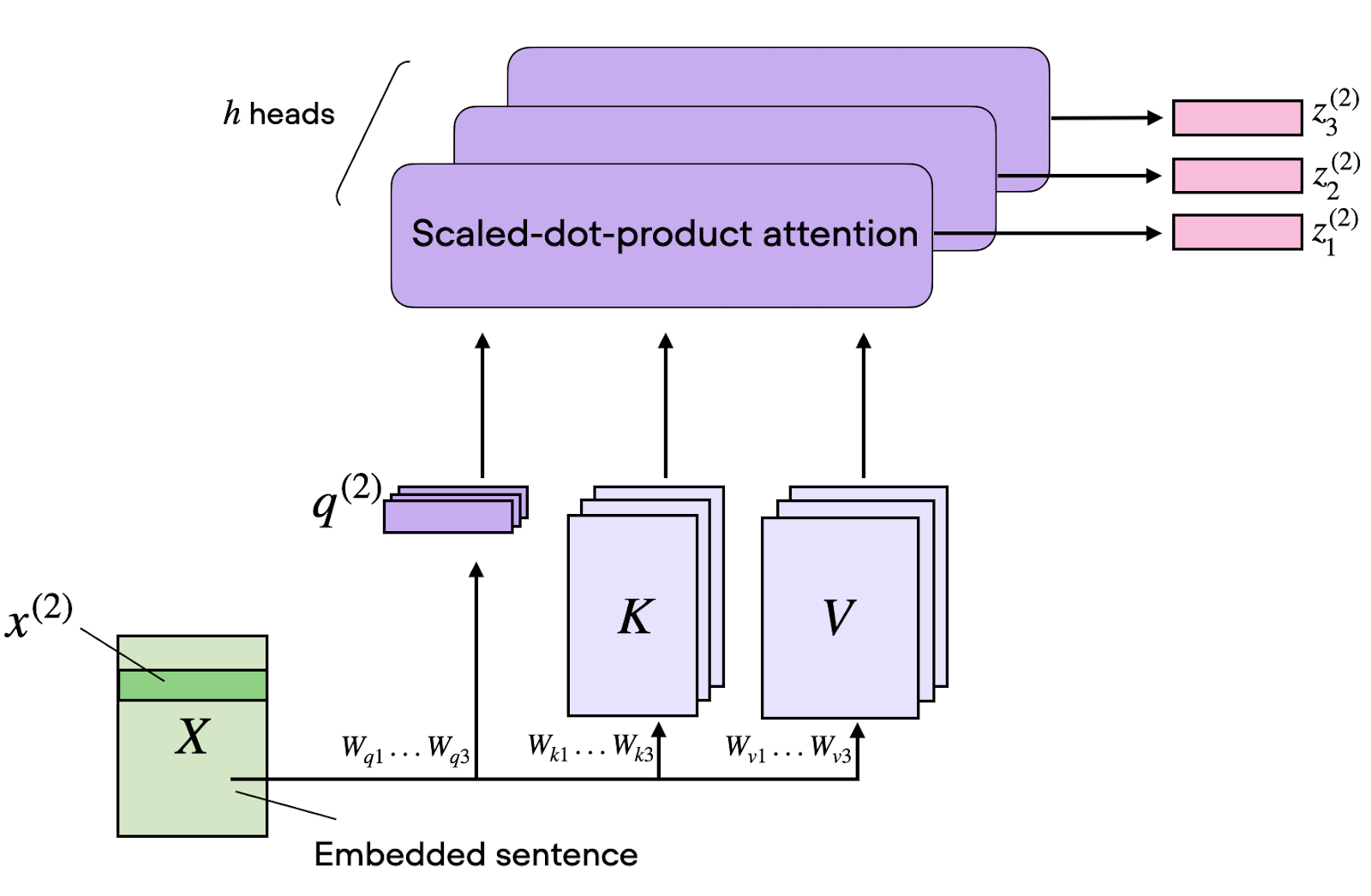
Aunque la atención de una sola cabeza es potente, tiene una limitación fundamental: solo puede capturar un tipo de relación a la vez.
La atención multi-cabeza soluciona esto ejecutando varios cálculos de atención en paralelo, cada uno centrado en distintos aspectos de las relaciones de entrada. Por ejemplo, puede haber una cabeza especializada en:
Por lo que he observado trabajando con estos modelos, esta especialización suele emerger de forma orgánica durante el entrenamiento. No la diseñas tú, y creo que es uno de los aspectos más fascinantes de todo el mecanismo.
La implementación consiste en dividir las matrices Q, K y V a lo largo del eje de dimensión, procesar cada división en cabezas de atención independientes y concatenar los resultados.
Si tenemos 8 cabezas y embeddings de 512 dimensiones, cada cabeza opera en subespacios de 64 dimensiones. Este procesamiento en paralelo no aumenta la complejidad con respecto a la longitud de la secuencia, pero sí multiplica la capacidad del modelo para aprender patrones diversos.
La investigación sobre lo que realmente aprenden las diferentes cabezas de atención ha revelado patrones fascinantes.
En modelos de traducción, algunas cabezas atienden de forma constante a relaciones posicionales, fijándose en palabras vecinas independientemente del contenido. Otras se especializan en roles sintácticos, identificando relaciones sujeto-verbo o verbo-objeto. Una tercera categoría presta atención a tokens raros o con alta carga informativa, como nombres propios y términos técnicos.
Curiosamente, los estudios de interpretabilidad muestran que muchas cabezas parecen redundantes, y los modelos pueden mantener el rendimiento incluso cuando se poda una fracción significativa de ellas. Esta redundancia probablemente contribuye a la robustez, garantizando que los patrones críticos tengan múltiples vías a través de la red.
En la atención codificador-decodificador, las cabezas de las capas posteriores del decodificador resultan ser las más esenciales para la calidad de la traducción, mientras que las cabezas de autoatención del codificador a menudo pueden reducirse sustancialmente.
Con los fundamentos matemáticos asentados, veamos cómo se integra la autoatención en la arquitectura completa de un transformer.
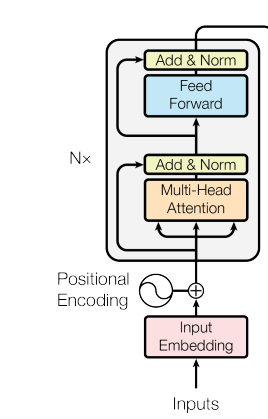
En el codificador del transformer, las capas de autoatención permiten que cada posición atienda a todas las demás posiciones de la secuencia de entrada. Este patrón "de todos con todos" posibilita un flujo de contexto bidireccional, donde cada token construye una representación informada por toda la secuencia.
Encoder architecture
Cada capa del codificador combina autoatención multi-cabeza con una red feed-forward aplicada por posición. La red feed-forward procesa cada posición de manera independiente pero idéntica, aplicando la misma transformación aprendida a todos los tokens.
Conexiones residuales y normalización por capas rodean ambos submódulos, estabilizando los gradientes y posibilitando arquitecturas más profundas. Al apilar varias capas del codificador se crean representaciones cada vez más abstractas, donde las capas tempranas capturan patrones superficiales y las más profundas codifican relaciones semánticas.
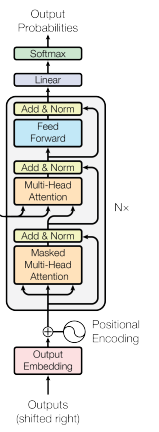
El decodificador modifica la autoatención para respetar las restricciones autorregresivas. Al generar texto, el modelo solo puede condicionarse en los tokens que ya ha producido. Mirar tokens futuros sería hacer trampas durante el entrenamiento.
Decoder architecture
La autoatención enmascarada lo consigue estableciendo pesos de atención en menos infinito (que tras el softmax se convierten en cero) para todas las posiciones posteriores a la actual.
Así se asegura que las predicciones dependan solo del contexto previo y se mantiene el orden causal necesario en tareas de generación. Durante la inferencia, esta causalidad es natural: sencillamente aún no tenemos tokens futuros a los que atender.
Entre las capas de autoatención del decodificador se encuentra la atención cruzada, que permite que el decodificador se condicione en las salidas del codificador. Aquí, las consultas provienen del decodificador (representan "lo que necesito generar"), mientras que las claves y valores provienen del codificador (representan "lo que ofrece la entrada").
Transformer architecture
Este mecanismo de atención cruzada es esencial en tareas de secuencia a secuencia como la traducción, donde el decodificador debe alinear palabras de salida con las palabras de entrada relevantes. A diferencia de la autoatención, la atención cruzada crea dependencias entre dos secuencias diferentes, permitiendo que la información fluya de origen a destino.
Más allá de la teoría, ¿qué ha permitido realmente la autoatención en la práctica? La respuesta es más amplia de lo que la mayoría espera.
Tras ver cómo funciona la autoatención dentro de un transformer, exploremos dónde ha tenido impacto en el mundo real.
Lo especialmente valioso de la autoatención es su carácter agnóstico al dominio. El mismo marco matemático que ayuda a los modelos a entender relaciones en lenguaje también puede captar patrones en imágenes, audio e incluso combinaciones de distintos tipos de datos.
En mi opinión, esta cualidad agnóstica al dominio es lo que hace realmente emocionante a la autoatención. Diría que es menos una herramienta de PLN y más un mecanismo general para aprender relaciones.
Los modelos transformer destacan capturando dependencias de largo alcance que las arquitecturas anteriores no lograban. En PLN, la autoatención impulsa modelos de vanguardia en prácticamente todas las tareas.
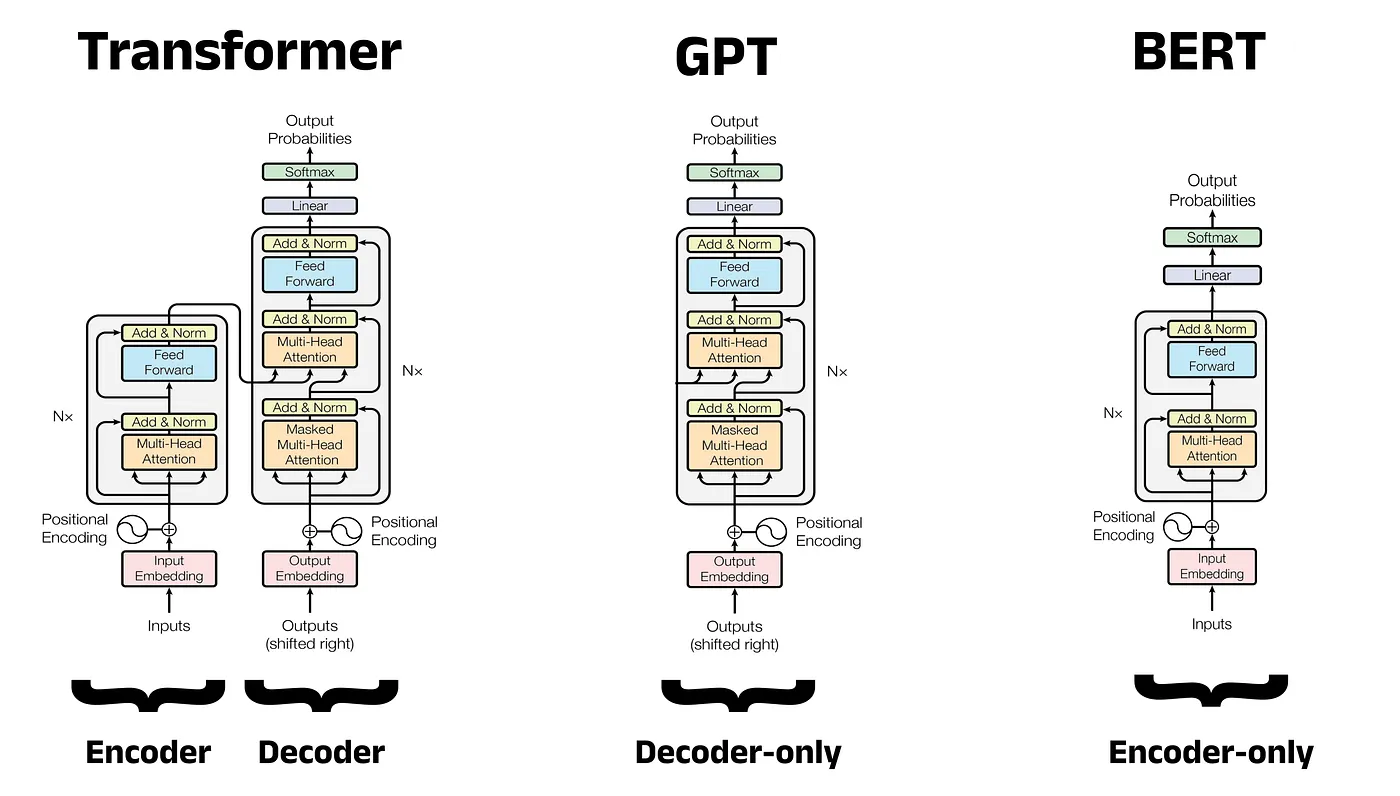
Como puedes ver en la imagen siguiente, la arquitectura de los modelos difiere según se centre en el decodificador o en el codificador.
Architecture comparison: Transformer vs. GPT vs. BERT
Modelos como BERT usan autoatención bidireccional en su arquitectura solo de codificador, lo que les permite construir representaciones contextuales ricas para tareas de clasificación y comprensión.
Los modelos GPT, como el recientemente publicado GPT-5.3 Codex, utilizan autoatención enmascarada en un diseño solo de decodificador, logrando capacidades de generación de texto sobresalientes.
T5 emplea la arquitectura completa de codificador-decodificador, tratando todas las tareas de PLN como problemas de texto a texto.
La adaptación Vision Transformer (ViT) llevó la autoatención a la visión por computador tratando las imágenes como secuencias de patches. En lugar de procesar píxeles mediante capas convolucionales, ViT divide las imágenes en patches de tamaño fijo (normalmente 16×16), aplana cada patch en un vector y procesa la secuencia con capas transformer.
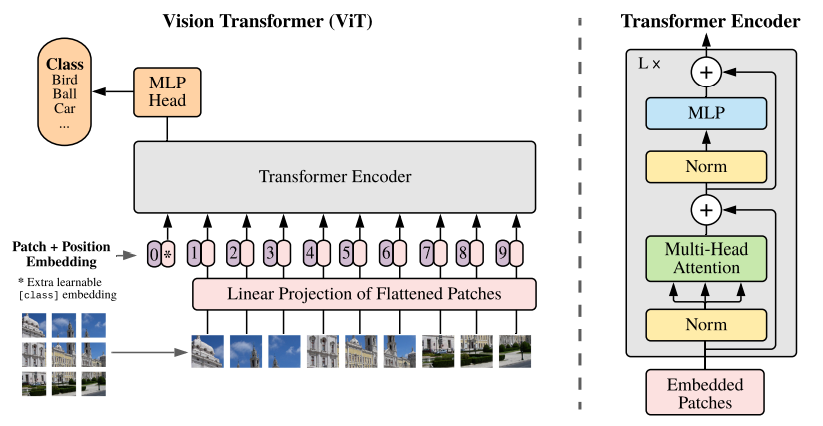
Este enfoque capta relaciones globales que los campos receptivos locales de las redes convolucionales podrían pasar por alto. ViT y sus variantes ya logran resultados de referencia en clasificación de imágenes, detección de objetos, segmentación semántica y otros ámbitos:
La utilidad de la autoatención se extiende al procesamiento del habla, donde capta dependencias temporales en secuencias de audio de forma más efectiva que los modelos recurrentes. En sistemas de recomendación, la autoatención ayuda a modelar los patrones de preferencia de los usuarios atendiendo a interacciones históricas relevantes.
Quizá lo más emocionante son las aplicaciones multimodales que combinan visión y lenguaje. Modelos como CLIP utilizan atención cruzada entre representaciones de imagen y texto, posibilitando clasificación de imágenes zero-shot y generación de imágenes a partir de descripciones textuales.
Todos estos sistemas tienen algo en común: demuestran la capacidad fundamental de la autoatención para aprender relaciones en cualquier dato secuencial o estructurado, independientemente de la modalidad.
Aunque la autoatención ha tenido un éxito notable en distintos dominios, surgen nuevos retos al desplegar modelos transformer a gran escala. A medida que los modelos crecen hasta miles de millones de parámetros y procesan contextos que se extienden a cientos de miles de tokens, el ancho de banda de memoria y los costes computacionales se convierten en cuellos de botella críticos.
El foco en el desarrollo de nuevos modelos está cada vez más en hacer la autoatención más rápida y eficiente sin sacrificar sus capacidades centrales. Esta tensión entre capacidad y eficiencia me parece uno de los problemas abiertos más interesantes del momento. Veamos algunos avances actuales.
La atención multi-cabeza estándar mantiene proyecciones de claves y valores separadas para cada cabeza, creando una sobrecarga de memoria considerable durante la inferencia. La atención multi-consulta (MQA) reduce esto compartiendo una única cabeza de claves-valores (KV) entre todas las cabezas de consulta, reduciendo drásticamente el tamaño de la caché KV y acelerando el decodificado. Sin embargo, MQA puede degradar la calidad.
La atención de consultas agrupadas (GQA) es un enfoque más equilibrado: divide las cabezas de consulta en grupos que comparten pares clave-valor. Con 32 cabezas de consulta y 8 grupos, cada grupo de 4 consultas comparte una cabeza KV. Por ejemplo, la familia de modelos Mistral 3 utiliza este enfoque y logra una calidad cercana a la de atención completa con ganancias de velocidad significativas.
Mientras GQA aborda la eficiencia de memoria, otra línea de investigación ataca el cuello de botella computacional fundamental de la atención desde otro ángulo.
Trabajos recientes exploran combinar autoatención con modelos de espacio de estados para mejorar la eficiencia. Sistemas como S4 y Hyena usan espacios de estados estructurados para modelar dependencias de largo alcance con complejidad lineal en lugar de cuadrática.
Estos enfoques abordan la limitación fundamental de la autoatención: el coste computacional escala de forma cuadrática con la longitud de la secuencia, haciendo prohibitivos los contextos extremadamente largos.
Más allá de reinventar la arquitectura, los investigadores también han encontrado formas ingeniosas de optimizar los mecanismos de atención existentes.
Además de los cambios arquitectónicos, avances recientes optimizan la atención durante la inferencia. La cuantización reduce la precisión de la caché KV a 8 o 4 bits, recortando drásticamente la memoria con una pérdida de calidad mínima.
Flash Attention reorganiza el acceso a la memoria de la GPU para minimizar el movimiento de datos, logrando aceleraciones de 2-3×. La optimización de cómputo en tiempo de prueba, donde los modelos realizan múltiples pasadas durante la generación, sugiere que una aplicación estratégica de la atención puede ofrecer mejores resultados que simplemente escalar el tamaño del modelo.
La autoatención es uno de los mecanismos más transformadores en la historia del aprendizaje automático. Al permitir que los modelos determinen dinámicamente a qué elementos de su entrada deben prestar atención, resolvió retos históricos a la hora de captar dependencias de largo alcance y procesar secuencias de forma eficiente.
La elegancia matemática de la atención por producto escalar escalado, potenciada por arquitecturas multi-cabeza, aporta solidez teórica y eficacia práctica.
Desde impulsar modelos de lenguaje de última generación hasta revolucionar la visión por computador y habilitar sistemas de IA multimodal, la autoatención sigue ampliando su alcance. Las innovaciones recientes en atención de consultas agrupadas, arquitecturas híbridas y optimización de la inferencia muestran que aún estamos encontrando formas de hacer este mecanismo más eficiente y capaz.
Si quieres profundizar y poner manos a la obra, te recomiendo inscribirte en nuestro itinerario de habilidades Developing Large Language Models.
Cursos sobre LLM
programa
Curso
Curso
blog
Abid Ali Awan
10 min
blog
Javier Canales Luna
10 min
blog
Abid Ali Awan
11 min
blog
Adel Nehme
15 min
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan



