

Lernpfad
Entwicklung von großen Sprachmodellen
16 Std.
Ende 2017 stellte ein Forschungspapier mit dem Titel Attention Is All You Need einen revolutionären Mechanismus vor, der die Künstliche Intelligenz grundlegend verändern sollte. Im Kern dieses Durchbruchs stand Self-Attention: eine einfache, aber mächtige Idee, mit der Modelle Beziehungen in Daten verstehen, indem sie bestimmen, welche Elemente die meiste Aufmerksamkeit verdienen.
Heute treibt Self-Attention alles an – von den Gesprächsfähigkeiten von ChatGPT bis hin zu fortschrittlichen Bildverarbeitungssystemen. Sie ist zweifellos eine der prägendsten Innovationen in der Geschichte des maschinellen Lernens.
In diesem Guide führe ich dich von den konzeptionellen Grundlagen bis zu den Anwendungen und zeige, wie der Mechanismus Modellen hilft, weitreichende Abhängigkeiten zu erfassen und Informationen parallel zu verarbeiten – Fähigkeiten, die mit klassischen neuronalen Netzen zuvor nicht erreichbar waren.
Wenn du neu bei Transformern bist, starte am besten mit unseren Einsteigerkursen zu Large Language Models (LLMs) Concepts und Transformer Models with PyTorch.
Aus meiner Lehrerfahrung ist der beste Einstieg ein grundlegendes Problem der Sequenzverarbeitung: Wie kann ein Modell zu jedem Zeitpunkt bestimmen, welche Teile des Inputs gerade am relevantesten sind?
Lass uns erst die Intuition klären, bevor wir in die Mathematik einsteigen.
Self-Attention gewichtet die Bedeutung der Elemente in einer Sequenz relativ zueinander. Beim Verarbeiten des Satzes "The animal didn't cross the road because it was too tired" hilft Self-Attention dem Modell zu verstehen, dass sich "it" auf "animal" und nicht auf "road" bezieht – eine Beziehung, die sich über mehrere Wörter erstreckt.
Das ist übrigens das Beispiel, das ich Studierenden immer zuerst zeige. Es macht sofort Klick, weil es unserem natürlichen Leseverhalten entspricht.
Besonders stark ist Self-Attention, weil sie diese Beziehungen für alle Positionen einer Sequenz gleichzeitig berechnet. Anders als rekurrente Netze, die Schritt für Schritt vorgehen, betrachtet Self-Attention in einem Forward-Pass jedes Element in Relation zu allen anderen.
Diese Parallelisierung verkürzt die Trainingszeit drastisch und erfasst Abhängigkeiten unabhängig von ihrer Distanz in der Sequenz.
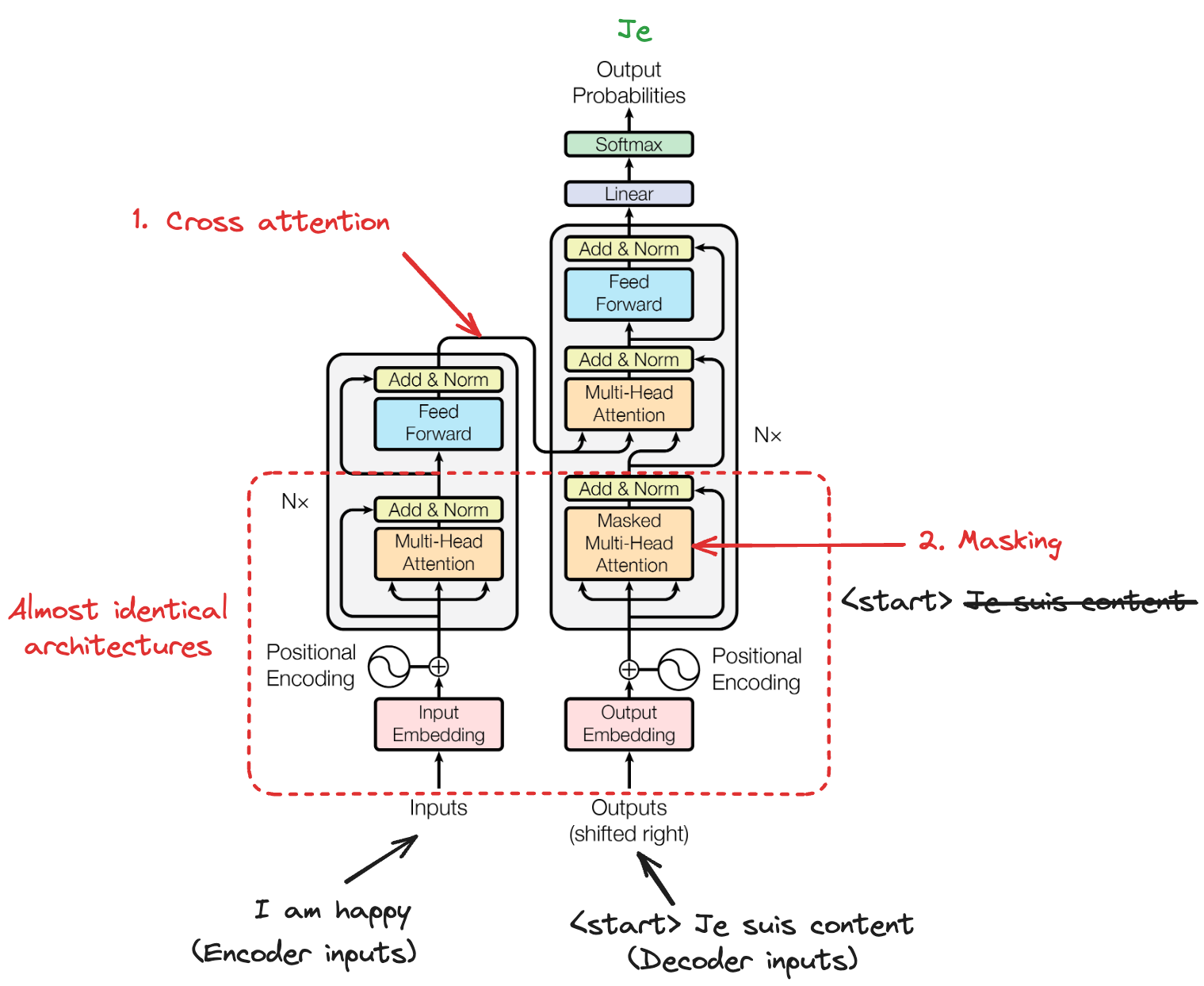
Wichtig ist die Abgrenzung zu verwandten Mechanismen: Bei Self-Attention achtet eine Sequenz auf sich selbst. Jedes Element fragt Informationen aus allen Positionen derselben Sequenz ab.
Cross-Attention hingegen lässt eine Sequenz eine andere beachten – etwa wenn ein Decoder bei der maschinellen Übersetzung auf Encoder-Ausgaben schaut.
Maskierte Self-Attention fügt eine weitere Einschränkung hinzu: Positionen dürfen nicht auf nachfolgende Positionen achten. So hängen Vorhersagen nur von bereits bekannten Ausgaben ab – essenziell für autoregressive Textgenerierung.
Aber woher kommt diese Idee eigentlich, und welche Probleme sollte sie lösen?
Vor dem Aufkommen von Self-Attention hatte das Feld mit gravierenden Grenzen in der Sequenzmodellierung zu kämpfen.
Rekurrente Netze, darunter LSTMs und GRUs, verarbeiten Sequenzen sequentiell – ein grundlegender Flaschenhals: Sie tun sich mit weitreichenden Abhängigkeiten schwer, weil Informationen durch viele Zwischenzustände wandern müssen. Das führt zu verschwindenden Gradienden und verlorenem Kontext.
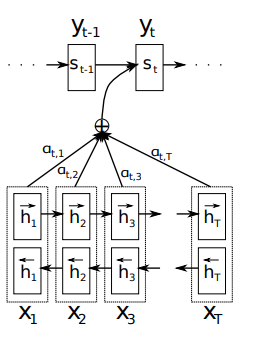
Der Weg zu Self-Attention begann mit Attention-Mechanismen in RNN-basierten Encoder-Decoder-Architekturen. 2014 stellten Bahdanau und Kollegen einen Mechanismus vor, der Decodern Zugriff auf alle Hidden States des Encoders erlaubt – anstatt sich auf einen einzelnen Kontextvektor fester Länge zu verlassen.
Dieser Durchbruch adressierte das Kompressionsproblem: Eingaben variabler Länge wurden unabhängig von ihrer Komplexität in Repräsentationen fester Länge gepresst.
Grafische Darstellung des vorgeschlagenen Modells von Bahdanau
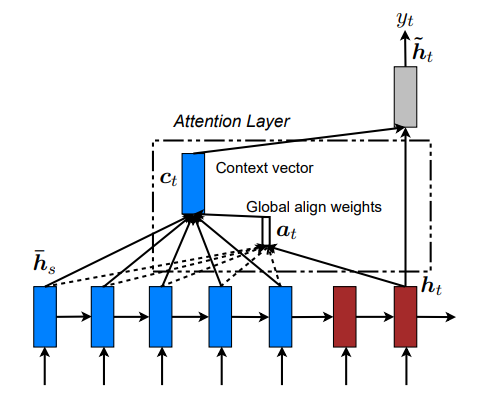
Ein Jahr später schlug Luong vereinfachte Attention-Varianten vor, darunter den skalierten Dot-Product-Ansatz, der später die Transformer-Architektur prägen sollte. Auch wenn diese frühen Mechanismen die Performance verbesserten, waren sie weiterhin auf die sequentielle RNN-Verarbeitung angewiesen.
Globales Attentional-Modell (Luong)
Die echte Revolution kam mit der Frage: Was, wenn wir die Rekurrenz weglassen und uns nur auf Attention stützen? Daraus entstand die Transformer-Architektur, in der Self-Attention der zentrale Mechanismus für das Verständnis sequentieller Beziehungen ist.
Nachdem wir die Bedeutung geklärt haben, schauen wir uns an, wie Self-Attention mathematisch funktioniert.
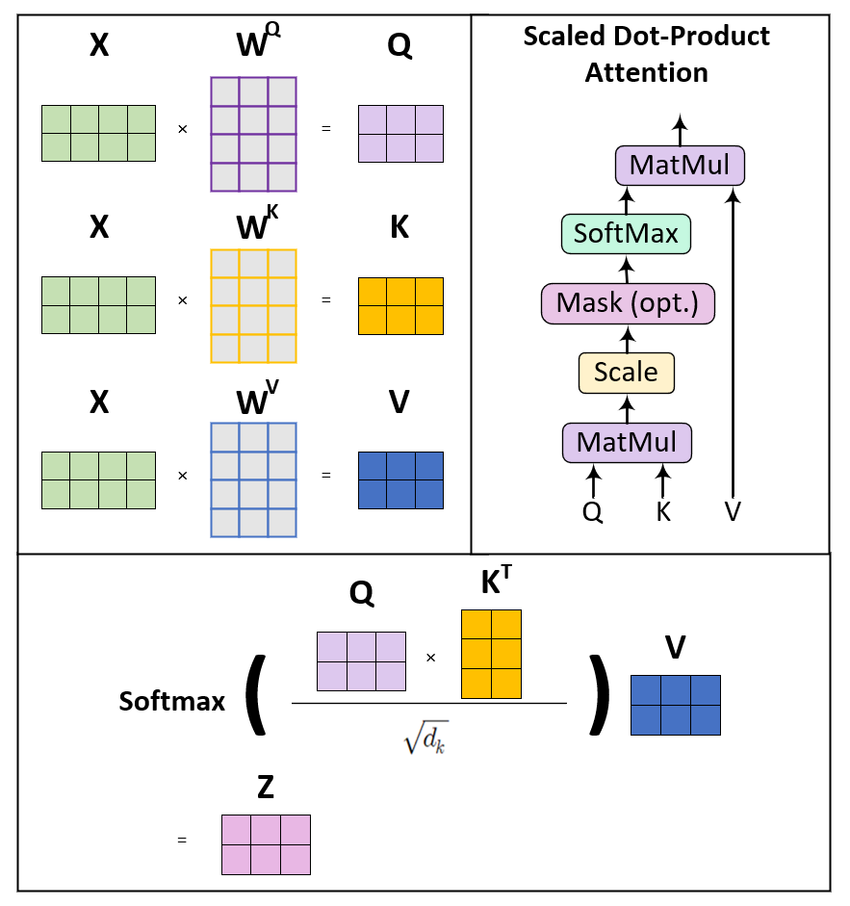
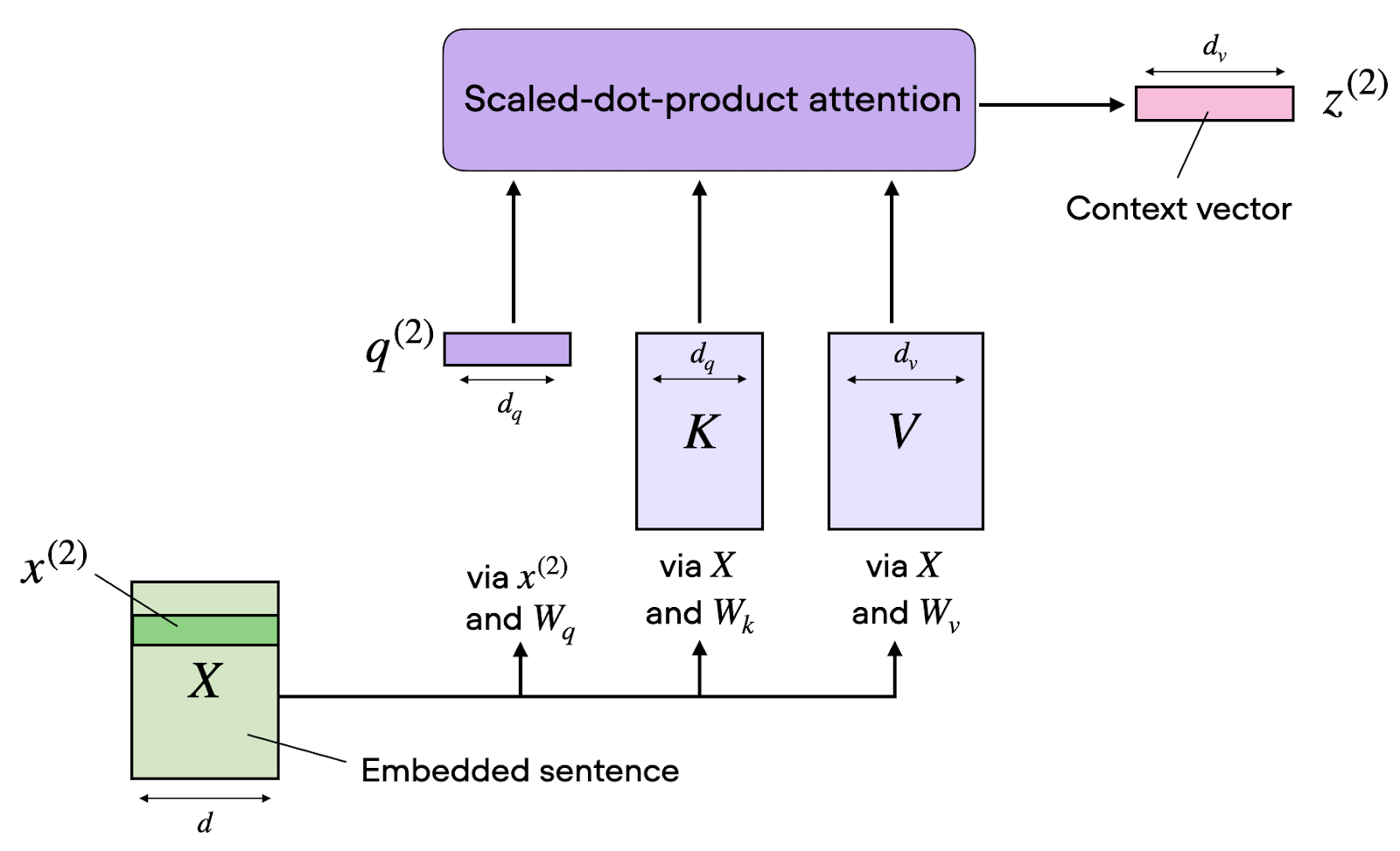
Self-Attention transformiert Eingabesequenzen über drei gelernte Projektionen: Queries, Keys und Values. Denk an drei unterschiedliche "Blicke" auf dieselbe Information, die jeweils einem eigenen Zweck in der Attention-Berechnung dienen.
Für eine Eingabesequenz mit der Embedding-Dimension d_model erzeugen wir drei Gewichtsmatrizen: W_Q, W_K und W_V. Multiplizieren wir unsere Eingabematrix X mit diesen Gewichten, erhalten wir:
Query-Matrix Q = X · W_Q: repräsentiert "wonach ich suche"
Key-Matrix K = X · W_K: repräsentiert "was ich anbiete"
Value-Matrix V = X · W_V: repräsentiert "was ich tatsächlich enthalte"
Mir hilft hier das Bibliotheks-Bild: Du kommst mit einer Suchanfrage (Query), die Karteikarten sind die Keys, und die Bücher selbst sind die Values.
Typischerweise projizieren diese Matrizen auf eine kleinere Dimension d_k (oft d_model geteilt durch die Anzahl der Attention-Heads). So bleibt die Komplexität handhabbar, während die Darstellungskraft erhalten bleibt – besonders wichtig bei längeren Sequenzen.
Mit Q, K und V können wir nun die Attention selbst berechnen.
Die Berechnung folgt einer eleganten Formel: Zuerst bilden wir Skalarprodukte zwischen Queries und Keys. Das misst, wie gut das, wonach jede Position sucht, zu dem passt, was die anderen Positionen anbieten.
Mit steigender Dimensionalität können diese Produkte sehr groß werden und die Softmax-Funktion in Bereiche mit extrem kleinen Gradienden drücken. Um numerische Instabilitäten zu vermeiden, teilen wir durch die Quadratwurzel der Key-Dimension.
Skalierte Dot-Product-Attention
Dieser Skalierungsfaktor hält die Varianz im Netzwerk stabil und sorgt für zuverlässige Gradienten beim Training. Ohne ihn würden Modelle mit hochdimensionalen Embeddings schlechter lernen, weil Softmax nahezu One-Hot-Verteilungen liefern würde, die Aufmerksamkeit nicht sinnvoll verteilen.
Bevor wir weitermachen, fehlt noch ein wichtiger Baustein: Positional Encoding.
Was mich bei der ersten Beschäftigung damit am meisten überrascht hat: Self-Attention ist vollständig permutationsinvariant. Wenn du die Tokens durchmischst, erhältst du denselben Output – nur entsprechend umsortiert.
Die Implikation brauchte einen Moment: Der Mechanismus ist mächtig, aber blind für Reihenfolge. Für Aufgaben, bei denen die Ordnung zählt (wie Sprachverständnis), müssen wir Positionsinformationen explizit einspeisen.
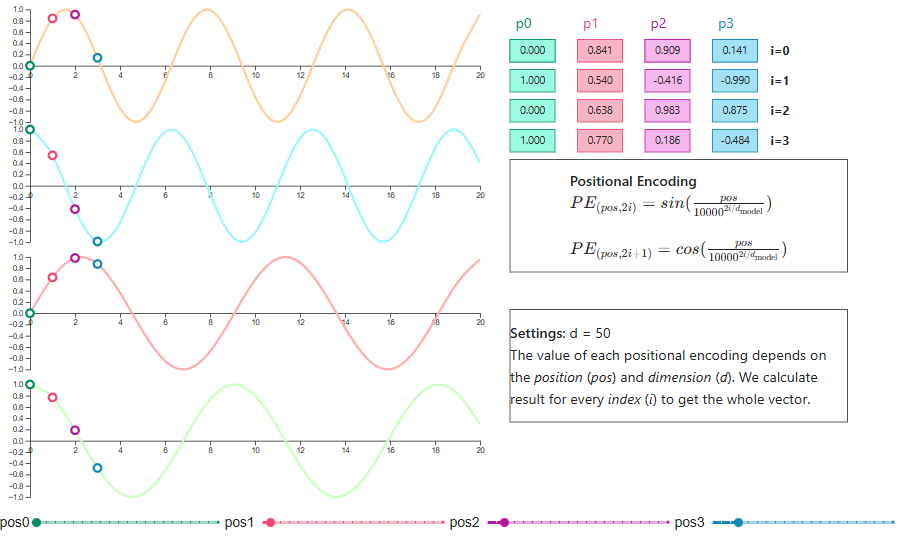
Der ursprüngliche Transformer nutzte sinusförmige Positionscodierungen und wendete Sinus- und Kosinusfunktionen unterschiedlicher Frequenzen pro Dimension an. Diese Wahl war nicht zufällig: Die wellenartigen Muster erlauben es Modellen, relative Positionen zu lernen, und sie lassen sich natürlich auf längere, noch ungesehene Sequenzen erweitern.
Visualisierung der Positionscodierung
Neuere Entwicklungen umfassen RoPE (Rotary Position Embedding), das Query- und Key-Vektoren in einem mehrdimensionalen Raum um Winkel proportional zu ihren Positionen rotiert. Nach der Rotation codiert das Skalarprodukt zwischen Queries und Keys die relative Distanz quasi automatisch.
RoPE hat sich in Modellen wie LLaMA breit durchgesetzt – vor allem wegen der starken Extrapolationsfähigkeiten.
Ein anderer Ansatz, ALiBi (Attention with Linear Biases), geht einen anderen Weg und fügt positionsabhängige Abstrafungen direkt zu den Attention-Scores hinzu. Statt Embeddings zu verändern, werden die Gewichte so gebiased, dass benachbarte Tokens bevorzugt werden – mit unterschiedlicher Bias-Stärke je Attention-Head.
Diese Methode zeigt beeindruckende Extrapolation auf Sequenzlängen, die weit über das Training hinausgehen.
Nach der Berechnung der skalierten Scores wenden wir Softmax über der Key-Dimension an. Diese Normalisierung macht aus Rohscores eine Wahrscheinlichkeitsverteilung, sodass die Attention-Gewichte für jede Query-Position auf eins summieren.
Softmax betont die höchstbewerteten Beziehungen und dämpft irrelevante Verbindungen. Das kann anfangs aber zu zu spitzen Verteilungen führen, wenn das Modell noch keine feinen Muster gelernt hat.
Um das abzumildern, setzen Praktiker oft Dropout auf den Attention-Gewichten ein und nullen zufällig einige Verbindungen, um Robustheit zu fördern.
Mit den Attention-Gewichten bilden wir den finalen Output als gewichtete Summe der Value-Vektoren.
Jede Position erhält so eine kontextbewusste Repräsentation, die Informationen aus der gesamten Sequenz aggregiert – mit Beiträgen proportional zu den Gewichten. Diese gewichtete Kombination lässt Informationen dynamisch entlang gelernter Beziehungen fließen, statt festen Mustern zu folgen.
Berechnung der Kontextvektoren
Single-Head-Attention bringt uns überraschend weit, hat aber eine Decke. Jetzt wird es spannender.
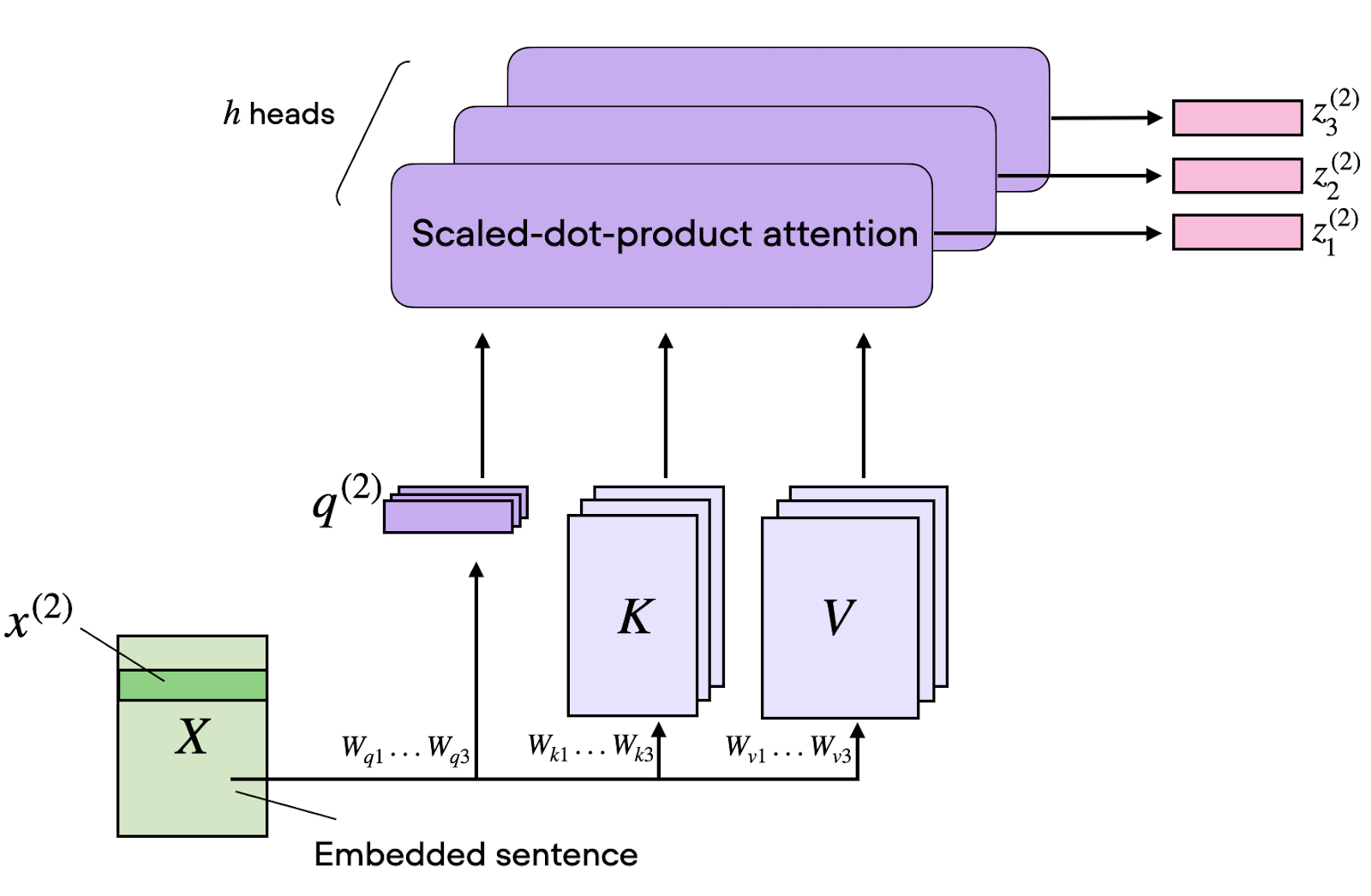
Single-Head-Attention ist stark, hat aber eine grundlegende Einschränkung: Sie kann immer nur eine Art von Beziehung gleichzeitig erfassen.
Multi-Head-Attention löst das, indem mehrere Attention-Berechnungen parallel laufen – jede fokussiert auf andere Aspekte der Beziehungen im Input. Zum Beispiel könnte je ein Head spezialisiert sein auf:
Aus meiner Erfahrung mit diesen Modellen entsteht diese Spezialisierung oft organisch im Training. Man konstruiert sie nicht – und genau das macht den Mechanismus so faszinierend.
Implementiert wird dies, indem man die Matrizen Q, K und V entlang der Dimensionsachse aufteilt, jede Teilmatrix in separaten Heads verarbeitet und die Ergebnisse wieder zusammenfügt.
Haben wir 8 Heads und 512-dimensionale Embeddings, arbeitet jeder Head auf 64-dimensionalen Teilräumen. Diese Parallelisierung erhöht nicht die Komplexität in Bezug auf die Sequenzlänge, vervielfacht aber die Fähigkeit des Modells, unterschiedliche Muster zu lernen.
Forschung dazu, was unterschiedliche Attention-Heads lernen, zeigt spannende Muster.
In Übersetzungsmodellen achten manche Heads konsequent auf Positionsbeziehungen und fokussieren Nachbarwörter – unabhängig vom Inhalt. Andere spezialisieren sich auf syntaktische Rollen wie Subjekt-Verb- oder Verb-Objekt-Beziehungen. Eine weitere Kategorie richtet die Aufmerksamkeit auf seltene oder informationsreiche Tokens wie Eigennamen und Fachbegriffe.
Spannend ist auch: Interpretierbarkeitsstudien zeigen, dass viele Heads redundant wirken und die Modellleistung oft stabil bleibt, selbst wenn ein relevanter Anteil entfernt wird. Diese Redundanz dürfte zur Robustheit beitragen, indem kritische Muster mehrere Pfade im Netzwerk haben.
In Encoder-Decoder-Attention sind Heads in späteren Decoder-Schichten besonders wichtig für die Übersetzungsqualität, während Encoder-Self-Attention-Heads oft deutlich reduziert werden können.
Mit den mathematischen Grundlagen im Gepäck schauen wir, wie Self-Attention in die komplette Transformer-Architektur eingebettet ist.
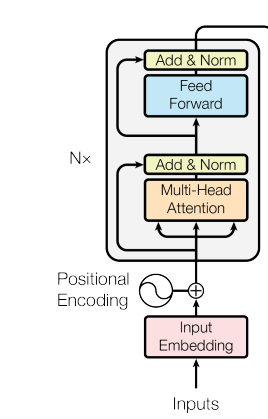
Im Transformer-Encoder erlaubt Self-Attention jeder Position, auf alle anderen Positionen der Eingabesequenz zu achten. Dieses "All-to-All"-Muster ermöglicht bidirektionalen Kontextfluss: Jedes Token baut eine Repräsentation auf, die von der gesamten Sequenz informiert ist.
Encoder-Architektur
Jede Encoder-Schicht kombiniert Multi-Head-Self-Attention mit einem positionsweisen Feedforward-Netz. Das Feedforward-Netz verarbeitet jede Position unabhängig, aber identisch – es wendet dieselbe gelernte Transformation auf alle Tokens an.
Residual-Verbindungen und Layer-Normalisierung umgeben beide Teilschichten, stabilisieren Gradienten und ermöglichen tiefere Architekturen. Durchs Stapeln mehrerer Encoder-Schichten entstehen zunehmend abstrakte Repräsentationen: Frühe Schichten erfassen Oberflächenmuster, spätere kodieren semantische Beziehungen.
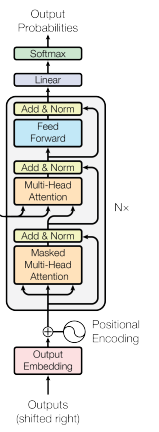
Der Decoder passt Self-Attention so an, dass autoregressive Randbedingungen eingehalten werden. Bei der Textgenerierung darf sich das Modell nur auf bereits erzeugte Tokens stützen – auf zukünftige zu schauen, wäre beim Training Schummeln.
Decoder-Architektur
Maskierte Self-Attention setzt dazu die Gewichte für alle nachfolgenden Positionen auf minus Unendlichkeit (nach Softmax wird das zu Null).
So hängen Vorhersagen nur von vorigem Kontext ab und die kausale Ordnung für Generierungsaufgaben bleibt gewahrt. Beim Inferenzprozess ist das ohnehin natürlich: Zukünftige Tokens existieren noch nicht.
Zwischen den Self-Attention-Schichten des Decoders liegt Cross-Attention, die es dem Decoder ermöglicht, sich auf Encoder-Ausgaben zu stützen. Die Queries kommen aus dem Decoder ("was ich generieren muss"), Keys und Values aus dem Encoder ("was der Input liefert").
Transformer-Architektur
Diese Cross-Attention ist zentral für Sequenz-zu-Sequenz-Aufgaben wie Übersetzung, bei denen der Decoder Ausgabewörter mit relevanten Eingabewörtern abgleichen muss. Anders als Self-Attention schafft Cross-Attention Abhängigkeiten zwischen zwei unterschiedlichen Sequenzen und lässt Informationen von der Quelle zum Ziel fließen.
Abseits der Theorie: Was hat Self-Attention in der Praxis ermöglicht? Die Antwort ist breiter, als viele vermuten.
Nachdem wir gesehen haben, wie Self-Attention im Transformer funktioniert, schauen wir, wo der Mechanismus in der Realität wirkt.
Besonders wertvoll ist Self-Attention, weil sie domänenagnostisch ist. Dasselbe mathematische Gerüst, das Sprachbeziehungen erfasst, erkennt auch Muster in Bildern, Audio – und sogar in Kombinationen verschiedener Datentypen.
Genau diese Domänenunabhängigkeit macht Self-Attention für mich so spannend. Ich würde sagen: weniger ein NLP-Werkzeug, mehr ein allgemeiner Mechanismus zum Lernen von Beziehungen.
Transformer-Modelle erfassen weitreichende Abhängigkeiten, die frühere Architekturen verpasst haben. Im NLP treibt Self-Attention Durchbruchsmodelle praktisch in allen Aufgabenfeldern an.
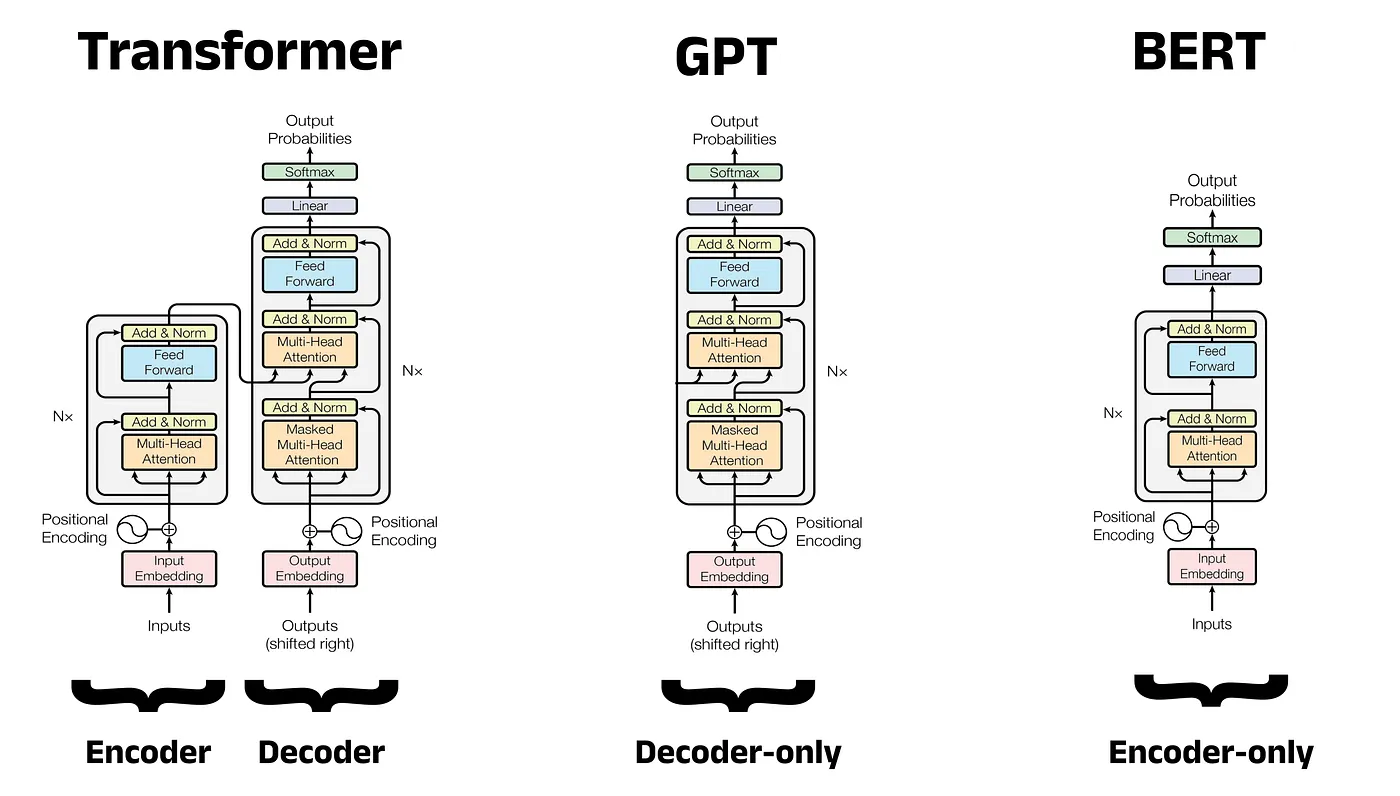
Wie du im Bild unten siehst, unterscheidet sich die Modellarchitektur je nach Fokus auf Decoder oder Encoder.
Architekturvergleich: Transformer vs. GPT vs. BERT
Modelle wie BERT nutzen bidirektionale Self-Attention in einer reinen Encoder-Architektur und bauen damit reichhaltige kontextuelle Repräsentationen für Klassifikation und Verständnis auf.
GPT-Modelle wie das kürzlich veröffentlichte GPT-5.3 Codex verwenden maskierte Self-Attention in einer reinen Decoder-Architektur und erzielen herausragende Textgenerierung.
T5 setzt auf die vollständige Encoder-Decoder-Architektur des Transformers und behandelt alle NLP-Aufgaben als Text-zu-Text-Probleme.
Die Vision Transformer (ViT)-Adaption brachte Self-Attention in die Bildverarbeitung, indem Bilder als Sequenzen von Patches behandelt werden. Anstatt Pixel durch Convolutional Layers zu schicken, teilt ViT Bilder in Patches fester Größe (typisch 16×16), glättet jeden Patch zu einem Vektor und verarbeitet die Sequenz durch Transformer-Schichten.
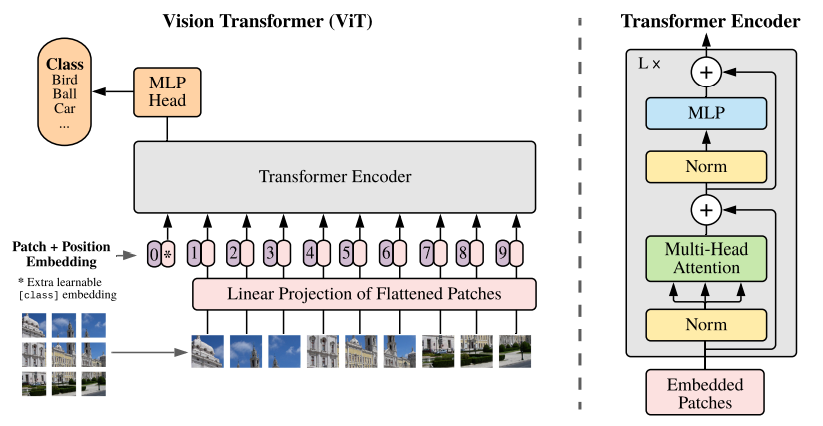
Dieser Ansatz erfasst globale Beziehungen, die die lokalen Rezeptorfelder von CNNs übersehen können. ViT und seine Varianten erzielen heute State-of-the-Art-Ergebnisse in Bildklassifikation, Objekterkennung, semantischer Segmentierung und mehr:
Die Nützlichkeit von Self-Attention erstreckt sich auf Sprachverarbeitung, wo zeitliche Abhängigkeiten in Audiosequenzen effektiver erfasst werden als mit rekurrenten Modellen. In Recommender-Systemen hilft Self-Attention, Nutzervorlieben zu modellieren, indem relevante historische Interaktionen hervorgehoben werden.
Besonders spannend sind multimodale Anwendungen, die Bild und Sprache kombinieren. Modelle wie CLIP nutzen Cross-Attention zwischen Bild- und Textrepräsentationen und ermöglichen Zero-Shot-Bildklassifikation sowie Bildgenerierung aus Textbeschreibungen.
Allen diesen Systemen ist gemeinsam: Sie demonstrieren die Fähigkeit von Self-Attention, Beziehungen in beliebigen sequentiellen oder strukturierten Daten zu lernen – unabhängig von der Modalität.
So erfolgreich Self-Attention überall ist, entstehen bei der Skalierung neue Herausforderungen. Wenn Modelle auf Milliarden Parameter anwachsen und Kontexte mit Hunderttausenden Tokens verarbeiten, werden Speicherbandbreite und Rechenkosten zu Engpässen.
Der Fokus bei neuen Modellen liegt daher zunehmend darauf, Self-Attention schneller und effizienter zu machen, ohne ihre Kernfähigkeiten einzubüßen. Diese Spannung zwischen Fähigkeit und Effizienz ist für mich eines der spannendsten offenen Probleme. Werfen wir einen Blick auf aktuelle Entwicklungen.
Standard-Multi-Head-Attention hält für jeden Head eigene Key- und Value-Projektionen vor – das erzeugt hohen Speicherbedarf in der Inferenz. Multi-Query-Attention (MQA) reduziert diesen, indem ein einzelnes Key-Value-(KV-)Paar für alle Query-Heads geteilt wird. Das verkleinert den KV-Cache drastisch und beschleunigt das Decoding – kann aber Qualität kosten.
Grouped-Query-Attention (GQA) ist ein ausgewogenerer Ansatz: Query-Heads werden in Gruppen geteilt, die sich Key-Value-Paare teilen. Bei 32 Query-Heads und 8 Gruppen teilt sich je Vierergruppe ein KV-Head. Die Mistral 3-Modellfamilie nutzt diesen Ansatz und erreicht nahezu Full-Attention-Qualität bei deutlichen Geschwindigkeitsgewinnen.
Während GQA die Speichereffizienz adressiert, geht eine andere Forschungslinie das grundlegende Rechen-Bottleneck der Attention von einer anderen Seite an.
Aktuelle Arbeiten kombinieren Self-Attention mit State-Space-Modellen, um Effizienz zu steigern. Systeme wie S4 und Hyena nutzen strukturierte Zustandsräume, um weitreichende Abhängigkeiten mit linearer statt quadratischer Komplexität zu modellieren.
Damit adressieren sie die Grundgrenze von Self-Attention: Die Rechenkosten wachsen quadratisch mit der Sequenzlänge – extrem lange Kontexte werden so schnell unerschwinglich.
Neben neuen Architekturen gibt es clevere Wege, bestehende Mechanismen während der Inferenz zu optimieren.
Abseits struktureller Änderungen optimieren aktuelle Ansätze die Attention zur Laufzeit. Quantisierung reduziert die Präzision des KV-Caches auf 8 oder 4 Bit – mit massivem Speichervorteil und minimalem Qualitätsverlust.
Flash Attention organisiert den GPU-Speicherzugriff neu, minimiert Datenbewegungen und erreicht 2–3× Speedups. Testzeit-Compute-Optimierung, bei der Modelle während der Generierung mehrere Durchläufe machen, deutet darauf hin, dass strategische Attention-Anwendung bessere Ergebnisse liefern kann als reines Skalieren der Modellgröße.
Self-Attention ist einer der einflussreichsten Mechanismen der ML-Geschichte. Indem Modelle dynamisch bestimmen, welche Eingabeelemente Fokus verdienen, löst sie langjährige Herausforderungen: weitreichende Abhängigkeiten erfassen und Sequenzen effizient verarbeiten.
Die mathematische Eleganz der skalierten Dot-Product-Attention, verstärkt durch Multi-Head-Architekturen, liefert theoretische Solidität und praktische Wirkung.
Von State-of-the-Art-Sprachmodellen über die Revolution der Computer Vision bis hin zu multimodalen KI-Systemen erweitert Self-Attention stetig ihr Einsatzfeld. Neuere Innovationen wie Grouped-Query-Attention, hybride Architekturen und Inferenzoptimierungen zeigen, dass wir diesen Mechanismus weiterhin effizienter und fähiger machen.
Wenn du tiefer einsteigen und praxisnah üben möchtest, empfehle ich dir unseren Skill Track Developing Large Language Models.
LLM-Kurse
Lernpfad
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Matt Crabtree
Tutorial
Laiba Siddiqui
