
Cursus
Apprentissage profond en Python
18 h
Vous cherchez des conseils pour décrocher le poste de vos rêves et affiner vos compétences en matière d'apprentissage en profondeur ? Ne cherchez pas plus loin. Cet article propose des réponses à 20 questions d'entretien courantes pour des postes dans le domaine de l'apprentissage profond, afin de vous aider à exceller lors des entretiens avec un peu d'entraînement.
Les questions générales sur l'apprentissage profond portent généralement sur la compréhension du domaine, ce qui le distingue des autres domaines de l'IA, la mise en relation des problèmes du monde réel avec les solutions d'apprentissage profond, et la compréhension de leurs défis et de leurs limites.
L'apprentissage profond est un sous-domaine de l'apprentissage automatique et de l'IA dans son ensemble. Il s'agit de former de grands modèles basés sur des réseaux neuronaux artificiels à partir de données.
Les modèles apprennent à résoudre des tâches difficiles de prédiction et d'inférence (telles que la classification, la régression, la reconnaissance d'objets dans des images, etc.) en découvrant automatiquement des modèles et des caractéristiques complexes sous-jacents aux données. Cela se fait en imitant les structures internes complexes du cerveau humain.
Notre Comprendre l'intelligence artificielle démystifie de manière exhaustive les domaines et les tâches solubles de l'IA, y compris l'apprentissage profond.
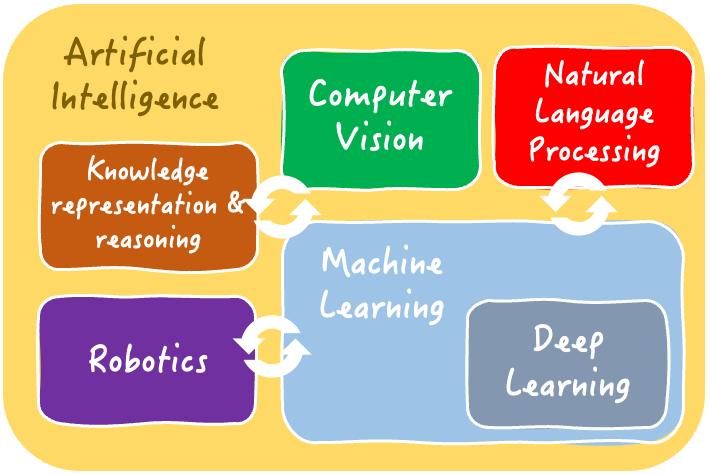
Les domaines interdépendants de l'intelligence artificielle | Iván Palomares
Les solutions d'apprentissage profond se distinguent dans les problèmes où les données sont très complexes, par exemple lorsqu'il s'agit de données non structurées ou hautement dimensionnelles.
C'est également le choix privilégié pour les problèmes liés à des quantités massives de données ou nécessitant la saisie de modèles nuancés : le plus souvent, ils parviennent à extraire et à comprendre des caractéristiques de données significatives que les approches d'apprentissage automatique ne parviennent pas à trouver.
Voici quelques exemples de problèmes pouvant être résolus par des solutions d'apprentissage profond :
Sachez toutefois que pour de nombreuses tâches et ensembles de données plus simples, les modèles d'apprentissage automatique légers tels que les arbres de décision et les régresseurs peuvent être plus que suffisants, ce qui en fait un meilleur choix que les modèles d'apprentissage profond, car ils sont plus faciles et moins coûteux à former et à déployer.
Les modèles d'apprentissage profond exigent généralement des compétences approfondies en matière de préparation et de traitement des données ; c'est pourquoi l'article suivant sur les entretiens d'ingénierie des données peut vous être utile.
Le choix d'une approche d'apprentissage profond appropriée dépend de plusieurs facteurs, tels que la nature des données, la complexité du problème et les ressources informatiques disponibles.
Les étapes suivantes constituent une recette simple mais efficace pour vous aider à faire ce choix important :

Trois architectures communes d'apprentissage profond et leurs applications | Iván Palomares
Concevoir une architecture d'apprentissage profond adaptée à une tâche spécifique comme la classification implique de choisir le nombre et la taille appropriés des couches de neurones, ainsi que de choisir les bonnes fonctions d'activation.
Ces décisions sont généralement prises en fonction des caractéristiques des données. Pour la classification d'images, vous pouvez utiliser une pile de couches convolutives dans votre architecture pour capturer des motifs visuels tels que des couleurs (ou des combinaisons de couleurs), des formes, des bords, etc.
La couche supérieure située à l'extrémité de votre architecture d'apprentissage profond (tête de modèle) dépend également de votre tâche, car elle doit être conçue pour produire le résultat souhaité.
Par exemple, pour un problème de classification d'images tel que la classification d'images de poussins en espèces d'oiseaux, ces dernières couches doivent comporter une fonction d'activation softmax qui produit des probabilités de classe afin de déterminer la classe d'espèces d'oiseaux la plus probable à laquelle appartient l'image analysée.
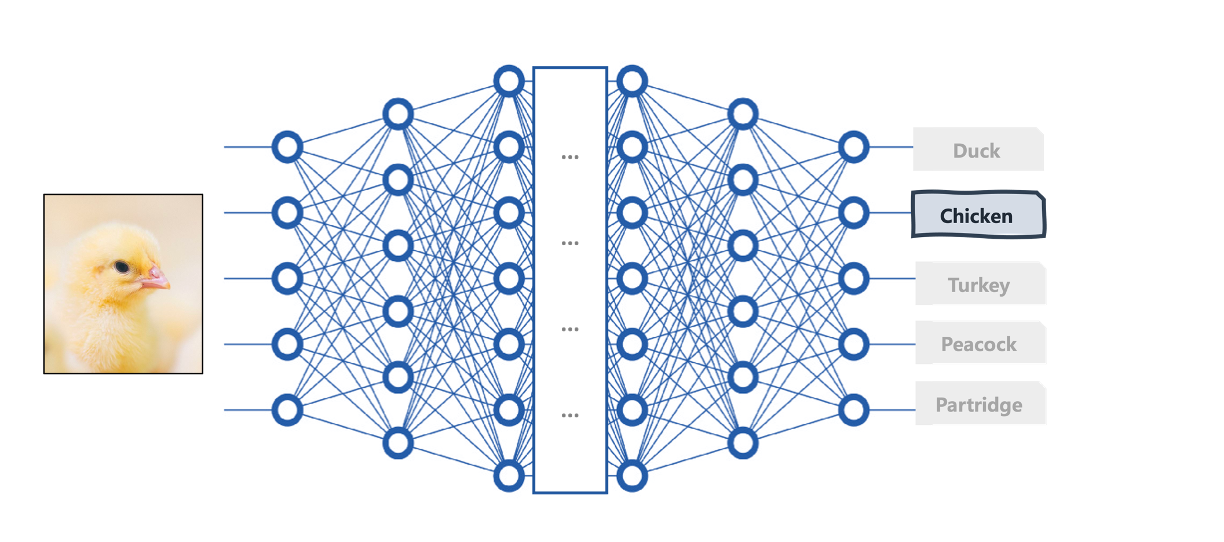
Une architecture d'apprentissage profond pour la classification d'images | Iván Palomares
Les défis fréquents qui peuvent entraver l'application réussie des modèles d'apprentissage profond dans le monde réel comprennent l'ajustement excessif, l'évanouissement et l'explosion des gradients, et la nécessité de grandes quantités de données étiquetées pour la formation. La bonne nouvelle, c'est que grâce aux efforts continus de la recherche, il existe des approches pour y remédier.
En plus de ces solutions spécifiques, veillez à mettre en place un suivi régulier du modèle et des mécanismes de mise au point afin de garantir de bonnes performances à long terme.
Si vous êtes un nouveau diplômé ou si vous recherchez votre premier poste dans le domaine de l'apprentissage profond sur le marché du travail, vous pouvez vous attendre à des questions qui testent votre acquisition de connaissances fondamentales et de compétences pratiques dans la formation et l'évaluation de modèles d'apprentissage profond dans un cadre expérimental.
Les fonctions d'activation sont des fonctions mathématiques utilisées dans toutes les architectures modernes de réseaux neuronaux profonds. Cela se produit au niveau des neurones, au cours du processus de mise en correspondance de plusieurs entrées de neurones en une valeur de sortie transmise aux neurones de la couche suivante.
Ils sont essentiels dans les modèles d'apprentissage profond car ils introduisent la non-linéarité, ce qui est vital pour leur permettre d'apprendre des relations et des modèles complexes dans les données au cours de la formation.
Sinon, ils n'apprendraient guère plus que des modèles de linéarité à partir des données en appliquant des combinaisons linéaires successives d'entrées - tout comme le font les modèles de régression linéaire classiques !
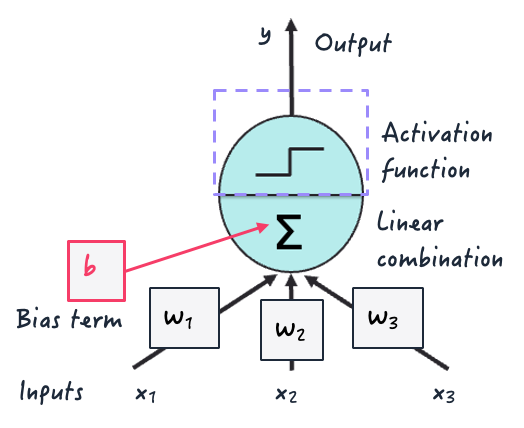
Fonction d'activation à l'intérieur d'un neurone artificiel | Iván Palomares
Les fonctions d'activation les plus courantes sont la fonction logistique (logit), la tangente hyperbolique (tanh) et l'activation par unité linéaire rectifiée (ReLU), comme illustré ci-dessous.
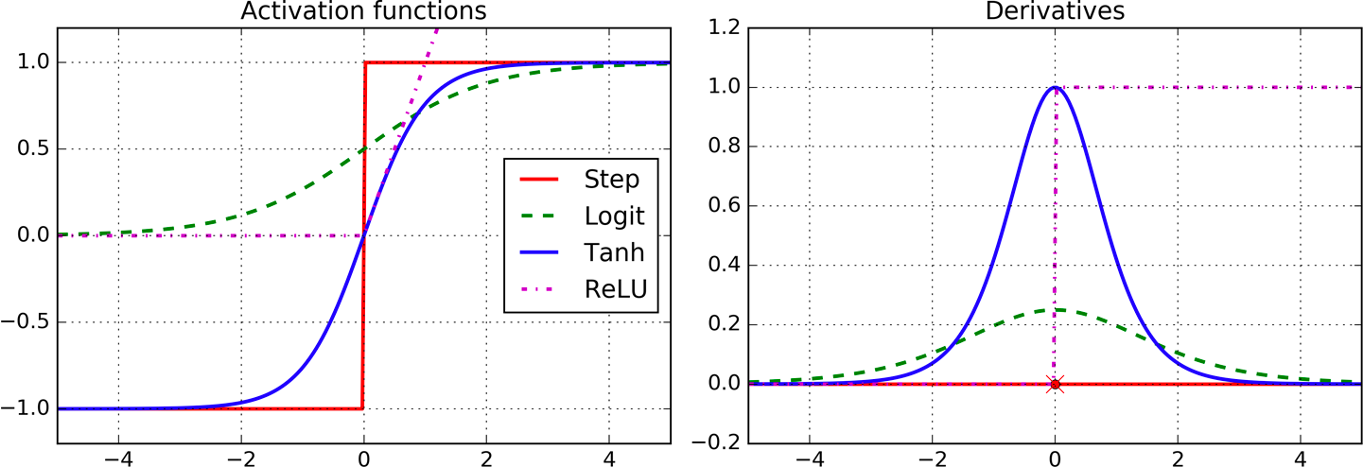
Exemples de fonctions d'activation | Image par Aurelien Geron (O'Reilly)
Les performances des modèles d'apprentissage profond peuvent être évaluées à l'aide de métriques d'apprentissage automatique courantes, en fonction de la tâche.
Pour la classification, prenez en compte des mesures telles que l'exactitude, la précision, le rappel, le score F1 et l'aire sous la courbe (AUC). En revanche, pour la régression, nous pouvons utiliser des mesures d'erreur telles que l'erreur quadratique moyenne (RMSE).
Ces mesures devraient être utilisées pour comparer les prédictions des modèles aux étiquettes de la vérité de terrain ou aux modèles de référence. Pour les modèles et les applications plus avancés tels que le NLP, il existe une série de mesures spécifiques aux tâches linguistiques telles que le score BLEU pour la traduction, le score ROUGE pour le résumé, etc.
L'apprentissage profond est utilisé dans un large éventail d'applications du monde réel, dont voici quelques exemples :
Les questions d'entretien pour une fonction d'apprentissage profond axée sur l'ingénierie se concentreront sur des aspects tels que les cadres de programmation, les bibliothèques et les outils.
Pour construire un simple réseau neuronal feed-forward pour la classification d'images dans Tensorflow, nous pouvons commencer par définir l'architecture du modèle couche par couche en utilisant l'API séquentielle de Tensorflow.
Il s'agit notamment de spécifier le nombre approprié de neurones et de fonctions d'activation par couche et de définir la couche finale (couche de sortie) avec l'activation softmax.
Ensuite, nous compilons le modèle en spécifiant une fonction de perte appropriée telle que l'entropie croisée catégorielle, un optimiseur tel qu'Adam et des mesures de validation avant de l'entraîner sur les données d'entraînement pendant un nombre spécifié d'époques. Une fois le modèle construit, sa performance sur l'ensemble de validation peut être évaluée.
Tensorflow est couramment utilisé avec l'API Keras, que vous serez en mesure de maîtriser après avoir suivi le cours Apprentissage profond avancé avec Keras vous serez en mesure de maîtriser.
Pour gérer le surajustement dans un modèle d'apprentissage profond mis en œuvre avec PyTorch, une stratégie courante consiste à incorporer des techniques de régularisation telles que la régularisation L1 ou L2 avec des termes de pénalité ajoutés à la fonction de perte.
Il est également possible d'introduire des couches d'exclusion pour désactiver les neurones de manière aléatoire au cours de la formation, ce qui empêche le modèle de trop s'appuyer sur des caractéristiques spécifiques extraites des données.
Ces deux stratégies peuvent être combinées avec un arrêt précoce pour finaliser la formation lorsque les performances de validation commencent à se dégrader.
Vous souhaitez perfectionner vos compétences en PyTorch ? Ensuite, n'oubliez pas de consulter cette Introduction à l'apprentissage profond dans le cours PyTorch.
VGG, BERT ou ResNet sont des exemples bien connus de modèles pré-entraînés qui peuvent être chargés à des fins d'apprentissage par transfert et de réglage fin. Plus précisément, le processus consiste à remplacer la tête du modèle, c'est-à-dire la couche de classification finale, par un nouveau modèle adapté à la tâche cible.
Après cette légère modification structurelle de l'architecture du modèle, nous procédons à son réentraînement sur un nouvel ensemble de données en utilisant un faible taux d'apprentissage pour adapter les poids du modèle à la nouvelle tâche tout en conservant les principales caractéristiques apprises à l'origine par les modèles préentraînés.
Voici quelques questions potentielles que l'intervieweur pourrait vous poser pour un poste qui implique la construction ou la gestion de solutions d'apprentissage profond dans des applications de vision par ordinateur comme le traitement d'images.
Les CNN sont des architectures d'apprentissage profond spécialisées dans le traitement des données visuelles. Leur empilement de couches de convolution et les opérations sous-jacentes sur les données d'image sont conçus pour imiter le cortex visuel dans le cerveau des animaux.
Les CNN excellent dans des tâches telles que la classification d'images, la détection d'objets et la segmentation d'images. Voici une brève description des cas d'utilisation pour chacune de ces tâches :
Les couches de convolution des CNN sont responsables de l'extraction des caractéristiques des images d'entrée. Ils appliquent un ensemble de poids apprenables, appelés filtres ou noyaux, pour détecter des motifs et des caractéristiques tels que les bords, les formes et les textures, ainsi que leurs informations et relations spatiales, ce qui permet d'apprendre des représentations visuelles hiérarchiques.
Parallèlement, les couches de mise en commun sous-échantillonnent les cartes de caractéristiques (représentations d'images intermédiaires) produites par les couches de convolution. En d'autres termes, leur dimension spatiale ou résolution d'origine est réduite tout en conservant les informations extraites importantes.
La combinaison de couches de convolution successives avec des couches de mise en commun dans un CNN permet d'accroître la robustesse aux variations des entrées, de réduire la complexité informatique au moment de l'apprentissage et de l'inférence, et d'éviter des problèmes tels que l'ajustement excessif (overfitting).
Parmi les défis et les limites habituels des modèles d'apprentissage profond, les exemples suivants sont particulièrement accentués dans les modèles de vision artificielle tels que les CNN :
Voici quelques questions potentielles que votre interlocuteur pourrait vous poser pour un poste impliquant l'exploitation de technologies d'apprentissage profond dans des applications NLP.
Les transformateurs sont une famille révolutionnaire d'architectures d'apprentissage profond et constituent l'état de l'art actuel pour traiter un large éventail de problèmes de PNL. Les mécanismes d'attention sont essentiels aux architectures de transformation qui sous-tendent les grands modèles de langage (LLM) tels que BERT et GPT et sont en grande partie responsables de leur succès.
Les transformateurs ont la capacité de capturer des modèles complexes, des informations contextuelles et des dépendances à long terme entre les éléments d'un texte d'entrée, ce qui permet de surmonter les problèmes rencontrés dans les solutions précédentes, comme la mémoire limitée des RNN (réseaux neuronaux récurrents).
Les mécanismes d'attention évaluent essentiellement l'importance de chaque jeton d'une séquence, sans qu'il soit nécessaire de la traiter jeton par jeton.
Ce composant important des transformateurs a permis des avancées significatives dans des tâches telles que la classification de textes, la génération de langues et le résumé de textes, et a révolutionné le domaine des LLM et de l'IA dans son ensemble.
Cours de DataCamp sur Introduction aux LLMs en Python vous permet non seulement d'acquérir des compétences pratiques pour construire et exploiter des LLM, mais aussi une solide compréhension des principaux concepts entourant les LLM et les architectures de transformateurs.
Le pré-entraînement de modèle entraîne un modèle d'apprentissage profond, tel que BERT, pour la classification de textes, sur un grand corpus de données textuelles (des millions à des milliards d'exemples de textes) afin d'apprendre les représentations du langage pour une compréhension du langage à des fins générales.
L'affinage du modèle, quant à lui, consiste à prendre un modèle pré-entraîné et à affiner ses paramètres d'apprentissage sur une application NLP spécifique en aval, par exemple l'analyse des sentiments dans les commentaires d'hôtels.
Étant donné que le réglage fin est généralement destiné à des cas d'utilisation spécifiques, il nécessite l'utilisation d'un petit ensemble de données d'exemples de textes étiquetés spécifiques à un domaine, ce qui permet d'adapter les poids dans certaines parties du modèle afin d'apprendre les nuances de la tâche cible et d'améliorer les performances du modèle dans ce contexte spécifique sans les coûts de calcul et les exigences en matière de données de l'apprentissage d'un modèle à partir de zéro.
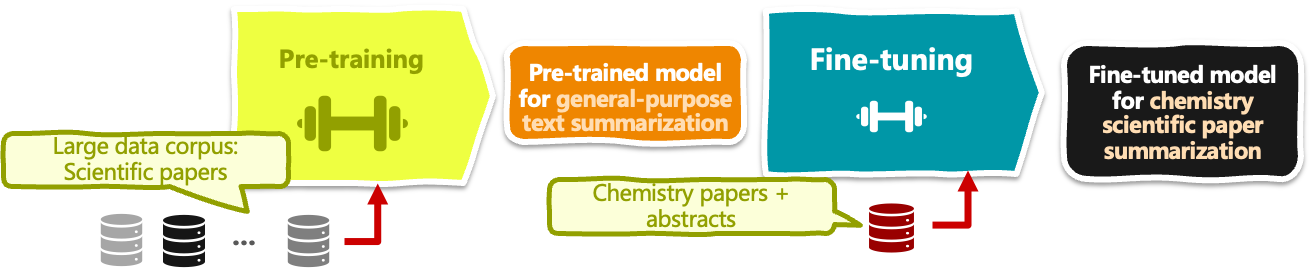
Exemple de pré-entraînement de modèle et de réglage fin d'un LLM pour le résumé d'articles de chimie | Iván Palomares
L'architecture du BERT est une variante simplifiée du transformateur codeur-décodeur original, appelé transformateur codeur seul.
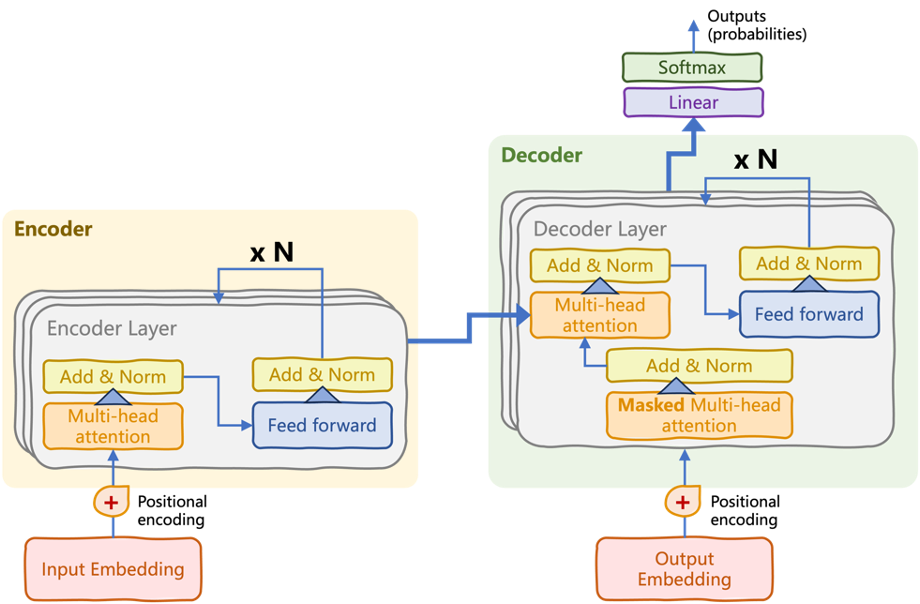
L'architecture originale du transformateur, divisée en piles de codage et de décodage | Introduction aux LLM en Python (Iván Palomares)
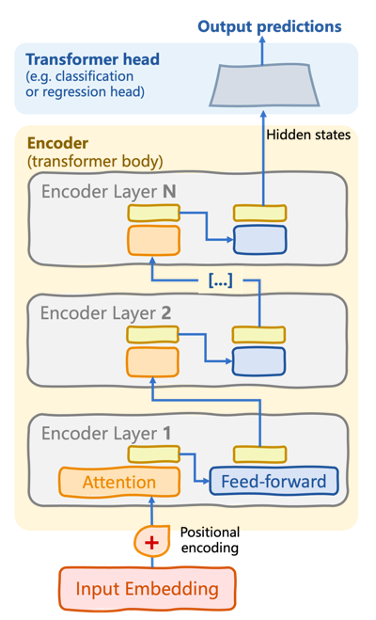
Architecture de transformateur codant uniquement utilisée par des modèles comme BERT | Introduction aux LLM en Python (Iván Palomares)
La pile de codage se compose de plusieurs couches de codage (voir le schéma ci-dessus). Dans chaque couche, il y a des (sous-)couches de mécanismes d'auto-attention et de réseaux neuronaux de type "feedforward". La clé du processus de compréhension du langage entrepris par BERT réside dans le flux d'attention bidirectionnel appliqué itérativement au sein de l'encodeur, de sorte que les dépendances entre les mots d'une séquence d'entrée sont saisies dans les deux sens. Les connexions neuronales ascendantes "relient" ces dépendances apprises en des schémas de langage plus complexes.
Outre cette caractéristique générale des transformateurs à codeur uniquement, le BERT se caractérise par l'incorporation d'une approche de modélisation en langage masqué (MLM). Ce mécanisme est utilisé pendant le préapprentissage pour masquer certains mots au hasard, obligeant ainsi le modèle à apprendre à prédire les mots masqués en se basant sur la compréhension du contexte qui les entoure.
Terminons par les trois questions que l'on pourrait vous poser si vous postulez à un poste dans le domaine de l'apprentissage profond.
La stratégie combinée suivante peut être mise en œuvre pour maximiser les performances des modèles d'apprentissage profond lorsqu'ils sont confrontés au problème courant des données d'apprentissage limitées :
Le déploiement de solutions d'apprentissage profond à grande échelle dans des environnements de production exige de prêter attention à plusieurs considérations, dont trois sont les suivantes :
D'autres considérations importantes pour le déploiement de modèles d'apprentissage profond dans la production comprennent l'infrastructure matérielle et réseau, la surveillance du système et l'intégration transparente avec les cadres logiciels existants.
Les récentes percées dans le domaine de l'apprentissage profond ont le potentiel de remodeler profondément de nombreuses industries, voire d'en créer de nouvelles.
Les mécanismes d'attention utilisés dans les architectures de transformation derrière les LLM révolutionnent le domaine du NLP, repoussant considérablement les limites des tâches NLP et permettant des interactions homme-machine plus sophistiquées par le biais de solutions d'IA conversationnelle, de réponses aux questions, et bien plus encore. L'inclusion récente de la génération augmentée par récupération (RAG) dans l'équation aide encore davantage les MLD à produire un langage véridique et fondé sur des preuves.
L'apprentissage par renforcement est l'une des tendances les plus prometteuses de l'IA, car ses principes imitent les bases de l'apprentissage humain. Son intégration dans les architectures d'apprentissage profond, en particulier les modèles génératifs tels que les réseaux adversaires génératifs, est aujourd'hui à la pointe de la recherche universitaire. De grands noms comme OpenAI, Google et Microsoft combinent ces deux domaines de l'IA dans leurs dernières solutions révolutionnaires capables de générer un contenu "réel" dans de multiples formats.
Ces progrès et d'autres avancées récentes ont radicalement démocratisé l'utilisation de l'IA par la société. Il est donc opportun de se pencher sur l'éthique, les aspects juridiques et les réglementations de l'IA en tant que question clé sur laquelle travailler pour garantir un impact bénéfique des solutions d'apprentissage en profondeur dans la société.
Pour conclure cette exploration des questions d'entretien les plus courantes en matière d'apprentissage profond, il est évident que la clé du succès repose sur un mélange de fondements théoriques, une solide maîtrise des compétences pratiques et la nécessité de rester au fait des dernières avancées.
L'apprentissage profond n'est pas seulement une question d'algorithmes, de modèles et de choix d'architecture. Il s'agit d'identifier les meilleures solutions pour résoudre les problèmes de données du monde réel.
L'apprentissage continu est essentiel. DataCamp vous propose une formation approfondie sur le thème de l'apprentissage en profondeur. Apprentissage profond en Python ainsi que deux cursus axés sur les applications de l'apprentissage profond : traitement d'images et traitement du langage naturel. Ces cursus offrent une feuille de route structurée pour améliorer vos compétences en matière d'apprentissage approfondi, vous assurant ainsi d'être prêt pour votre prochain entretien.
Enfin, consultez les dernières sections de cet article sur les questions d'entretien relatives à l'apprentissage automatique si vous recherchez des conseils généraux sur la manière de préparer votre entretien relatif à l'apprentissage profond. L'apprentissage profond étant un sous-domaine de l'apprentissage automatique, la combinaison de ces lignes directrices générales et des 20 questions sur l'apprentissage profond que nous avons passées en revue ici vous aidera certainement à vous préparer.
Poursuivez votre voyage d'apprentissage en profondeur dès aujourd'hui !
Cursus
Cours
Cours