

Programa
Desenvolvimento de modelos de idiomas grandes
16 h
No fim de 2017, um artigo de pesquisa intitulado Attention Is All You Need apresentou um mecanismo revolucionário que mudaria profundamente a inteligência artificial. No coração desse avanço estava o self-attention, uma ideia simples e poderosa que permite aos modelos entenderem relações dentro dos dados determinando quais elementos merecem mais foco.
Hoje, o self-attention impulsiona desde as habilidades de conversação do ChatGPT até sistemas avançados de reconhecimento de imagens. Sem dúvida, é uma das inovações mais transformadoras da história do machine learning.
Neste guia, vou mostrar o self-attention desde seus fundamentos conceituais até suas aplicações, explicando como o mecanismo ajuda os modelos a capturar dependências de longo alcance e processar informações em paralelo — capacidades que antes eram inalcançáveis com redes neurais tradicionais.
Se você é novo em transformers, considere fazer um dos nossos cursos introdutórios sobre Large Language Models (LLMs) Concepts e Transformer Models with PyTorch.
Pela minha experiência ensinando esse conceito, o melhor ponto de partida é um desafio fundamental no processamento de sequências: como um modelo consegue determinar quais partes da sua entrada são mais relevantes em cada momento?
Vamos começar pela intuição antes de entrar na matemática.
Self-attention é um mecanismo que pondera a importância dos diferentes elementos de uma sequência em relação uns aos outros. Ao processar a frase "The animal didn't cross the road because it was too tired", o self-attention ajuda o modelo a entender que "it" se refere a "animal" e não a "road", uma relação que se estende por várias palavras.
Esse é, na verdade, o exemplo que sempre uso ao apresentar o conceito para alunos. A compreensão é imediata porque espelha a forma como lemos naturalmente.
O que torna o self-attention especialmente poderoso é sua capacidade de calcular essas relações para todas as posições de uma sequência simultaneamente. Diferentemente das redes neurais recorrentes, que processam sequências passo a passo, o self-attention examina cada elemento em relação a todos os outros em uma única passada direta.
Esse processamento em paralelo reduz drasticamente o tempo de treino e captura dependências independentemente da distância entre os elementos na sequência.
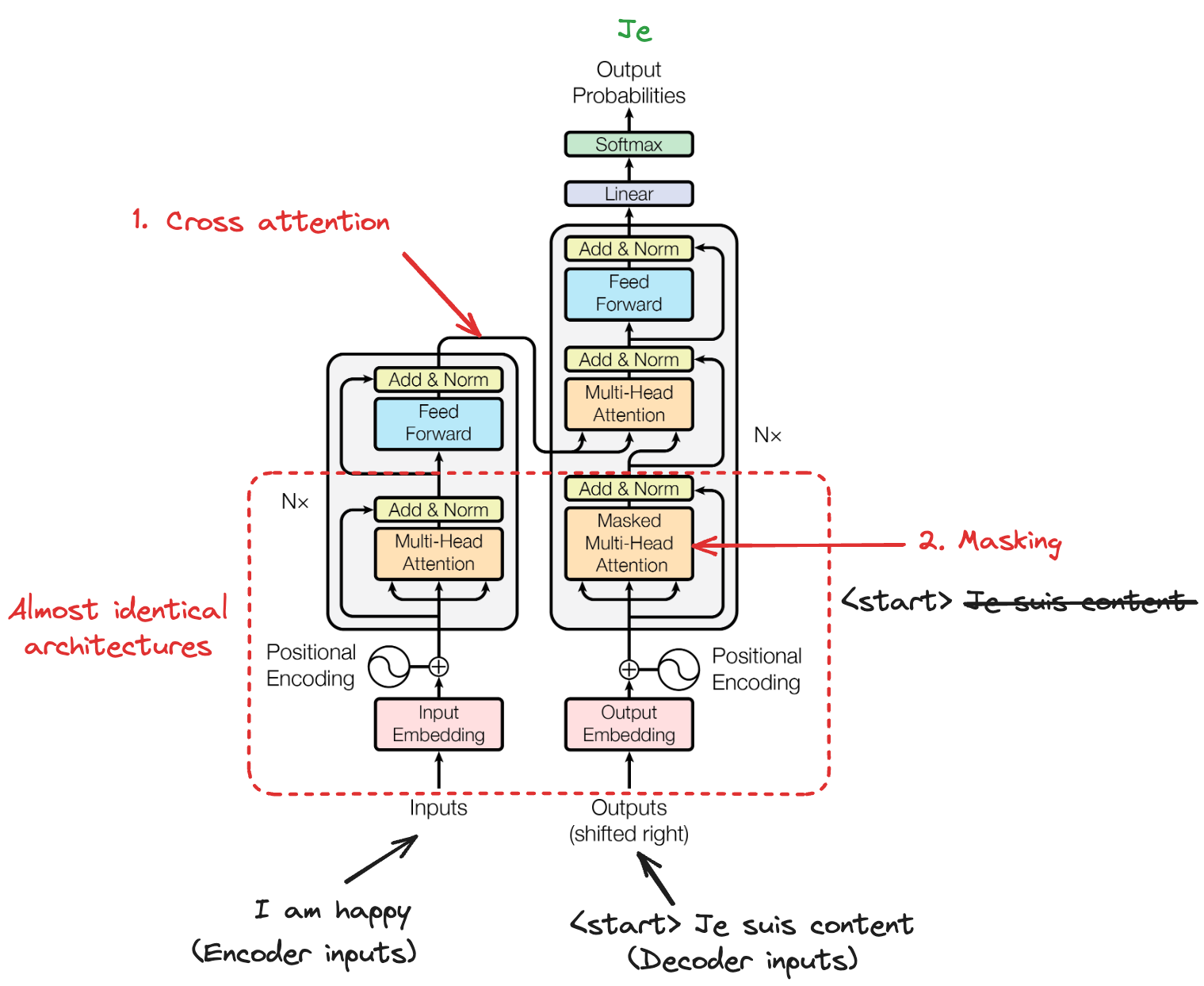
É importante diferenciar o self-attention de mecanismos relacionados. No self-attention, uma sequência "presta atenção" a si mesma. Cada elemento consulta informações de todas as posições dentro da mesma sequência.
Cross-attention, por sua vez, permite que uma sequência atenda a outra, como quando um decodificador consulta as saídas do codificador durante a tradução automática.
Masked self-attention adiciona uma restrição extra: impede que posições consultem posições seguintes, garantindo que as previsões dependam apenas do que já é conhecido — essencial para a geração autoregressiva de texto.
Mas de onde veio essa ideia e que problemas ela buscava resolver?
Antes do surgimento do self-attention, a área lidava com limitações significativas na modelagem de sequências.
Redes neurais recorrentes, incluindo LSTMs e GRUs, processam sequências de forma sequencial, criando um gargalo fundamental: elas sofriam para lidar com dependências de longo alcance porque a informação precisava atravessar muitos estados intermediários, levando a gradientes que desaparecem e perda de contexto.
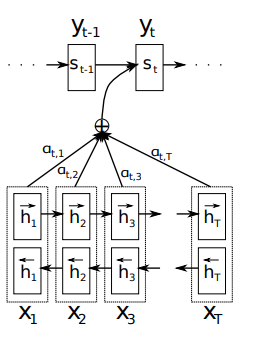
A evolução rumo ao self-attention começou com os mecanismos de atenção em arquiteturas encoder-decoder baseadas em RNN. Em 2014, Bahdanau e colegas apresentaram um mecanismo de atenção que permitia aos decodificadores acessar todos os estados ocultos do codificador, em vez de depender de um único vetor de contexto de tamanho fixo.
Esse avanço resolveu o problema da compressão de informação, em que sequências de entrada de tamanho variável eram espremidas em representações de tamanho fixo, independentemente da sua complexidade.
Bahdanau's graphical illustration of the proposed model
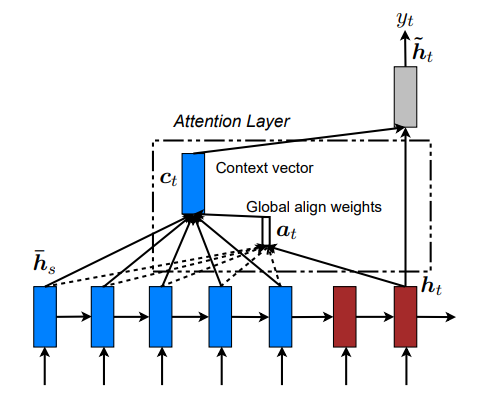
Um ano depois, Luong propôs mecanismos de atenção simplificados, incluindo a abordagem de produto interno escalonado que mais tarde influenciaria o design dos transformers. Embora esses mecanismos iniciais tenham melhorado o desempenho, ainda dependiam do processamento sequencial das RNNs.
Global attentional model (Luong)
A verdadeira revolução veio quando pesquisadores perguntaram: e se eliminássemos a recorrência e dependêssemos apenas da atenção? Essa pergunta levou à arquitetura transformer, na qual o self-attention se tornou o mecanismo principal para entender relações sequenciais.
Agora que entendemos por que o self-attention é importante, vamos ver como ele funciona matematicamente.
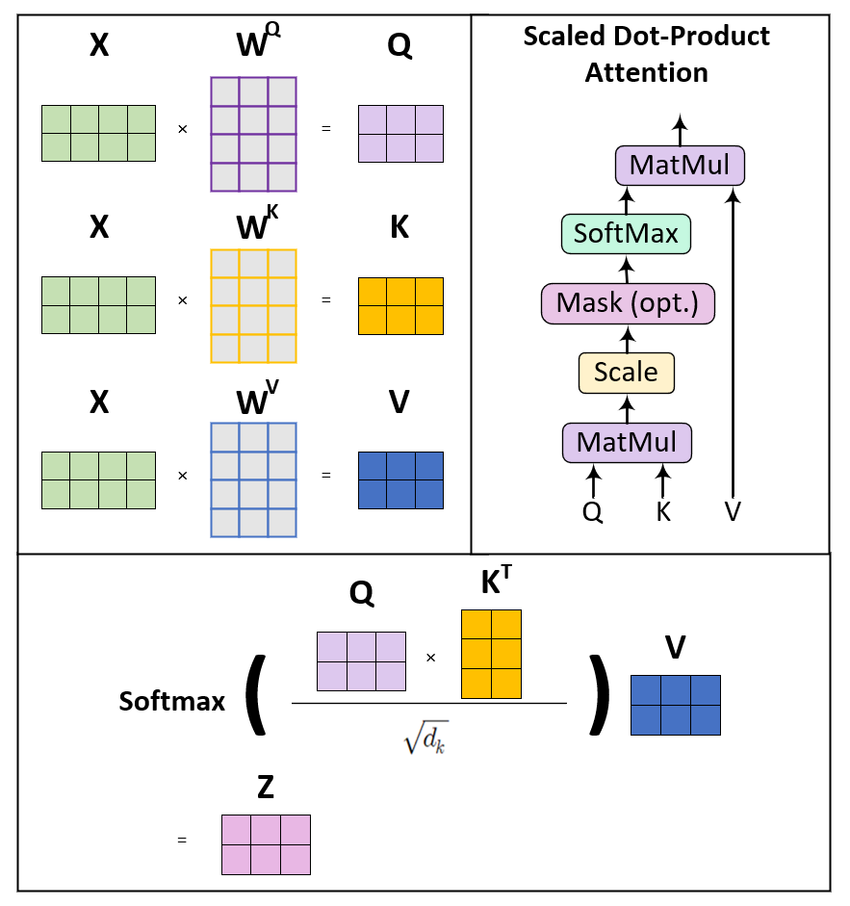
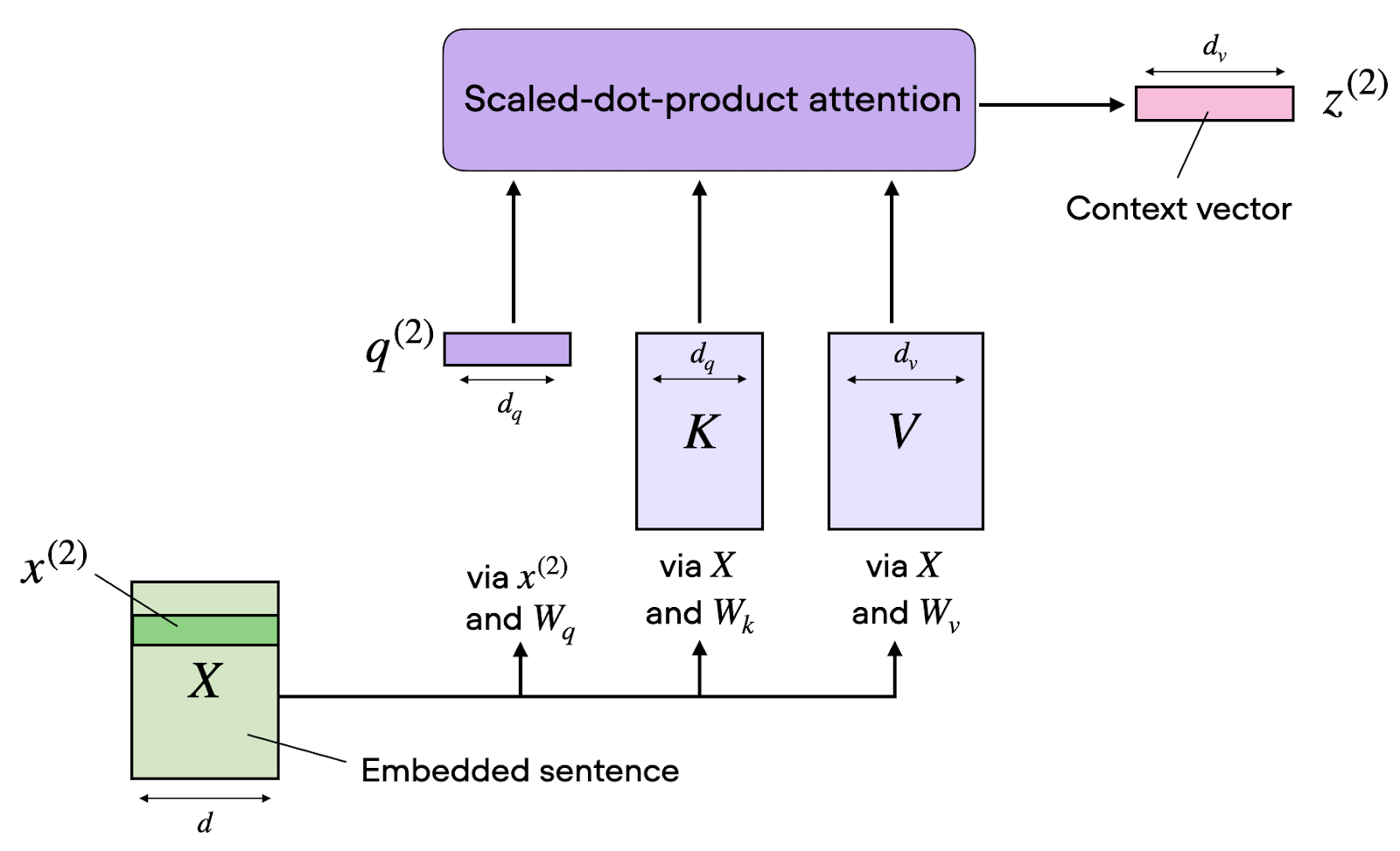
O self-attention transforma sequências de entrada por meio de três projeções aprendidas: queries, keys e values. Pense nelas como "visões" diferentes da mesma informação, cada uma com um papel específico no cálculo da atenção.
Para uma sequência de entrada com dimensão de embedding d_model, criamos três matrizes de pesos: W_Q, W_K e W_V. Ao multiplicarmos nossa matriz de entrada X por esses pesos, obtemos:
Matriz de query Q = X · W_Q: representa "o que estou procurando"
Matriz de key K = X · W_K: representa "o que eu ofereço"
Matriz de value V = X · W_V: representa "o que eu realmente contenho"
Gosto desta analogia com biblioteca: você entra com uma consulta em mente (query), os fichários são suas chaves (keys) e os livros de fato são os valores (values).
Normalmente, essas matrizes projetam para uma dimensão menor d_k (geralmente d_model dividido pelo número de cabeças de atenção), o que controla a complexidade computacional mantendo a capacidade de representação. Essa redução de dimensionalidade é especialmente importante ao escalar para sequências mais longas.
Com Q, K e V em mãos, podemos calcular a própria atenção.
O cálculo da atenção segue uma fórmula elegante. Primeiro, calculamos escores de atenção fazendo o produto interno entre queries e keys. Essa operação mede a compatibilidade entre o que cada posição procura e o que cada outra posição oferece.
Porém, à medida que a dimensionalidade aumenta, esses produtos podem crescer demais em magnitude, levando a função softmax para regiões com gradientes extremamente pequenos. Para evitar essa instabilidade numérica, escalonamos dividindo pela raiz quadrada da dimensão das keys.
Scaled dot-product attention
Esse fator de escala mantém a variância adequada ao longo da rede, garantindo gradientes estáveis durante o treino. Sem ele, modelos com embeddings de alta dimensão teriam dificuldade para aprender de forma eficaz, pois o softmax tenderia a distribuições quase one-hot que não distribuem a atenção de maneira significativa.
Antes de seguir, há uma lacuna importante a ser tratada: a codificação posicional.
Aqui está a parte que mais me surpreendeu quando estudei isso pela primeira vez: o self-attention é completamente invariante a permutação. Se você embaralhar os tokens de entrada, terá a mesma saída — apenas embaralhada de acordo.
Demorei um pouco para assimilar a implicação: o mecanismo é poderoso, mas essencialmente cego à ordem. Em tarefas em que a ordem importa (como entender linguagem), precisamos injetar explicitamente informação de posição.
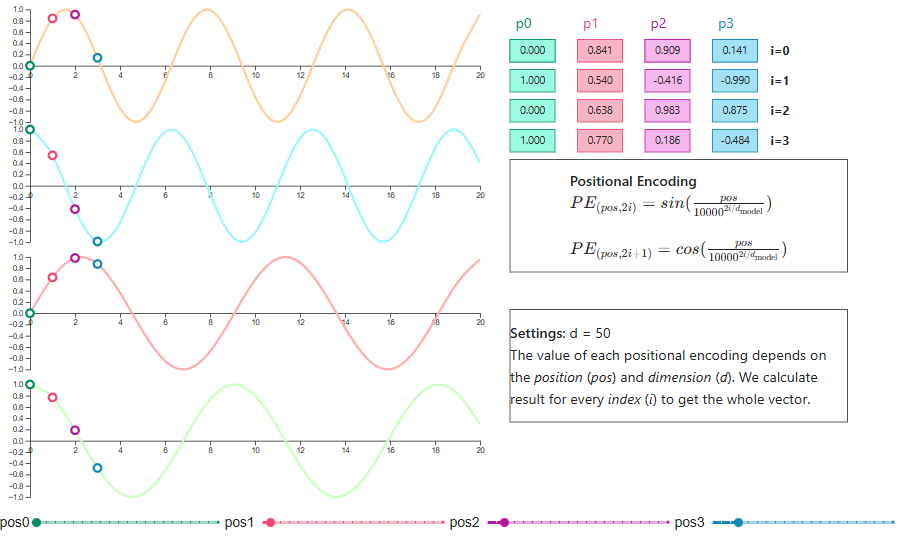
O transformer original usou codificações posicionais senoidais, aplicando funções seno e cosseno de diferentes frequências a cada dimensão. Essa escolha não foi aleatória. Os padrões ondulatórios permitem que os modelos aprendam a atender a posições relativas, e a codificação se estende naturalmente para comprimentos de sequência não vistos.
Positional encoding visualization
Inovações mais recentes incluem RoPE (Rotary Position Embedding), que rotaciona vetores de query e key em um espaço multidimensional por ângulos proporcionais às suas posições. Após a rotação, o produto interno entre queries e keys passa a codificar naturalmente a distância relativa.
O RoPE ganhou ampla adoção em modelos como o LLaMA devido à sua forte capacidade de extrapolação.
Outra abordagem, o ALiBi (Attention with Linear Biases), segue um caminho diferente ao adicionar penalidades dependentes da posição diretamente aos escores de atenção. Em vez de modificar embeddings, o ALiBi viésa os pesos de atenção para favorecer tokens próximos, com intensidade variando entre as diferentes cabeças.
Esse método demonstra extrapolação impressionante para comprimentos de sequência muito além dos vistos no treino.
Após calcular os escores de atenção escalonados, aplicamos a softmax ao longo da dimensão das keys. Essa normalização converte os escores brutos em uma distribuição de probabilidade, garantindo que os pesos de atenção somem 1 para cada posição de query.
A função softmax enfatiza as relações com maiores pontuações e suprime conexões irrelevantes. Contudo, isso às vezes pode levar a distribuições excessivamente agudas, especialmente no início do treino, quando o modelo ainda não aprendeu padrões de atenção mais sutis.
Para mitigar isso, é comum aplicar dropout aos pesos de atenção, zerando aleatoriamente algumas conexões para incentivar robustez.
Com os pesos de atenção, calculamos a saída final como uma soma ponderada dos vetores de value.
Cada posição recebe uma representação sensível ao contexto que agrega informações de toda a sequência, com contribuições proporcionais aos pesos de atenção. Essa combinação ponderada permite que a informação flua dinamicamente com base em relações aprendidas, e não em padrões fixos.
A atenção de uma única cabeça nos leva surpreendentemente longe, mas tem um teto. É aqui que a coisa fica mais interessante.
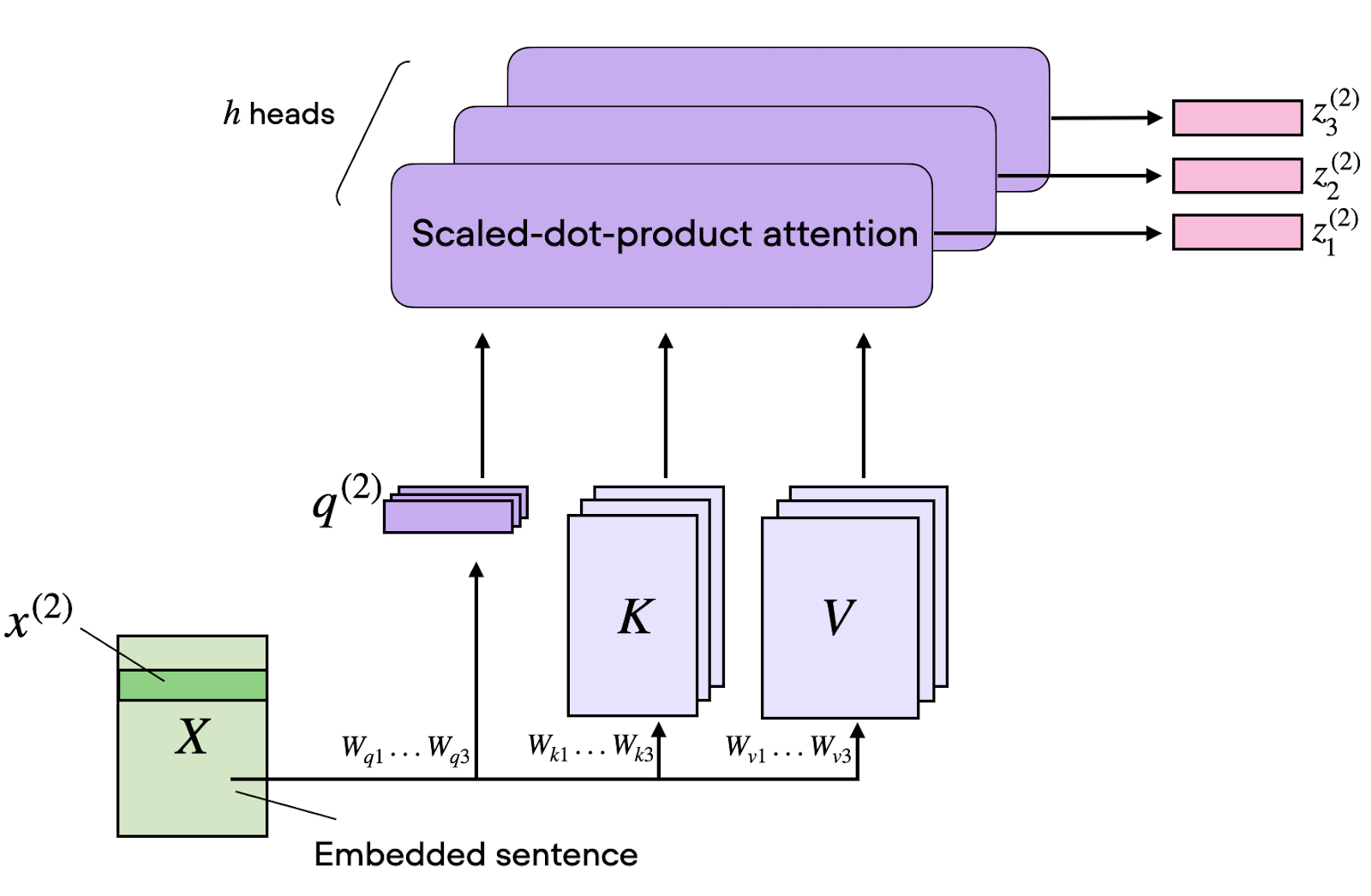
Embora a atenção de uma única cabeça seja poderosa, ela tem uma limitação fundamental: só consegue capturar um tipo de relação por vez.
Multi-head attention resolve isso executando várias atenções em paralelo, cada uma focada em aspectos diferentes das relações de entrada. Por exemplo, pode haver uma cabeça especializada em:
Pelo que observo trabalhando com esses modelos, essa especialização costuma emergir organicamente durante o treino. Você não a projeta — e isso, para mim, é uma das partes mais fascinantes de todo o mecanismo.
A implementação envolve dividir as matrizes Q, K e V ao longo da dimensão, processar cada divisão em cabeças de atenção separadas e concatenar os resultados.
Se temos 8 cabeças e embeddings de 512 dimensões, cada cabeça opera em subespaços de 64 dimensões. Esse processamento paralelo não aumenta a complexidade em função do comprimento da sequência, mas multiplica a capacidade do modelo de aprender padrões diversos.
Pesquisas sobre o que diferentes cabeças de atenção realmente aprendem revelaram padrões fascinantes.
Em modelos de tradução, algumas cabeças atendem consistentemente a relações posicionais, focando em palavras vizinhas independentemente do conteúdo. Outras se especializam em papéis sintáticos, identificando relações sujeito-verbo ou verbo-objeto. Uma terceira categoria foca em tokens raros ou com alta carga informacional, como nomes próprios e termos técnicos.
Curiosamente, estudos de interpretabilidade mostram que muitas cabeças parecem redundantes, e os modelos mantêm o desempenho mesmo quando uma fração significativa delas é removida. Essa redundância provavelmente contribui para a robustez, garantindo múltiplos caminhos para padrões críticos na rede.
Em atenção encoder-decoder, cabeças nas camadas mais tardias do decodificador são as mais essenciais para a qualidade da tradução, enquanto cabeças de self-attention no codificador muitas vezes podem ser bastante reduzidas.
Com os fundamentos matemáticos estabelecidos, vamos ver como o self-attention se integra à arquitetura completa do transformer.
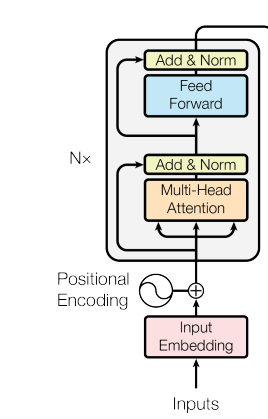
No codificador do transformer, camadas de self-attention permitem que cada posição atenda a todas as outras posições na sequência de entrada. Esse padrão "todos com todos" permite fluxo de contexto bidirecional, em que cada token constrói uma representação informada pela sequência inteira.
Encoder architecture
Cada camada do codificador combina multi-head self-attention com uma rede feed-forward por posição. A rede feed-forward processa cada posição de forma independente, porém idêntica, aplicando a mesma transformação aprendida a todos os tokens.
Conexões residuais e normalização por camada envolvem ambos os submódulos, estabilizando os gradientes e permitindo arquiteturas mais profundas. Empilhar várias camadas de codificador cria representações cada vez mais abstratas, com camadas iniciais capturando padrões de superfície e camadas profundas codificando relações semânticas.
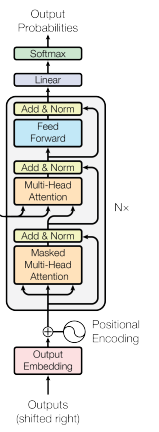
O decodificador modifica o self-attention para respeitar restrições autoregressivas. Ao gerar texto, o modelo só pode se basear nos tokens que já produziu. Espiar tokens futuros seria "colar" durante o treino.
Decoder architecture
O masked self-attention faz isso definindo os pesos de atenção como menos infinito (que vira zero após o softmax) para todas as posições posteriores à posição atual.
Isso garante que as previsões dependam apenas do contexto anterior e mantém a ordenação causal necessária para tarefas de geração. Durante a inferência, essa causalidade é natural: simplesmente ainda não temos tokens futuros para consultar.
Entre as camadas de self-attention do decodificador fica o cross-attention, que permite ao decodificador se condicionar às saídas do codificador. Aqui, as queries vêm do decodificador (representando "o que preciso gerar"), enquanto keys e values vêm do codificador (representando "o que a entrada fornece").
Transformer architecture
Esse mecanismo de cross-attention é essencial para tarefas sequência a sequência, como tradução, nas quais o decodificador precisa alinhar palavras de saída às palavras relevantes da entrada. Diferentemente do self-attention, o cross-attention cria dependências entre duas sequências diferentes, permitindo que a informação flua da origem ao destino.
Teoria à parte, o que o self-attention realmente viabilizou na prática? A resposta é mais ampla do que muita gente imagina.
Depois de explorar como o self-attention funciona dentro da arquitetura transformer, vamos ver onde esse mecanismo tem impacto no mundo real.
O que torna o self-attention particularmente valioso é sua natureza indiferente a domínio. A mesma estrutura matemática que ajuda modelos a entenderem relações na linguagem também captura padrões em imagens, áudio e até combinações de diferentes tipos de dados.
Na minha visão, essa versatilidade é o que torna o self-attention realmente empolgante. Eu diria que ele é menos uma ferramenta de PLN e mais um mecanismo geral de aprendizado de relações.
Modelos transformer se destacam em capturar dependências de longo alcance que arquiteturas anteriores perdiam. Em PLN, o self-attention impulsiona modelos de ponta em praticamente todas as tarefas.
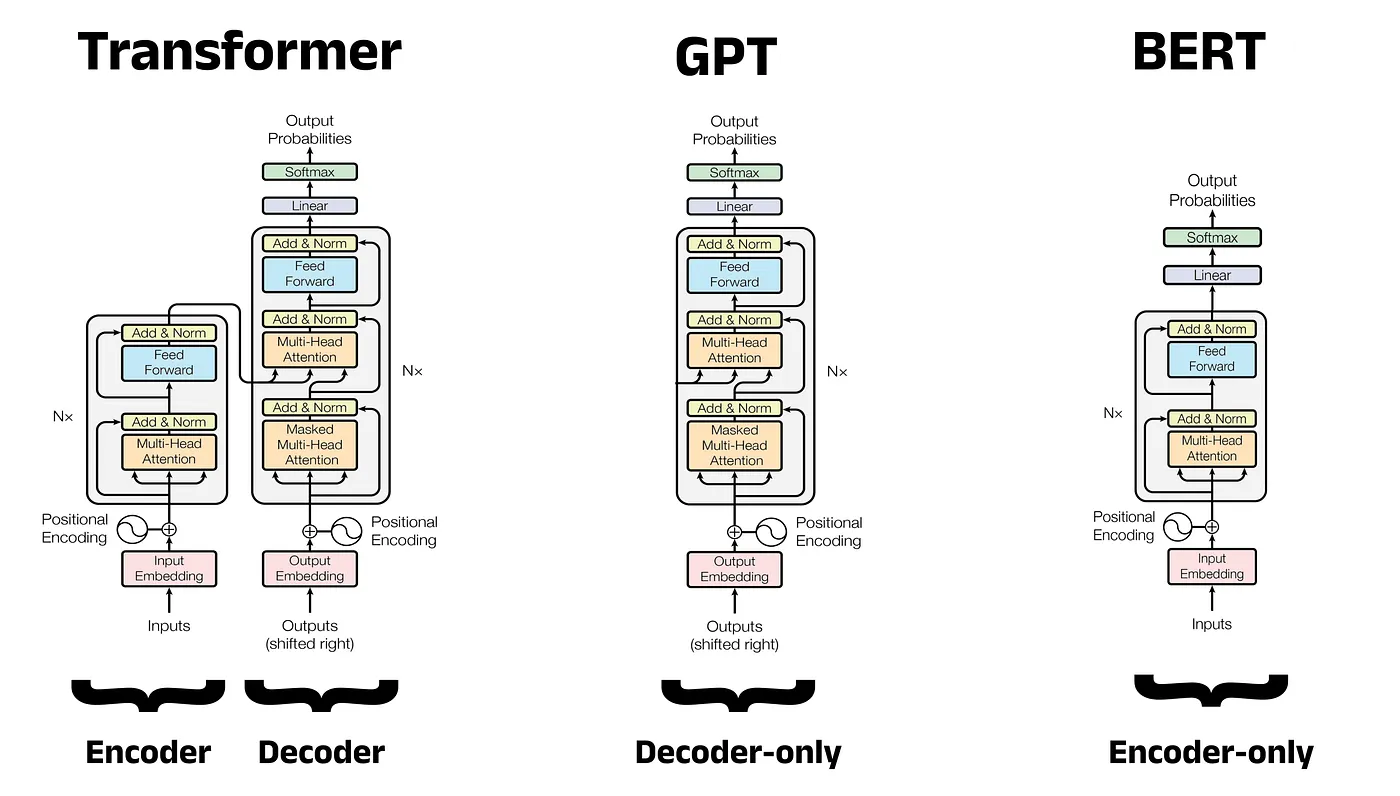
Como você vê na imagem abaixo, a arquitetura dos modelos difere conforme o foco é no decodificador ou no codificador.
Architecture comparison: Transformer vs. GPT vs. BERT
Modelos como o BERT usam self-attention bidirecional em uma arquitetura apenas com codificador, permitindo construir representações contextuais ricas para tarefas de classificação e entendimento.
Modelos GPT, como o recém-lançado GPT-5.3 Codex, usam self-attention mascarado em um design apenas com decodificador, alcançando capacidades impressionantes de geração de texto.
O T5 emprega a arquitetura completa encoder-decoder do transformer, tratando todas as tarefas de PLN como problemas de texto para texto.
A adaptação Vision Transformer (ViT) levou o self-attention à visão computacional ao tratar imagens como sequências de patches. Em vez de processar pixels por camadas convolucionais, o ViT divide imagens em patches de tamanho fixo (geralmente 16×16), achata cada patch em um vetor e processa a sequência em camadas de transformer.
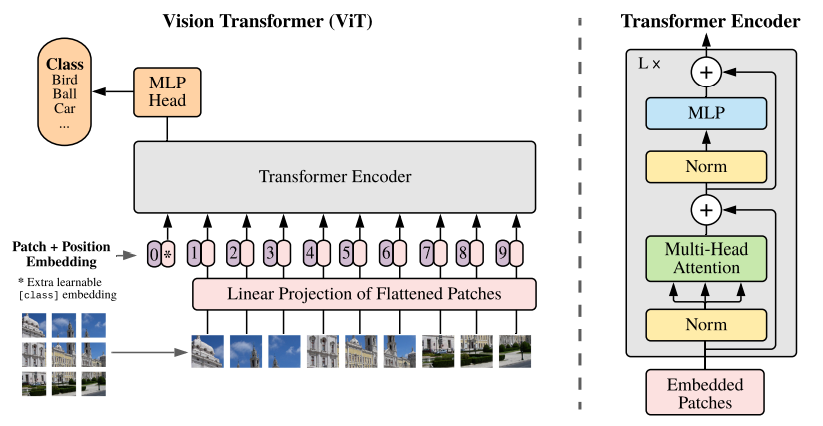
Essa abordagem captura relações globais que os campos receptivos locais das redes convolucionais podem perder. O ViT e suas variantes hoje alcançam resultados de ponta em classificação de imagens, detecção de objetos, segmentação semântica e outras áreas:
A utilidade do self-attention se estende ao processamento de fala, onde ele captura dependências temporais em sequências de áudio de forma mais eficaz que modelos recorrentes. Em recomendações, o self-attention ajuda a modelar padrões de preferência de usuários ao focar em interações históricas relevantes.
Talvez as mais empolgantes sejam as aplicações multimodais que combinam visão e linguagem. Modelos como o CLIP usam cross-attention entre representações de imagem e texto, possibilitando classificação de imagens em zero-shot e geração de imagens a partir de descrições de texto.
O que todos esses sistemas têm em comum: eles demonstram a capacidade fundamental do self-attention de aprender relações entre qualquer dado sequencial ou estruturado, independentemente da modalidade.
Embora o self-attention tenha sido notavelmente bem-sucedido em vários domínios, novos desafios surgem ao implantar transformers em grande escala. À medida que os modelos chegam a bilhões de parâmetros e processam contextos que alcançam centenas de milhares de tokens, a largura de banda de memória e os custos computacionais viram gargalos críticos.
O foco no desenvolvimento de novos modelos está cada vez mais em tornar o self-attention mais rápido e eficiente sem perder suas capacidades centrais. Acho essa tensão entre capacidade e eficiência um dos problemas em aberto mais interessantes hoje. Vamos dar uma olhada em alguns desenvolvimentos atuais.
A multi-head attention padrão mantém projeções de key e value separadas para cada cabeça, criando uma sobrecarga substancial de memória na inferência. A multi-query attention (MQA) reduz isso compartilhando uma única cabeça de key-value (KV) entre todas as cabeças de query, diminuindo drasticamente o cache KV e acelerando a decodificação. No entanto, a MQA pode degradar a qualidade.
Grouped-query attention (GQA) é uma abordagem mais equilibrada, dividindo cabeças de query em grupos que compartilham pares key-value. Com 32 cabeças de query e 8 grupos, cada grupo de 4 queries compartilha uma cabeça de key-value. Por exemplo, a família de modelos Mistral 3 usa essa abordagem e consegue atingir qualidade próxima à atenção completa com ganhos significativos de velocidade.
Enquanto a GQA aborda eficiência de memória, outra linha de pesquisa ataca o gargalo computacional fundamental da atenção por outro ângulo.
Trabalhos recentes exploram combinar self-attention com modelos de espaço de estado para melhorar a eficiência. Sistemas como S4 e Hyena usam espaços de estado estruturados para modelar dependências de longo alcance com complexidade linear, e não quadrática.
Essas abordagens enfrentam a limitação fundamental do self-attention: o custo computacional escala quadraticamente com o comprimento da sequência, tornando contextos extremamente longos proibitivamente caros.
Além de reimaginar a própria arquitetura, pesquisadores também encontraram formas engenhosas de otimizar os mecanismos de atenção existentes.
Para além das mudanças arquiteturais, avanços recentes otimizam a atenção durante a inferência. A quantização reduz a precisão do cache KV para 8 ou 4 bits, cortando drasticamente a memória com perda mínima de qualidade.
Flash Attention reorganiza o acesso à memória da GPU para minimizar movimentação de dados, alcançando acelerações de 2 a 3 vezes. Otimizações de computação em tempo de teste, em que os modelos realizam múltiplas passagens durante a geração, sugerem que uma aplicação estratégica de atenção pode trazer resultados melhores do que apenas escalar o tamanho do modelo.
Self-attention é um dos mecanismos mais transformadores da história do machine learning. Ao permitir que os modelos determinem dinamicamente quais elementos da entrada merecem foco, ele resolveu desafios antigos de capturar dependências de longo alcance e processar sequências com eficiência.
A elegância matemática da atenção por produto interno escalonado, aprimorada por arquiteturas multi-head, oferece solidez teórica e eficácia prática.
Do impulso aos modelos de linguagem mais avançados à revolução na visão computacional e ao habilitar sistemas de IA multimodais, o self-attention continua ampliando seu alcance. Inovações recentes em grouped-query attention, arquiteturas híbridas e otimizações de inferência mostram que ainda estamos descobrindo formas de tornar esse mecanismo mais eficiente e capaz.
Se você quer mergulhar nos detalhes e colocar a mão na massa, recomendo se inscrever na nossa trilha de habilidades Developing Large Language Models.
Cursos de LLM
Programa
Curso
Curso
blog
blog
Abid Ali Awan
11 min
blog
Adel Nehme
15 min
blog
Hesam Sheikh Hassani
15 min
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer

