
Kurs
Extreme Gradient Boosting mit XGBoost
4 Std.
60.7K
Python ist eine der beliebtesten Programmiersprachen, die in vielen technischen Bereichen genutzt wird, vor allem in der Datenwissenschaft und im maschinellen Lernen. Python ist eine einfach zu programmierende, objektorientierte Hochsprache mit einer großen Auswahl an Bibliotheken für viele verschiedene Anwendungsfälle. Es hat über 200.000 Bibliotheken.
Einer der Gründe, warum Python für die Datenwissenschaft so wichtig ist, ist die riesige Auswahl an Bibliotheken für Datenbearbeitung, Datenvisualisierung, maschinelles Lernen und Deep Learning. Da Python so viele tolle Bibliotheken für Datenwissenschaft hat, ist es echt unmöglich, alles in einem Artikel zu erklären. Die Liste der besten Bibliotheken hier konzentriert sich nur auf fünf Hauptbereiche:
Es gibt noch viele andere Bereiche, die hier nicht aufgeführt sind, zum Beispiel MLOps, Big Data und Computer Vision. Die Liste in diesem Blog ist nicht in irgendeiner bestimmten Reihenfolge und soll auch nicht als eine Art Rangliste verstanden werden.
NumPy ist eine der am häufigsten genutzten Open-Source-Python-Bibliotheken und wird hauptsächlich für wissenschaftliche Berechnungen verwendet. Die eingebauten Mathefunktionen machen blitzschnelle Berechnungen möglich und können mit mehrdimensionalen Daten und großen Matrizen umgehen. Es wird auch in der linearen Algebra benutzt. NumPy-Arrays werden oft lieber als Listen benutzt, weil sie weniger Speicher brauchen und praktischer und effizienter sind.
Laut der Website von NumPy ist es ein Open-Source-Projekt, das numerische Berechnungen mit Python ermöglichen soll. Es wurde 2005 entwickelt und basiert auf den frühen Arbeiten der Bibliotheken Numeric und Numarray. Einer der großen Vorteile von NumPy ist, dass es unter der modifizierten BSD-Lizenz veröffentlicht wurde und somit für alle immer kostenlos nutzbar sein wird.
NumPy wird auf GitHub entwickelt, und zwar mit dem Einverständnis der NumPy-Community und der größeren wissenschaftlichen Python-Community. Mehr dazu erfährst du in unserem Einführungskurs zu Numpy.
⭐ GitHub-Sterne: 25K | Gesamtzahl der Downloads: 2,4 Milliarden
Pandas ist eine Open-Source-Bibliothek, die man oft in der Datenwissenschaft benutzt. Es wird hauptsächlich für die Datenanalyse, Datenbearbeitung und Datenbereinigung genutzt. Pandas machen es einfach, Daten zu modellieren und zu analysieren, ohne dass man viel Code schreiben muss. Wie auf ihrer Website steht, ist pandas ein schnelles, leistungsstarkes, flexibles und einfach zu bedienendes Open-Source-Tool zur Datenanalyse und -bearbeitung. Ein paar wichtige Features dieser Bibliothek sind:
Der Einstieg in Pandas ist echt einfach und unkompliziert. Du kannst dir „Analyzing Police Activity with pandas” von DataCamp anschauen, um zu lernen, wie man pandas mit echten Datensätzen benutzt.
⭐ GitHub-Sterne: 41K | Gesamtzahl der Downloads: 1,6 Milliarden
Während Pandas immer noch der Standard für kleine Datenmengen ist, hat sich Polars zum Standard für die Hochleistungsdatenverarbeitung entwickelt. Es ist in Rust geschrieben und nutzt eine „Lazy Evaluation”-Engine, um Datensätze (10 GB–100 GB+) zu verarbeiten, die normalerweise Maschinen mit begrenztem RAM zum Absturz bringen würden. Anders als Pandas, das Operationen nacheinander macht, optimiert Polars Abfragen von Anfang bis Ende und führt sie parallel auf allen verfügbaren CPU-Kernen aus.
Es ist als Drop-in-Upgrade für schwere Workloads gedacht und bietet eine Syntax, die oft besser lesbar und 10- bis 50-mal schneller ist als herkömmliche DataFrame.
Hier ist ein Beispiel für einen Code, der eine gefilterte, gruppierte und zusammengefasste Auswahl aus einem riesigen CSV-Datensatz macht:
import polars as pl
# Lazy evaluation: Nothing runs until .collect() is called
# allowing Polars to optimize the query plan beforehand
q = (
pl.scan_csv("massive_dataset.csv")
.filter(pl.col("category") == "Technology")
.group_by("region")
.agg(pl.col("sales").sum())
)
df = q.collect() # Executes in parallel⭐ GitHub-Sterne: 40K+ | Status: Hochleistungsstandard
Matplotlib ist eine umfangreiche Bibliothek zum Erstellen von festen, interaktiven und animierten Python-Visualisierungen. Viele Pakete von Drittanbietern erweitern und bauen auf den Funktionen von Matplotlib auf, darunter mehrere höherwertige Schnittstellen zum Zeichnen von Diagrammen (Seaborn, HoloViews, ggplot usw.).
Matplotlib ist so gemacht, dass es genauso gut funktioniert wie MATLAB, und man kann zusätzlich Python nutzen. Außerdem ist es kostenlos und Open Source. Damit kann man Daten mit verschiedenen Diagrammtypen anschauen, zum Beispiel Streudiagramme, Histogramme, Balkendiagramme, Fehlerdiagramme und Boxplots. Außerdem kannst du alle Visualisierungen mit nur ein paar Zeilen Code machen.
Beispielgrafiken, die mit Matplotlib erstellt wurden
Starte mit diesem Schritt-für-Schritt-Tutorial in Matplotlib.
⭐ GitHub-Sterne: 18,7K | Gesamtzahl der Downloads: 653 Millionen
Seaborn ist ein weiteres beliebtes Python-Framework zur Datenvisualisierung, das auf Matplotlib basiert. Es ist eine hochentwickelte Schnittstelle zum Erstellen von ästhetisch ansprechenden und wertvollen statistischen Darstellungen, die für die Untersuchung und das Verständnis von Daten entscheidend sind. Diese Python-Bibliothek ist eng mit den Datenstrukturen von NumPy und pandas verbunden. Das Hauptziel von Seaborn ist es, die Visualisierung zu einem wichtigen Teil der Datenanalyse und -erkundung zu machen. Deshalb nutzen seine Plotting-Algorithmen Datenrahmen, die ganze Datensätze abdecken.
Seaborn-Beispielgalerie
Dieses Seaborn-Tutorial für Anfänger ist super, um dich mit dieser dynamischen Visualisierungsbibliothek vertraut zu machen.
⭐ GitHub-Sterne: 11,6K | Gesamtzahl der Downloads: 180 Millionen
Die super beliebte Open-Source-Grafikbibliothek Plotly kann man nutzen, um interaktive Datenvisualisierungen zu erstellen. Plotly basiert auf der Plotly-JavaScript-Bibliothek (plotly.js) und kann verwendet werden, um webbasierte Datenvisualisierungen zu erstellen, die als HTML-Dateien gespeichert oder in Jupyter-Notebooks und Webanwendungen mit Dash angezeigt werden können.
Es bietet über 40 einzigartige Diagrammtypen, wie zum Beispiel Streudiagramme, Histogramme, Liniendiagramme, Balkendiagramme, Kreisdiagramme, Fehlerbalken, Boxplots, mehrere Achsen, Sparklines, Dendrogramme und 3D-Diagramme. Plotly hat auch Konturdiagramme, die in anderen Bibliotheken für Datenvisualisierung nicht so oft vorkommen.
Wenn du interaktive Visualisierungen oder Dashboard-ähnliche Grafiken willst, ist Plotly eine gute Alternative zu Matplotlib und Seaborn. Es steht derzeit unter der MIT-Lizenz zur Verfügung.
Mit diesem Plotly-Visualisierungskurs kannst du noch heute anfangen, Plotly zu meistern.
⭐ GitHub-Sterne: 14,7K | Gesamtzahl der Downloads: 190 Millionen
Die Begriffe „maschinelles Lernen“ und „scikit-learn“ sind untrennbar miteinander verbunden. Scikit-learn ist eine der am häufigsten genutzten Bibliotheken für maschinelles Lernen in Python. Es basiert auf NumPy, SciPy und Matplotlib und ist eine Open-Source-Python-Bibliothek, die unter der BSD-Lizenz kommerziell genutzt werden kann. Es ist ein einfaches und effizientes Tool für Aufgaben der prädiktiven Datenanalyse.
Scikit-learn wurde 2007 als Google Summer of Code-Projekt gestartet und ist ein gemeinschaftliches Projekt. Aber institutionelle und private Fördermittel helfen dabei, dass es weiterläuft.
Das Beste an scikit-learn ist, dass es echt einfach zu benutzen ist.
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
# Load the diabetes dataset
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
# Use only one feature
diabetes_X = diabetes_X[:, np.newaxis, 2]
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes_y[:-20]
diabetes_y_test = diabetes_y[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)Quelle: Code aus der offiziellen Dokumentation von scikit-learn.
Du kannst scikit-learn mit diesem Tutorial für Anfänger selbst ausprobieren.
⭐ GitHub-Sterne: 57K | Gesamtzahl der Downloads: 703 Millionen
Die Zeiten, in denen Datenwissenschaftler nur statische PDF-Berichte geliefert haben, sind vorbei. Streamlit macht aus Python-Skripten in wenigen Minuten interaktive Web-Apps, die man teilen kann. Du brauchst keine Kenntnisse in HTML, CSS oder JavaScript. Im Jahr 2025 wird es oft benutzt, um interne Tools, Dashboard-Prototypen und interaktive Modelldemos für die Beteiligten zu erstellen.
Mit einfachen API-Aufrufen wie st.write() und st.slider() kannst du ein Frontend erstellen, das in Echtzeit auf Datenänderungen reagiert und so die Lücke zwischen Analyse und Technik schließt.
⭐ GitHub-Sterne: 42K+ | Status: Wichtig für die Lieferung
Pydantic war mal ein Tool für die Webentwicklung, ist jetzt aber ein wichtiger Teil des KI-Stacks. Es macht Datenvalidierung und verwaltet Einstellungen mit Python-Typ-Annotationen. Im Zeitalter der LLMs ist es echt wichtig, dass die Daten (und die Modellergebnisse) genau einem bestimmten Schema entsprechen.
Pydantic ist die Engine, die Bibliotheken wie LangChain und Hugging Face antreibt. Sie sorgt dafür, dass die chaotischen JSON-Ausgaben von KI-Modellen in strukturierte, gültige Python-Objekte umgewandelt werden, die deinen nachgelagerten Code nicht kaputt machen.
⭐ GitHub-Sterne: 26K+ | Status: Kritische Infrastruktur
LightGBM ist eine super beliebte Open-Source-Bibliothek für Gradient Boosting, die Algorithmen auf Basis von Entscheidungsbäumen nutzt. Es hat folgende Vorteile:
Es kann sowohl für überwachte Klassifizierungs- als auch für Regressionsaufgaben verwendet werden. Du kannst dir die offizielle Dokumentation oder deren GitHub ansehen, um mehr über dieses tolle Framework zu erfahren.
⭐ GitHub-Sterne: 15,8K | Gesamtzahl der Downloads: 162 Millionen
XGBoost ist eine weitere weit verbreitete Bibliothek für verteiltes Gradientenboosting, die portabel, flexibel und effizient ist. Es ermöglicht die Implementierung von Algorithmen für maschinelles Lernen innerhalb des Gradient-Boosting-Frameworks. XGBoost bietet (GBDT) gradientenverstärkte Entscheidungsbäume, ein paralleles Baum-Boosting, das schnell und genau Lösungen für viele Probleme in der Datenwissenschaft liefert. Der gleiche Code läuft auf den wichtigsten verteilten Umgebungen (Hadoop, SGE, MPI) und kann unzählige Probleme lösen.
XGBoost ist in den letzten Jahren richtig beliebt geworden, weil es Leuten und Teams geholfen hat, fast jeden Kaggle-Wettbewerb mit strukturierten Daten zu gewinnen. Zu den Vorteilen von XGBoost gehören:
XGBoost wurde von aktiven Community-Mitgliedern entwickelt und wird von ihnen gepflegt. Es kann unter der Apache-Lizenz genutzt werden. Dieses XGBoost-Tutorial ist eine super Quelle, wenn du mehr darüber erfahren möchtest.
⭐ GitHub-Sterne: 25,2K | Gesamtzahl der Downloads: 179 Millionen
Catboost ist eine schnelle, skalierbare und leistungsstarke Gradientenverstärkungsbibliothek für Entscheidungsbäume, die für Ranking, Klassifizierung, Regression und andere Machine-Learning-Aufgaben für Python, R, Java und C++ verwendet wird. Es unterstützt Berechnungen auf CPU und GPU.
Als Nachfolger des MatrixNet-Algorithmus wird er oft für Ranking-Aufgaben, Prognosen und Empfehlungen genutzt. Weil es so vielseitig ist, kann man es in vielen Bereichen und für verschiedene Probleme nutzen.
Die Vorteile von CatBoost sind laut ihrem Repository:
⭐ GitHub-Sterne: 7,5K | Gesamtzahl der Downloads: 53 Millionen
Statsmodels hat Klassen und Funktionen, mit denen man verschiedene statistische Modelle schätzen, statistische Tests machen und statistische Daten untersuchen kann. Für jeden Schätzer gibt's dann eine umfassende Liste mit Ergebnisstatistiken. Die Genauigkeit der Ergebnisse kann dann mit vorhandenen Statistikpaketen überprüft werden.
Die meisten Testergebnisse in der Bibliothek wurden mit mindestens einem anderen Statistikpaket überprüft: R, Stata oder SAS. Einige Funktionen von statsmodels sind:
Dieser Einführungskurs zu statistischen Modellen ist super, wenn du mehr darüber lernen willst.
⭐ GitHub-Sterne: 9,2K | Gesamtzahl der Downloads: 161 Millionen
Die RAPIDS-Suite von Open-Source-Softwarebibliotheken macht die ganze Datenwissenschaft und Analyse-Pipelines komplett auf GPUs. Mit Dask lässt es sich nahtlos von GPU-Workstations auf Multi-GPU-Server und Multi-Node-Cluster skalieren. Das Projekt wird von NVIDIA unterstützt und nutzt auch Numba, Apache Arrow und viele andere Open-Source-Projekte.
cuDF ist eine GPU-DataFrame-Bibliothek, mit der man Daten laden, verbinden, zusammenfassen, filtern und auf andere Weise bearbeiten kann. Es wurde auf Basis des spaltenorientierten Speicherformats von Apache Arrow entwickelt. Es bietet eine pandas-ähnliche API, die Dateningenieuren und Datenwissenschaftlern vertraut sein wird und es ihnen ermöglicht, ihre Arbeitsabläufe einfach zu beschleunigen, ohne sich mit den Details der CUDA-Programmierung befassen zu müssen.
cuML ist eine Reihe von Bibliotheken, die Algorithmen für maschinelles Lernen und mathematische Grundfunktionen implementieren, die kompatible APIs mit anderen RAPIDS-Projekten teilen. Damit können Datenwissenschaftler, Forscher und Softwareentwickler klassische tabellarische ML-Aufgaben auf GPUs ausführen, ohne sich mit den Details der CUDA-Programmierung beschäftigen zu müssen. Die Python-API von cuML passt normalerweise zur scikit-learn-API.
Dieses Open-Source-Framework zur Hyperparameter-Optimierung wird hauptsächlich benutzt, um die Suche nach Hyperparametern zu automatisieren. Es nutzt Python-Schleifen, Bedingungen und Syntax, um automatisch nach den besten Hyperparametern zu suchen. Außerdem kann es große Bereiche durchsuchen und aussichtslose Versuche aussortieren, um schneller Ergebnisse zu kriegen. Das Beste daran ist, dass es einfach parallelisiert und auf große Datensätze skaliert werden kann.
Wichtigste Features laut ihrem GitHub-Repository:
⭐ GitHub-Sterne: 9,1K | Gesamtzahl der Downloads: 18 Millionen
Diese mega beliebte Open-Source-Bibliothek für maschinelles Lernen macht Workflows für maschinelles Lernen in Python mit echt wenig Code automatisch. Es ist ein Tool für die Modellverwaltung und maschinelles Lernen, das den Versuchszyklus echt beschleunigen kann.
Im Vergleich zu anderen Open-Source-Bibliotheken für maschinelles Lernen bietet PyCaret eine Low-Code-Lösung, die Hunderte von Codezeilen durch nur wenige ersetzen kann. Das macht Experimente echt schnell und effizient.
PyCaret kann man im Moment unter der MIT-Lizenz nutzen. Wenn du mehr über PyCaret erfahren willst, kannst du dir die offizielle Doku oder das GitHub-Repository anschauen oder dieses Einführungs-Tutorial zu PyCaret durchgehen.
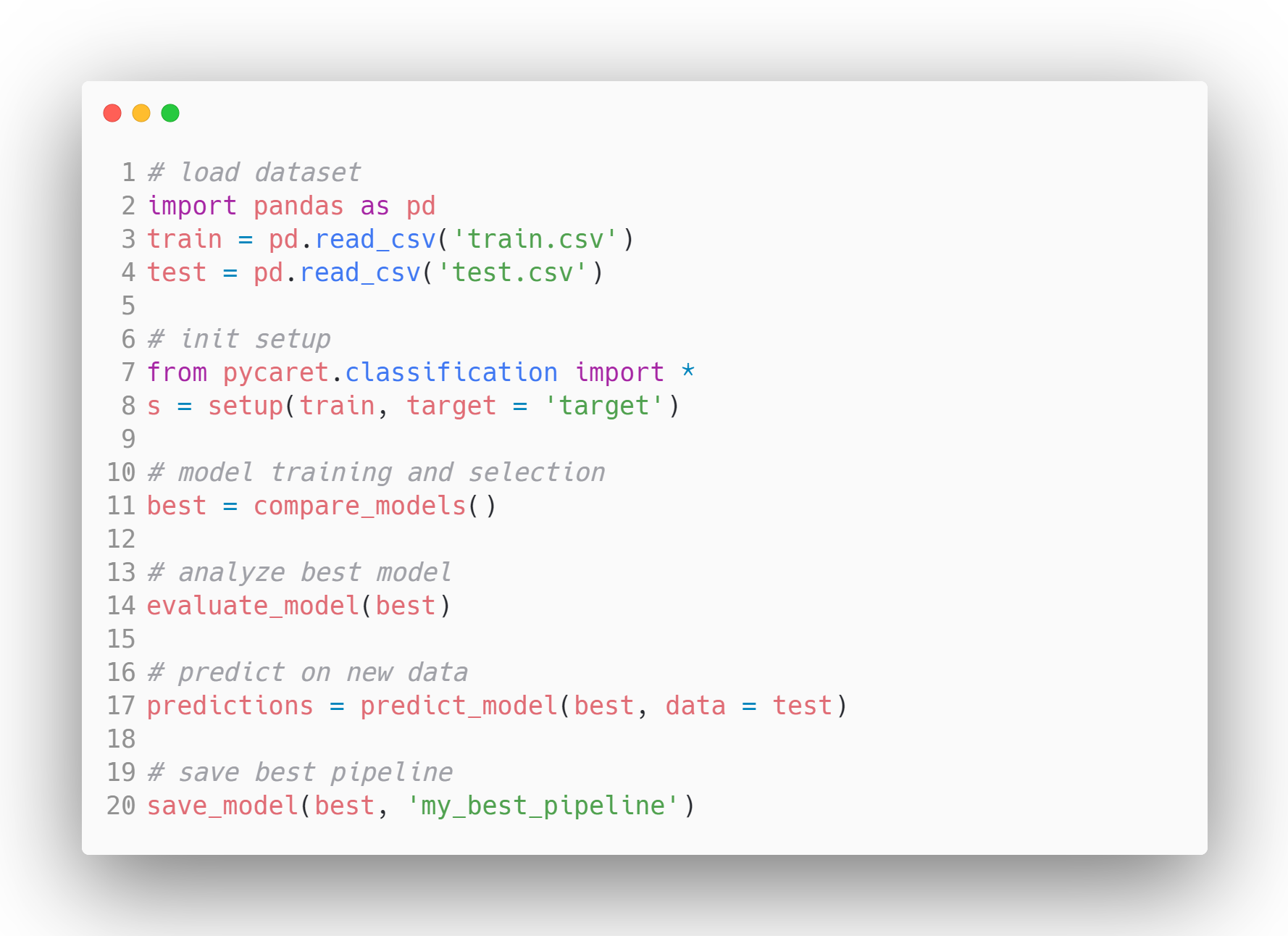
in PyCaret – Quelle
⭐ GitHub-Sterne: 8,1K | Gesamtzahl der Downloads: 3,9 Millionen
H2O ist eine Plattform für maschinelles Lernen und prädiktive Analysen, mit der man Modelle für maschinelles Lernen auf Big Data aufbauen kann. Außerdem macht es die einfache Produktion dieser Modelle in einer Unternehmensumgebung möglich.
Der Kerncode von H2O ist in Java geschrieben. Die Algorithmen nutzen das Java Fork/Join-Framework für Multithreading und laufen auf dem verteilten Map/Reduce-Framework von H2O.
H2O ist unter der Apache-Lizenz, Version 2.0, lizenziert und für die Sprachen Python, R und Java verfügbar. Mehr über H2O AutoML erfährst du in der offiziellen Dokumentation.
⭐ GitHub-Sterne: 10,6K | Gesamtzahl der Downloads: 15,1 Millionen
Auto-sklearn ist ein Toolkit für automatisiertes maschinelles Lernen und ein guter Ersatz für ein scikit-learn-Modell. Es macht die Hyperparameter-Optimierung und Algorithmusauswahl automatisch, was den Leuten, die mit maschinellem Lernen arbeiten, echt viel Zeit spart. Das Design zeigt die neuesten Fortschritte beim Meta-Lernen, beim Aufbau von Ensembles und bei der Bayes'schen Optimierung.
Auto-sklearn ist als Add-on zu scikit-learn entwickelt worden und nutzt ein bayessches Optimierungsverfahren, um die leistungsstärkste Modellpipeline für einen bestimmten Datensatz zu finden.
Auto-sklearn ist echt einfach zu bedienen und kann sowohl für überwachte Klassifizierungs- als auch für Regressionsaufgaben genutzt werden.
import autosklearn.classification
cls = autosklearn.classification.AutoSklearnClassifier()
cls.fit(X_train, y_train)
predictions = cls.predict(X_test)Quelle: Beispiel aus der offiziellen Dokumentation von auto-sklearn.
Mehr über auto-sklearn erfährst du in ihrem GitHub-Repository.
⭐ GitHub-Sterne: 7,3K | Gesamtzahl der Downloads: 675K
FLAML ist eine schlanke Python-Bibliothek, die automatisch genaue Modelle für maschinelles Lernen findet. Es sucht automatisch Lernende und Hyperparameter aus, was den Leuten, die sich mit maschinellem Lernen beschäftigen, viel Zeit und Mühe spart. Laut ihrem GitHub-Repository hat FLAML unter anderem diese Features:
Mit nur drei Zeilen Code kannst du mit dieser schnellen AutoML-Engine einen Schätzer im Stil von scikit-learn bekommen.
from flaml import AutoML
automl = AutoML()
automl.fit(X_train, y_train, task="classification")Quelle: Beispiel aus dem offiziellen GitHub-Repository
⭐ GitHub-Sterne: 3,5K | Gesamtzahl der Downloads: 456K
Während andere AutoML-Bibliotheken auf Geschwindigkeit setzen, geht es bei AutoGluon (von Amazon entwickelt) um Robustheit und modernste Genauigkeit. Es ist bekannt für seine „Multi-Layer-Stack-Ensembling“-Strategie, mit der es oft besser abschneidet als von Menschen entwickelte Modelle bei tabellarischen Daten-Benchmarks.
Es unterstützt nicht nur tabellarische Daten, sondern auch multimodale Probleme. Das heißt, du kannst einen einzelnen Prädiktor auf einem Datensatz trainieren, der Spalten mit Text, Bildern und Zahlen gleichzeitig enthält, ohne dass du dich mit kompliziertem Feature Engineering beschäftigen musst.
Der folgende Codeausschnitt zeigt dir die AutoGluon-Syntax:
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label='class').fit(train_data)
# AutoGluon automatically trains, tunes, and ensembles multiple models⭐ GitHub-Sterne: 10.000+ | Status: Top-Genauigkeit
TensorFlow ist eine beliebte Open-Source-Bibliothek für leistungsstarke numerische Berechnungen, die vom Google Brain-Team bei Google entwickelt wurde und ein wichtiger Bestandteil im Bereich der Deep-Learning-Forschung ist.
Wie auf der offiziellen Website steht, ist TensorFlow eine durchgängige Open-Source-Plattform für maschinelles Lernen. Es bietet ein umfangreiches, vielseitiges Sortiment an Tools, Bibliotheken und Community-Ressourcen für Forscher und Entwickler im Bereich maschinelles Lernen.
Ein paar der Features von TensorFlow, die es zu einer beliebten und weit verbreiteten Deep-Learning-Bibliothek gemacht haben:
Wenn du mehr über TensorFlow erfahren willst, schau dir den offiziellen Leitfaden oder das GitHub-Repository an oder probier es selbst aus, indem du diesem Schritt-für-Schritt -Tutorial zu TensorFlow folgst.
⭐ GitHub-Sterne: 180K | Gesamtzahl der Downloads: 384 Millionen
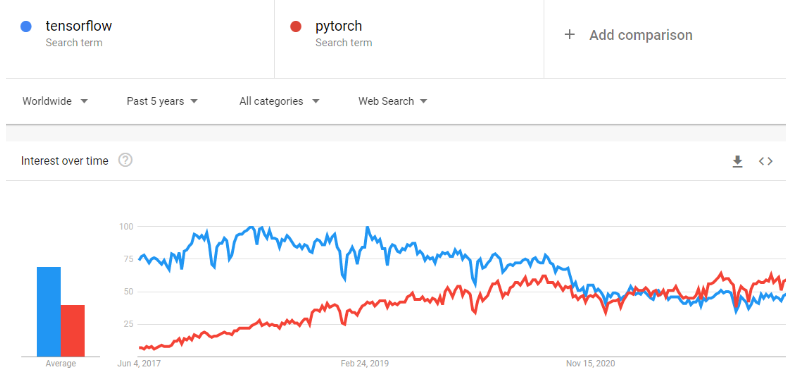
PyTorch ist ein Framework für maschinelles Lernen, das den Weg vom Forschungsprototyp bis zur Produktion echt beschleunigt. Es ist eine optimierte Tensor-Bibliothek für Deep Learning mit GPUs und CPUs und gilt als Alternative zu TensorFlow. Mit der Zeit ist PyTorch immer beliebter geworden und hat TensorFlow bei Google Trends überholt.
Es wurde von Facebook entwickelt und wird von Facebook gepflegt und ist im Moment unter BSD verfügbar.
Laut der offiziellen Website sind die wichtigsten Features von PyTorch:
⭐ GitHub-Sterne: 74K | Gesamtzahl der Downloads: 119 Millionen
FastAI ist eine Deep-Learning-Bibliothek, die Leuten hochwertige Komponenten bietet, mit denen man ganz einfach top Ergebnisse erzielen kann. Es hat auch einfache Teile, die man austauschen kann, um neue Sachen zu entwickeln. Es soll beides schaffen, ohne dabei die Benutzerfreundlichkeit, Flexibilität oder Leistung großartig zu beeinträchtigen.
Eigenschaften:
Mehr über das Projekt erfährst du in der offiziellen Dokumentation.
⭐ GitHub-Sterne: 25,1K | Gesamtzahl der Downloads: 6,1 Millionen
Keras ist eine Deep-Learning-API, die für Menschen und nicht für Maschinen entwickelt wurde. Keras hält sich an bewährte Methoden, um die kognitive Belastung zu reduzieren: Es bietet einheitliche und einfache APIs, minimiert die Anzahl der für gängige Anwendungsfälle erforderlichen Benutzeraktionen und liefert klare und umsetzbare Fehlermeldungen. Keras ist so einfach zu bedienen, dass TensorFlow es in der Version TF 2.0 als Standard-API übernommen hat.
Keras macht es einfacher, neuronale Netze zu beschreiben, und hat auch ein paar echt coole Tools für die Entwicklung von Modellen, die Verarbeitung von Datensätzen, die Visualisierung von Graphen und vieles mehr.
Eigenschaften:
Wenn du mehr über Keras erfahren willst, schau dir die offizielle Dokumentation an oder mach diesen Einführungskurs: Deep Learning mit Keras.
⭐ GitHub-Sterne: 60,2K | Gesamtzahl der Downloads: 163 Millionen
PyTorch Lightning hat eine coole Schnittstelle für PyTorch. Sein leistungsstarkes und leichtes Framework kann PyTorch-Code so organisieren, dass die Forschung vom Engineering getrennt wird, wodurch Deep-Learning-Experimente einfacher zu verstehen und zu reproduzieren sind. Es wurde entwickelt, um skalierbare Deep-Learning-Modelle zu erstellen, die problemlos auf verteilter Hardware laufen.
Laut der offiziellen Website ist PyTorch Lightning so gemacht, dass du mehr Zeit mit Forschung und weniger mit Technik verbringen kannst. Mit einer schnellen Umgestaltung kannst du:
Mehr über diese Bibliothek erfährst du auf ihrer offiziellen Website.
⭐ GitHub-Sterne: 25,6K | Gesamtzahl der Downloads: 18,2 Millionen
JAX ist eine von Google entwickelte Hochleistungsbibliothek für numerische Berechnungen. Während PyTorch der benutzerfreundliche Standard ist, ist JAX das „Formel-1-Auto” für Forscher (einschließlich DeepMind), die extrem hohe Geschwindigkeit brauchen. Damit kann NumPy-Code automatisch kompiliert werden, um über XLA (Accelerated Linear Algebra) auf Beschleunigern (GPUs/TPUs) zu laufen.
Die Möglichkeit, native Python-Funktionen automatisch zu differenzieren, macht es super für die Entwicklung neuer Algorithmen von Grund auf, vor allem bei generativen Modellen und Physiksimulationen.
⭐ GitHub-Sterne: 35K+ | Status: Forschungsstandard
spaCy ist eine leistungsstarke Open-Source-Bibliothek für die Verarbeitung natürlicher Sprache in Python. spaCy ist super für große Aufgaben im Bereich der Informationsextraktion. Es wurde komplett in Cython geschrieben, das sorgfältig den Speicher verwaltet. spaCy ist die perfekte Bibliothek, wenn deine Anwendung riesige Web-Dumps verarbeiten muss.
Eigenschaften:
Mehr über spaCy erfährst du auf der offiziellen Website oder im GitHub-Repository. Mit diesem praktischen spaCY-Spickzettel kannst du dich schnell mit den Funktionen vertraut machen.
⭐ GitHub-Sterne: 28K | Gesamtzahl der Downloads: 81 Millionen
Hugging Face Transformers ist eine Open-Source-Bibliothek von Hugging Face. Transformatoren machen es APIs einfach, moderne, vorab trainierte Modelle runterzuladen und zu trainieren. Mit vorab trainierten Modellen kannst du deine Rechenkosten und deinen CO2-Fußabdruck senken und sparst Zeit, weil du das Modell nicht von Grund auf neu trainieren musst. Die Modelle passen für viele verschiedene Sachen, zum Beispiel:
Die Transformers-Bibliothek macht die nahtlose Integration zwischen drei der beliebtesten Deep-Learning-Bibliotheken möglich: PyTorch, TensorFlow, and JAX. Du kannst dein Modell mit nur drei Zeilen Code in einem Framework trainieren und es dann in einem anderen Framework laden, um Schlussfolgerungen zu ziehen. Die Architektur jedes Transformators ist in einem eigenständigen Python-Modul definiert, sodass sie für Experimente und Forschungszwecke leicht anpassbar sind.
Die Bibliothek kann man jetzt unter der Apache-Lizenz 2.0 nutzen.
Wenn du mehr über Transformers erfahren willst, schau dir ihre offizielle Website oder das GitHub-Repository an und check unser Tutorial zur Verwendung von Transformers und Hugging Face aus.
⭐ GitHub-Sterne: 119K | Gesamtzahl der Downloads: 62 Millionen
LangChain ist das Standard-Orchestrierungsframework für große Sprachmodelle (LLMs). Damit können Entwickler verschiedene Komponenten miteinander verbinden, zum Beispiel ein LLM (wie GPT 5.2) mit anderen Rechen- oder Wissensquellen.
Es macht die Arbeit mit Eingabeaufforderungen einfacher, sodass du ganz leicht „Agenten” erstellen kannst, die Tools (wie einen Taschenrechner, die Google-Suche oder eine Python-REPL) nutzen können, um Probleme mit mehreren Schritten zu lösen.
from langchain.chains import LLMChain
# Example: Creating a chain that takes user input and formats it
# before sending to an LLM
chain = prompt | llm | output_parser
result = chain.invoke({"topic": "Data Science"})⭐ GitHub-Sterne: 123K+ | Status: GenAI Essential
Während LangChain sich um das Schlussfolgern kümmert, macht sich LlamaIndex mit den Daten klar. Es ist das führende Framework für RAG (Retrieval-Augmented Generation). Es ist darauf spezialisiert, deine privaten Daten (PDFs, SQL-Datenbanken, Excel-Tabellen) zu erfassen, zu indexieren und abzurufen, damit LLMs Fragen dazu genau beantworten können.
Im Jahr 2025 ist „mit deinen Dokumenten chatten” ein ganz normaler Business-Anspruch, und LlamaIndex hat die Datenstrukturen drauf, die das effizient und ohne Probleme machen.
⭐ GitHub-Sterne: 35K+ | Status: RAG-Standard
Damit LLMs sich Infos „merken“ können, brauchst du eine Vektordatenbank. ChromaDB ist die Open-Source-Vektordatenbank mit KI, die für Python-Entwickler zum Standard geworden ist. Es kümmert sich um die ganze Sache mit dem Einbetten von Text (also das Umwandeln von Wörtern in Zahlenlisten) und speichert sie für die semantische Suche.
Anders als bei herkömmlichen SQL-Datenbanken, die nach exakten Schlüsselwörtern suchen, kannst du mit ChromaDB nach Bedeutung suchen. Das macht es zum Langzeitgedächtnis-Backend für moderne KI-Anwendungen.
⭐ GitHub-Sterne: 25K+ | Status: Vektor-Speicher-Standard
Die richtige Python-Bibliothek für deine Aufgaben in den Bereichen Data Science, maschinelles Lernen oder natürliche Sprachverarbeitung auszuwählen, ist echt wichtig und kann den Erfolg deiner Projekte stark beeinflussen. Bei der großen Auswahl an Bibliotheken ist es wichtig, verschiedene Faktoren zu bedenken, um eine gute Entscheidung zu treffen. Hier sind ein paar wichtige Punkte, die dir helfen sollen:
Wenn du diese Faktoren genau checkst, kannst du eine gute Entscheidung treffen, wenn du Python-Bibliotheken für deine Data-Science- oder Machine-Learning-Projekte suchst. Denk dran, dass die beste Bibliothek für dein Projekt von den spezifischen Anforderungen und Zielen abhängt, die du erreichen willst.
Um deine Karriere im Bereich Data Science zu starten, mach den Lernpfad „Data Scientist in Python “.
Kurse für Python-Bibliotheken bei DataCamp
Kurs
Kurs
Kurs
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
Tutorial
Laiba Siddiqui
Tutorial
Mark Pedigo
Tutorial
Allan Ouko

