

Cursus
Développer des LLM
16 h
Fin 2017, un article de recherche intitulé Attention Is All You Need a introduit un mécanisme révolutionnaire qui allait reconfigurer en profondeur l’intelligence artificielle. Au cœur de cette avancée se trouvait la self-attention, une idée simple mais puissante qui permet aux modèles de comprendre les relations au sein des données en déterminant quels éléments méritent l’attention.
Aujourd’hui, la self-attention alimente aussi bien les capacités conversationnelles de ChatGPT que des systèmes avancés de reconnaissance d’images. C’est sans conteste l’une des innovations les plus transformatrices de l’histoire de l’apprentissage automatique.
Dans ce guide, je vous accompagne des bases conceptuelles jusqu’aux applications concrètes, pour montrer comment ce mécanisme aide les modèles à capturer des dépendances à longue portée et à traiter l’information en parallèle — des capacités autrefois hors d’atteinte avec les réseaux de neurones traditionnels.
Si vous découvrez les transformers, pensez à suivre nos cours d’introduction Large Language Models (LLMs) Concepts et Transformer Models with PyTorch.
D’après mon expérience d’enseignement, le meilleur point de départ est un défi fondamental du traitement de séquences : comment un modèle peut-il déterminer, à chaque instant, quelles parties de son entrée sont les plus pertinentes ?
Commençons par l’intuition avant de plonger dans les mathématiques.
La self-attention est un mécanisme qui pondère l’importance des différents éléments d’une séquence les uns par rapport aux autres. Lorsqu’il traite la phrase « The animal didn’t cross the road because it was too tired », le modèle, grâce à la self-attention, comprend que « it » renvoie à « animal » et non à « road », une relation qui s’étend sur plusieurs mots.
C’est d’ailleurs l’exemple que j’utilise systématiquement pour présenter le concept aux apprenants. Il fait immédiatement sens car il reflète notre manière naturelle de lire.
La force de la self-attention tient à sa capacité à calculer ces relations pour toutes les positions d’une séquence simultanément. Contrairement aux réseaux récurrents, qui traitent les séquences pas à pas, la self-attention examine chaque élément par rapport à tous les autres en un seul passage avant.
Ce calcul parallèle réduit considérablement le temps d’entraînement tout en capturant les dépendances, quelle que soit leur distance dans la séquence.
Il est important de distinguer la self-attention des mécanismes voisins. En self-attention, une séquence s’attend elle-même : chaque élément interroge toutes les positions de cette même séquence.
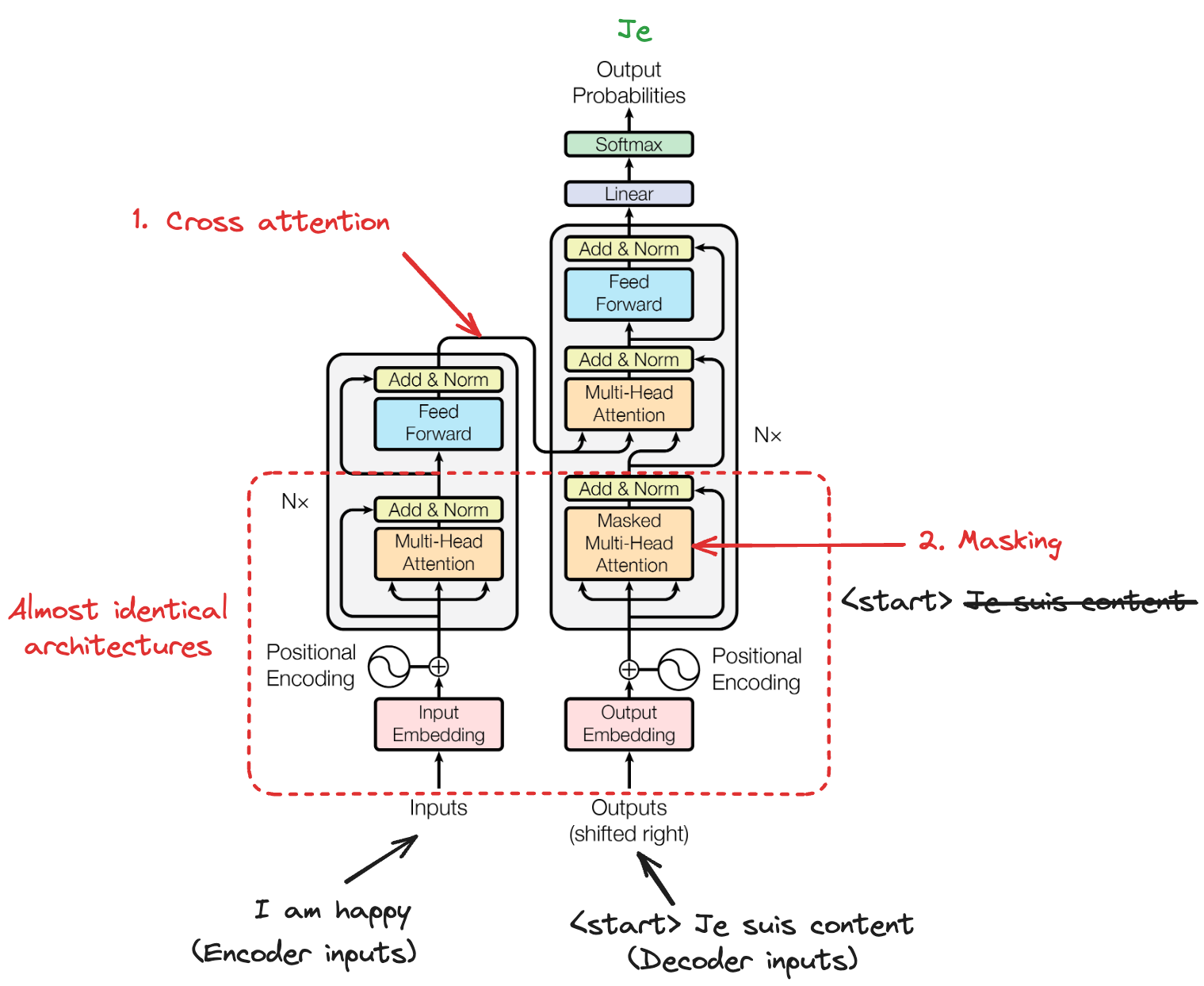
La cross-attention, à l’inverse, permet à une séquence d’en « attendre » une autre, comme lorsqu’un décodeur s’appuie sur les sorties de l’encodeur en traduction automatique.
La self-attention masquée ajoute une contrainte supplémentaire : elle empêche chaque position de regarder les positions suivantes, garantissant que les prédictions ne dépendent que des sorties déjà connues — indispensable pour la génération de texte autorégressive.
Mais d’où vient réellement cette idée et quels problèmes cherchait-elle à résoudre ?
Avant l’émergence de la self-attention, le domaine se heurtait à d’importantes limites dans la modélisation de séquences.
Les réseaux de neurones récurrents, y compris les LSTM et GRU, traitent les séquences de manière séquentielle, ce qui crée un goulet d’étranglement : ils peinent à capturer les dépendances à longue portée, car l’information doit traverser de nombreux états intermédiaires, provoquant des gradients évanescents et une perte de contexte.
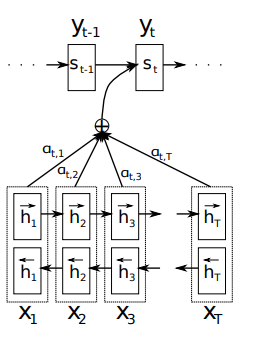
L’évolution vers la self-attention a commencé avec les mécanismes d’attention dans les architectures encodeur-décodeur basées sur des RNN. En 2014, Bahdanau et ses collègues ont introduit un mécanisme d’attention permettant aux décodeurs d’accéder à l’ensemble des états cachés de l’encodeur, plutôt que de s’en remettre à un seul vecteur de contexte de longueur fixe.
Cette avancée a résolu le problème de compression de l’information, où des séquences d’entrée de longueur variable étaient comprimées dans des représentations de longueur fixe, quelle que soit leur complexité.
Schéma de Bahdanau du modèle proposé
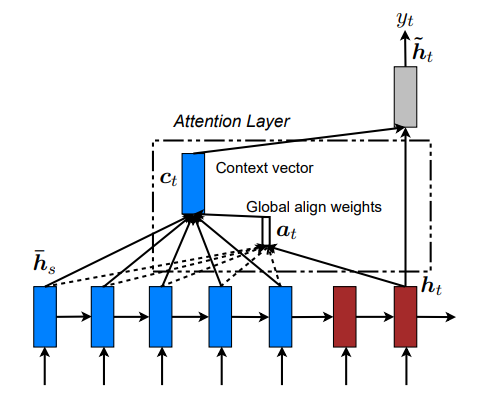
Un an plus tard, Luong a proposé des mécanismes d’attention simplifiés, dont l’approche par produit scalaire « scaled » qui influencera plus tard la conception des transformers. Si ces premières attentions amélioraient les performances, elles dépendaient encore du traitement séquentiel des RNN.
Modèle attentionnel global (Luong)
La véritable révolution a eu lieu lorsque les chercheurs ont posé la question suivante : et si l’on supprimait toute récurrence pour ne s’appuyer que sur l’attention ? Cette question a conduit à l’architecture transformer, où la self-attention est devenue le mécanisme central de compréhension des relations séquentielles.
Maintenant que nous avons clarifié l’intérêt de la self-attention, voyons comment elle fonctionne mathématiquement.
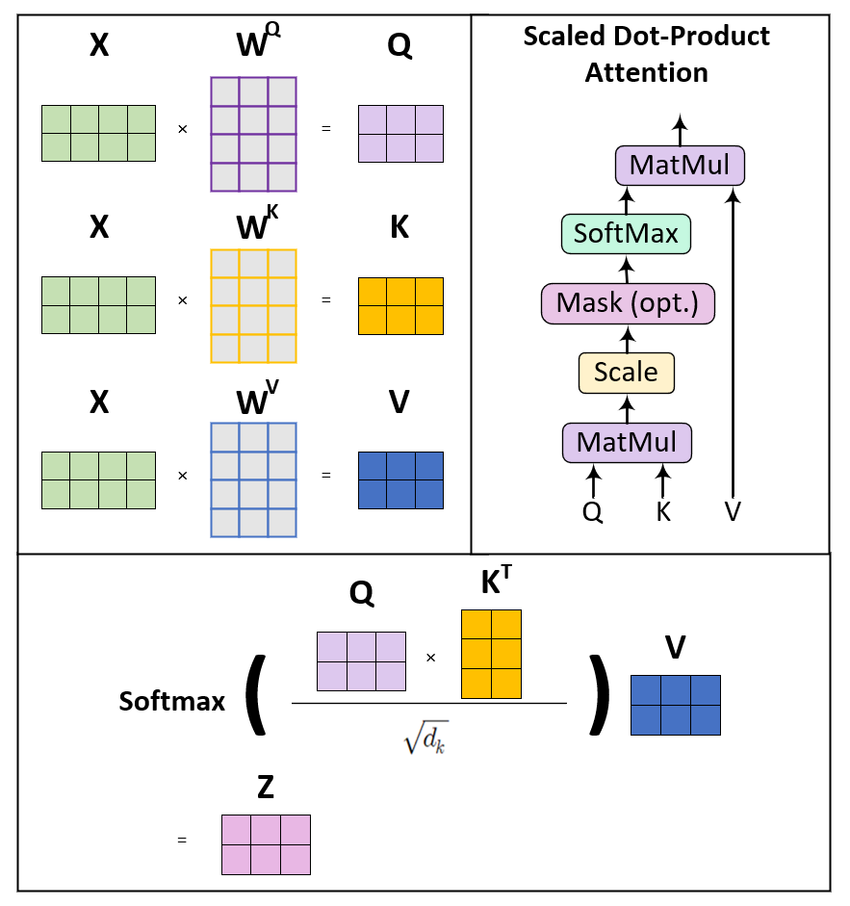
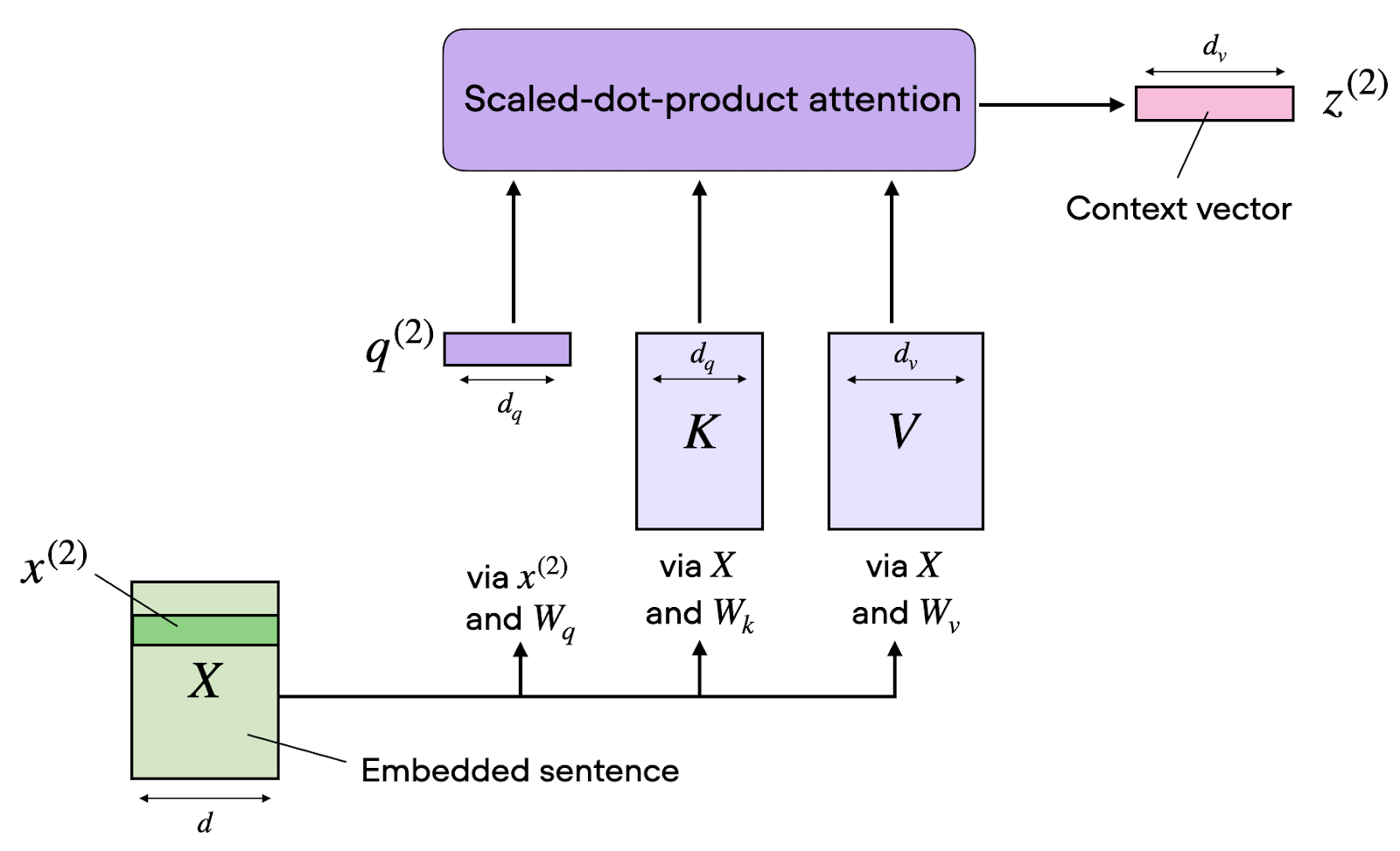
La self-attention transforme les séquences d’entrée via trois projections apprises : requêtes (queries), clés (keys) et valeurs (values). Considérez-les comme trois « vues » d’une même information, chacune jouant un rôle distinct dans le calcul de l’attention.
Pour une séquence d’entrée de dimension d’intégration d_model, on crée trois matrices de poids : W_Q, W_K et W_V. En multipliant la matrice d’entrée X par ces poids, on obtient :
Matrice des requêtes Q = X · W_Q : représente « ce que je recherche »
Matrice des clés K = X · W_K : représente « ce que je propose »
Matrice des valeurs V = X · W_V : représente « ce que je contiens réellement »
J’aime l’analogie avec une bibliothèque : vous entrez avec une requête en tête, les fiches d’index sont les clés, et les livres eux-mêmes sont les valeurs.
Ces matrices projettent généralement vers une dimension plus petite d_k (souvent d_model divisé par le nombre de têtes d’attention), ce qui maîtrise la complexité de calcul tout en préservant la capacité de représentation. Cette réduction dimensionnelle devient particulièrement importante lorsqu’on passe à des séquences plus longues.
Une fois Q, K et V obtenues, nous pouvons calculer l’attention.
Le calcul de l’attention suit une formule élégante. On calcule d’abord des scores d’attention en prenant le produit scalaire entre requêtes et clés. Cette opération mesure la compatibilité entre ce que chaque position recherche et ce que chaque autre position propose.
Cependant, à mesure que la dimension augmente, ces produits scalaires peuvent devenir très grands, poussant la fonction softmax dans des régions où les gradients sont infimes. Pour éviter cette instabilité numérique, on divise par la racine carrée de la dimension des clés.
Scaled dot-product attention
Ce facteur d’échelle maintient une variance appropriée dans le réseau et assure des gradients stables pendant l’entraînement. Sans lui, les modèles à forts embeddings auraient du mal à apprendre, car le softmax produirait des distributions quasi « one‑hot » qui ne répartissent pas l’attention de manière utile.
Avant d’aller plus loin, il reste un point crucial : le codage positionnel.
Voici ce qui m’a le plus surpris en étudiant le sujet : la self-attention est totalement invariante par permutation. Si vous mélangez les jetons d’entrée, vous obtenez la même sortie, simplement réordonnée en conséquence.
J’ai mis un moment à en saisir la portée : le mécanisme est puissant, mais aveugle à l’ordre. Pour les tâches où l’ordre compte (comme la compréhension du langage), il faut injecter explicitement l’information positionnelle.
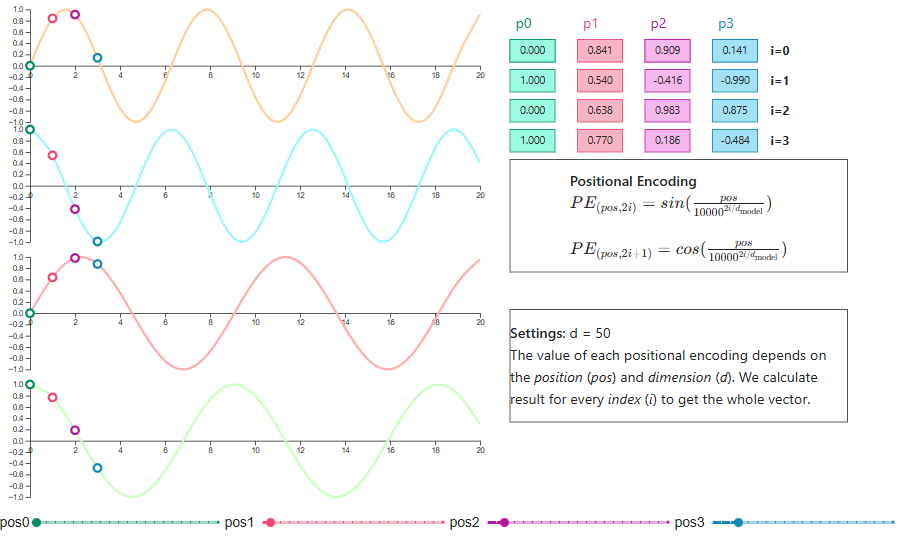
Le transformer d’origine utilise des encodages positionnels sinusoïdaux, appliquant des fonctions sinus et cosinus de fréquences différentes à chaque dimension. Ce choix n’était pas arbitraire : ces motifs ondulatoires permettent au modèle d’apprendre les positions relatives, et l’encodage s’étend naturellement à des longueurs de séquence non vues à l’entraînement.
Visualisation de l’encodage positionnel
Parmi les innovations récentes, RoPE (Rotary Position Embedding) applique une rotation des vecteurs de requêtes et de clés dans un espace multidimensionnel selon des angles proportionnels à leur position. Après rotation, le produit scalaire entre requêtes et clés encode naturellement la distance relative.
RoPE est largement adopté dans des modèles comme LLaMA en raison de ses excellentes capacités d’extrapolation.
Une autre approche, ALiBi (Attention with Linear Biases), suit une voie différente en ajoutant directement des pénalités dépendantes de la position aux scores d’attention. Plutôt que de modifier les embeddings, ALiBi biaise les poids d’attention pour favoriser les jetons proches, avec une intensité qui varie selon les têtes d’attention.
Cette méthode montre une extrapolation impressionnante vers des longueurs de séquence bien supérieures à celles vues à l’entraînement.
Après le calcul des scores d’attention « scaled », on applique la softmax sur la dimension des clés. Cette normalisation transforme les scores bruts en une distribution de probabilités, garantissant que les poids d’attention de chaque position de requête somment à un.
La fonction softmax met en avant les relations les mieux scorées et atténue les connexions non pertinentes. Mais elle peut conduire à des distributions trop « pointues », surtout au début de l’entraînement lorsque le modèle n’a pas encore appris de schémas d’attention nuancés.
Pour y remédier, on applique souvent du dropout sur les poids d’attention, en annulant aléatoirement certaines connexions pour renforcer la robustesse.
Une fois les poids d’attention obtenus, on calcule la sortie finale comme une combinaison linéaire pondérée des vecteurs de valeurs.
Chaque position reçoit une représentation contextuelle qui agrège l’information sur l’ensemble de la séquence, avec des contributions proportionnelles aux poids d’attention. Cette combinaison pondérée permet à l’information de circuler de manière dynamique selon les relations apprises, plutôt que selon des schémas figés.
L’attention monocéphale va étonnamment loin, mais elle atteint vite ses limites. C’est là que les choses deviennent plus intéressantes.
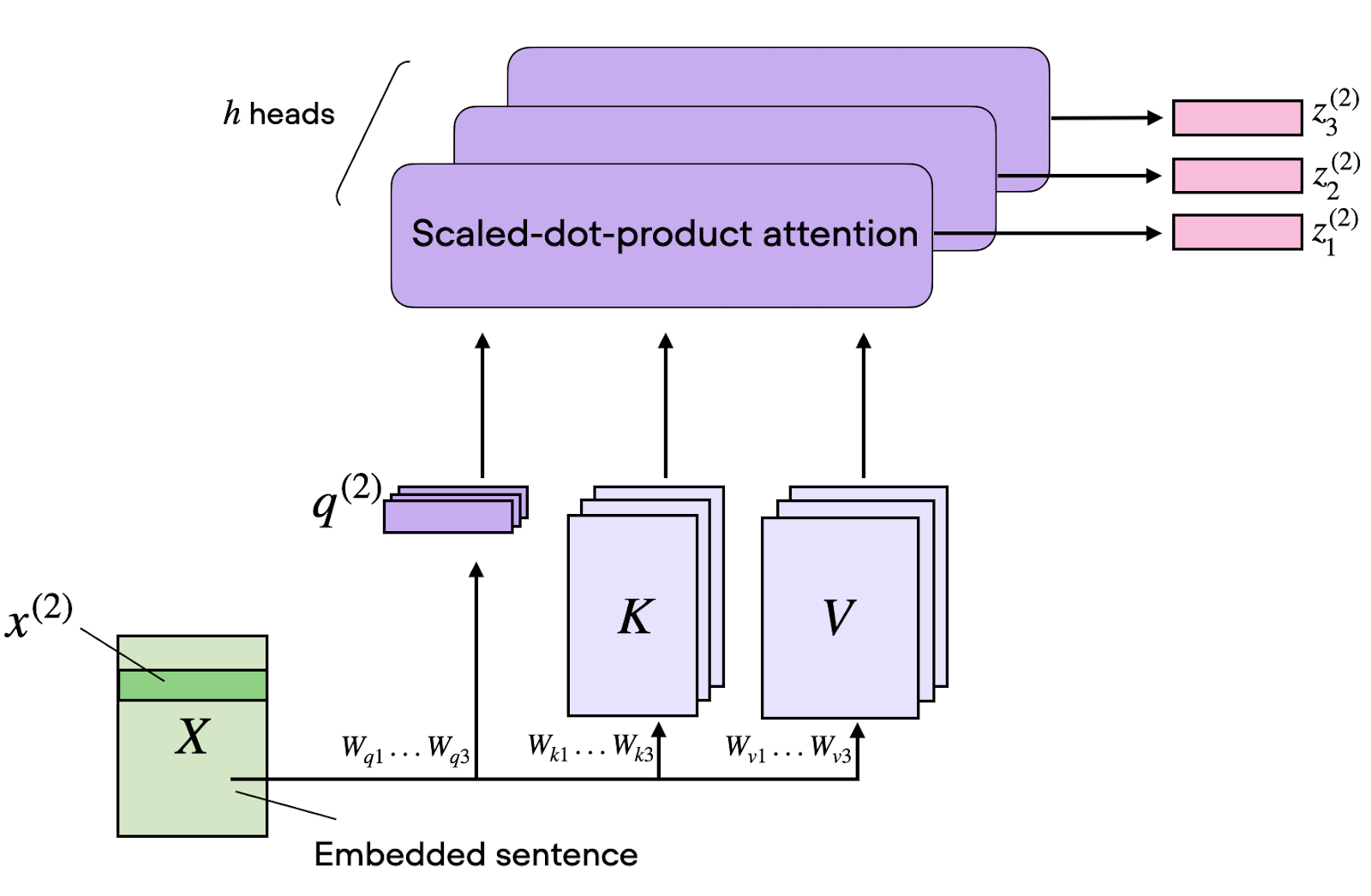
Si l’attention à une seule tête est puissante, elle présente une limite fondamentale : elle ne peut capturer qu’un seul type de relation à la fois.
L’attention multi-têtes contourne cette limite en exécutant en parallèle plusieurs calculs d’attention, chacun se concentrant sur des aspects différents des relations d’entrée. Par exemple, une tête peut se spécialiser dans :
D’après ce que j’ai observé en pratique, cette spécialisation émerge souvent d’elle-même pendant l’entraînement. Vous ne la concevez pas explicitement — et c’est, à mon sens, l’un des aspects les plus fascinants du mécanisme.
Concrètement, on scinde les matrices Q, K et V selon la dimension, on traite chaque sous-partie dans une tête d’attention distincte, puis on concatène les résultats.
Si l’on dispose de 8 têtes et d’embeddings de dimension 512, chaque tête opère dans un sous-espace de 64 dimensions. Ce traitement parallèle n’augmente pas la complexité liée à la longueur de séquence, mais il multiplie la capacité du modèle à apprendre des schémas variés.
Les recherches sur ce que les différentes têtes apprennent révèlent des motifs fascinants.
Dans les modèles de traduction, certaines têtes s’attachent aux relations positionnelles, en se concentrant sur les mots voisins quel que soit le contenu. D’autres se spécialisent dans les rôles syntaxiques, identifiant les relations sujet–verbe ou verbe–objet. Une troisième catégorie privilégie les jetons rares ou très informatifs comme les noms propres et les termes techniques.
Fait intéressant, des études d’interprétabilité montrent que de nombreuses têtes semblent redondantes et que les modèles conservent leurs performances même lorsque l’on en émonde une part significative. Cette redondance contribue probablement à la robustesse, en assurant que les schémas critiques disposent de multiples voies à travers le réseau.
Dans l’attention encodeur–décodeur, les têtes des couches tardives du décodeur s’avèrent les plus essentielles pour la qualité de traduction, tandis que les têtes de self-attention de l’encodeur peuvent souvent être fortement réduites.
Maintenant que les bases mathématiques sont posées, voyons comment la self-attention s’intègre à l’architecture complète des transformers.
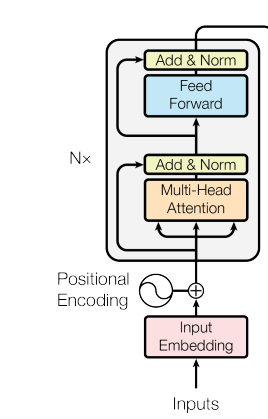
Dans l’encodeur, les couches de self-attention permettent à chaque position de prêter attention à toutes les autres positions de la séquence d’entrée. Ce schéma « tous‑avec‑tous » autorise un flux de contexte bidirectionnel, où chaque jeton construit une représentation informée par l’ensemble de la séquence.
Architecture de l’encodeur
Chaque couche d’encodeur combine une self-attention multi‑têtes et un réseau feed‑forward positionnel. Le feed‑forward traite chaque position de manière indépendante mais identique, en appliquant la même transformation apprise à tous les jetons.
Des connexions résiduelles et une normalisation de couche entourent ces deux sous‑couches, stabilisant les gradients et permettant des architectures plus profondes. En empilant plusieurs couches d’encodeur, on obtient des représentations de plus en plus abstraites : les couches initiales captent les motifs de surface et les couches profondes modélisent les relations sémantiques.
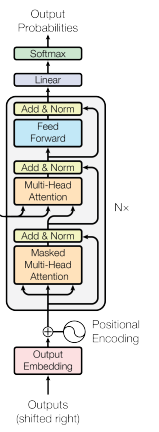
Le décodeur adapte la self-attention pour respecter les contraintes autorégressives. Lors de la génération de texte, le modèle ne peut se baser que sur les jetons déjà produits. Regarder les jetons futurs reviendrait à « tricher » pendant l’entraînement.
Architecture du décodeur
La self-attention masquée y parvient en fixant les poids d’attention à moins l’infini (qui deviennent zéro après softmax) pour toutes les positions postérieures à la position courante.
Ainsi, les prédictions ne dépendent que du contexte passé, et l’ordre causal requis pour la génération est respecté. En inférence, cette causalité est naturelle : les jetons futurs n’existent pas encore.
Entre les couches de self-attention du décodeur s’insère la cross-attention, qui permet au décodeur de se conditionner sur les sorties de l’encodeur. Ici, les requêtes viennent du décodeur (« ce que je dois générer »), tandis que les clés et valeurs proviennent de l’encodeur (« ce que l’entrée fournit »).
Architecture transformer
Ce mécanisme est essentiel pour les tâches séquence‑à‑séquence comme la traduction, où le décodeur doit aligner les mots de sortie sur les mots d’entrée pertinents. Contrairement à la self-attention, la cross-attention crée des dépendances entre deux séquences différentes, permettant à l’information de circuler de la source vers la cible.
Au‑delà de la théorie, qu’a réellement permis la self-attention en pratique ? La réponse est plus large qu’on ne l’imagine.
Après avoir vu comment la self-attention s’intègre à l’architecture des transformers, examinons les domaines où ce mécanisme a eu un impact concret.
La valeur de la self-attention tient notamment à sa neutralité vis‑à‑vis du domaine. Le même cadre mathématique qui aide les modèles à comprendre les relations linguistiques peut capturer des motifs dans les images, l’audio, et même des combinaisons de modalités.
À mon sens, cette agnosticité de domaine est ce qui rend la self-attention réellement enthousiasmante : moins un outil de NLP qu’un mécanisme général d’apprentissage des relations.
Les transformers excellent à capturer des dépendances à longue portée que les architectures précédentes rataient. En NLP, la self-attention alimente des modèles de rupture dans pratiquement toutes les tâches.
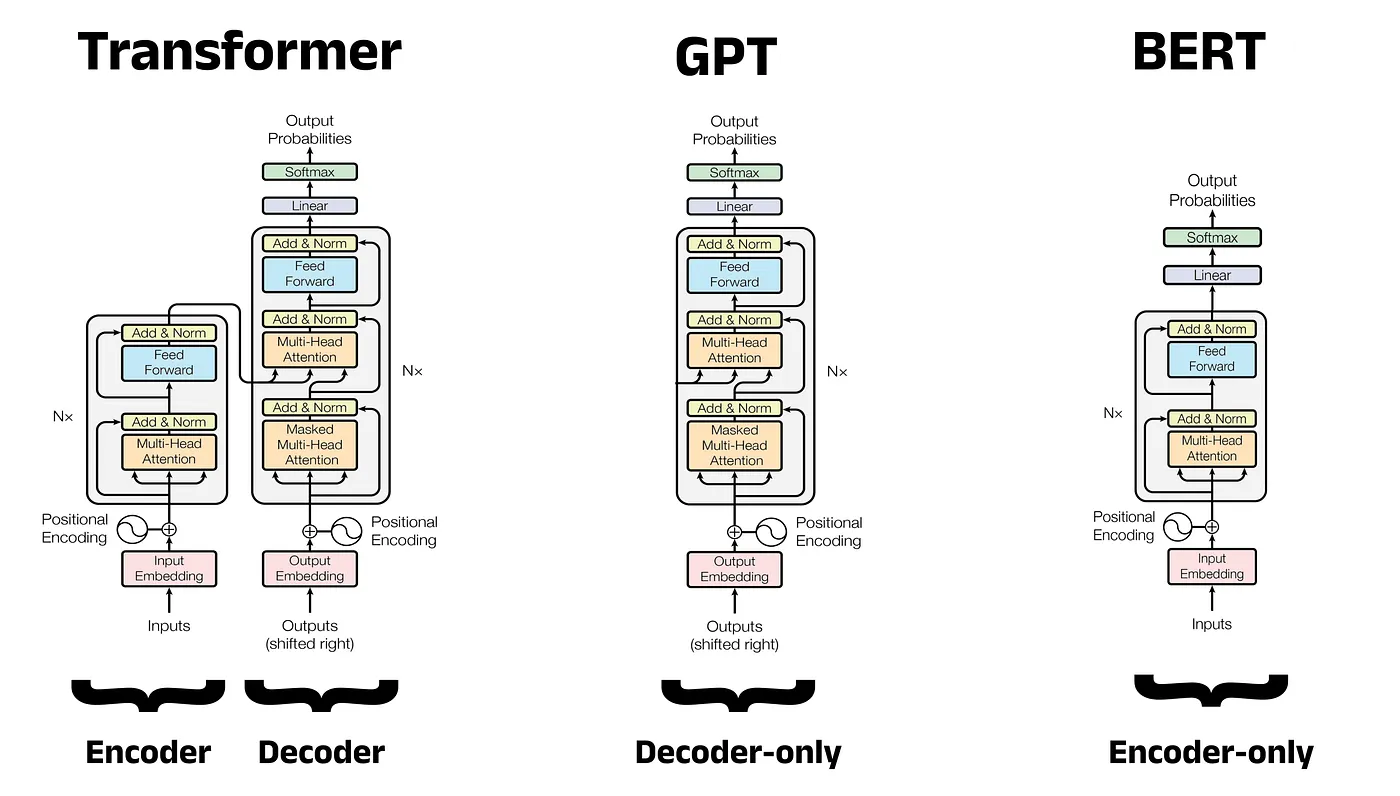
Comme vous pouvez le voir ci‑dessous, l’architecture des modèles diffère selon que l’on privilégie le décodeur ou l’encodeur.
Comparaison d’architectures : Transformer vs. GPT vs. BERT
Des modèles comme BERT exploitent une self-attention bidirectionnelle dans une architecture uniquement encodeur, ce qui leur permet de construire des représentations contextuelles riches pour la classification et la compréhension.
Les modèles GPT, comme le récent GPT-5.3 Codex, utilisent une self-attention masquée dans une architecture uniquement décodeur, avec des capacités remarquables de génération de texte.
T5 adopte l’architecture complète encodeur–décodeur et traite toutes les tâches de NLP comme des problèmes texte‑à‑texte.
L’adaptation Vision Transformer (ViT) a introduit la self-attention en vision en traitant les images comme des séquences de patchs. Au lieu de traiter les pixels via des couches convolutionnelles, ViT divise les images en patchs de taille fixe (généralement 16 × 16), aplatit chaque patch en vecteur, puis traite la séquence via des couches transformer.
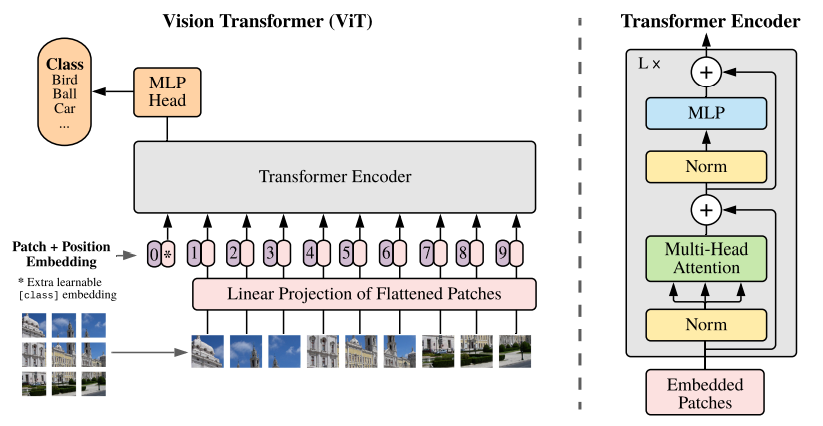
Cette approche capture des relations globales que les champs récepteurs locaux des réseaux convolutionnels peuvent manquer. ViT et ses variantes atteignent aujourd’hui l’état de l’art en classification d’images, détection d’objets, segmentation sémantique, et au‑delà :
L’utilité de la self-attention s’étend au traitement de la parole, où elle capture les dépendances temporelles dans les séquences audio plus efficacement que les modèles récurrents. Dans les recommandations, elle aide à modéliser les préférences utilisateur en accordant de l’attention aux interactions historiques pertinentes.
Les applications multimodales sont peut‑être les plus enthousiasmantes, car elles combinent vision et langage. Des modèles comme CLIP s’appuient sur la cross-attention entre représentations d’images et de textes, permettant la classification d’images en zero‑shot et la génération d’images à partir de descriptions textuelles.
Point commun de tous ces systèmes : ils montrent la capacité fondamentale de la self-attention à apprendre des relations dans toute donnée séquentielle ou structurée, quelle qu’en soit la modalité.
Si la self-attention a connu un succès remarquable dans de nombreux domaines, de nouveaux défis apparaissent au passage à l’échelle. À mesure que les modèles atteignent des milliards de paramètres et traitent des contextes de plusieurs centaines de milliers de jetons, la bande passante mémoire et les coûts de calcul deviennent des verrous majeurs.
Les efforts actuels visent de plus en plus à rendre la self-attention plus rapide et plus efficace sans sacrifier ses capacités. Cette tension entre puissance et efficacité est, selon moi, l’une des questions les plus stimulantes du moment. Passons en revue quelques avancées.
L’attention multi‑têtes standard maintient des projections clés et valeurs distinctes pour chaque tête, ce qui crée une forte empreinte mémoire en inférence. La multi-query attention (MQA) réduit cette empreinte en partageant une seule tête clés‑valeurs (KV) pour toutes les têtes de requête, diminuant drastiquement la taille du cache KV et accélérant le décodage. En contrepartie, la qualité peut baisser.
La grouped-query attention (GQA) propose un juste milieu en regroupant les têtes de requête qui partagent des paires clés‑valeurs. Avec 32 têtes de requête et 8 groupes, chaque groupe de 4 requêtes partage une même tête KV. Par exemple, la famille de modèles Mistral 3 utilise cette approche et atteint une qualité proche de l’attention complète, avec des gains de vitesse substantiels.
Tandis que GQA améliore l’efficacité mémoire, une autre piste s’attaque différemment au goulot computationnel de l’attention.
Des travaux récents combinent self-attention et modèles d’espace d’état pour gagner en efficacité. Des systèmes comme S4 et Hyena exploitent des espaces d’état structurés afin de modéliser des dépendances à longue portée avec une complexité linéaire plutôt que quadratique.
Ces approches visent la limite fondamentale de la self-attention : son coût quadratique en fonction de la longueur de séquence, qui rend les contextes très longs coûteux à l’extrême.
Au‑delà des changements d’architecture, les chercheurs ont trouvé des moyens astucieux d’optimiser l’attention existante.
Toujours côté inférence, des avancées récentes optimisent l’attention. La quantification réduit la précision du cache KV à 8 ou 4 bits, ce qui diminue fortement la mémoire avec une perte de qualité minime.
Flash Attention réorganise l’accès mémoire GPU pour minimiser les transferts de données, avec des accélérations de 2 à 3 fois. L’optimisation du calcul à l’exécution, où le modèle effectue plusieurs passes durant la génération, suggère qu’une application plus stratégique de l’attention peut donner de meilleurs résultats que le seul passage à l’échelle de la taille du modèle.
La self-attention est l’un des mécanismes les plus transformatifs de l’histoire de l’apprentissage automatique. En permettant aux modèles de déterminer dynamiquement quels éléments de l’entrée méritent l’attention, elle a résolu des défis de longue date : capturer des dépendances à longue portée et traiter des séquences efficacement.
L’élégance mathématique de l’attention par produit scalaire « scaled », renforcée par les architectures multi‑têtes, apporte à la fois rigueur théorique et efficacité pratique.
De l’alimentation des modèles de langue de pointe à la révolution de la vision par ordinateur, en passant par l’essor de systèmes multimodaux, la self-attention ne cesse d’étendre son périmètre. Les innovations récentes en grouped‑query attention, architectures hybrides et optimisation d’inférence montrent que nous continuons à en accroître l’efficacité et les capacités.
Si vous souhaitez approfondir et pratiquer, je vous recommande de vous inscrire à notre parcours de compétences Developing Large Language Models.
Cours sur les LLM
Cursus
Cours
Cours
blog
blog
Kurtis Pykes
9 min
blog
Lynn Heidmann
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Samuel Shaibu


