
Course
Feature Engineering for Machine Learning in Python
4 hr
38.8K
Machine learning (ML) models are computer-based implementations of statistical and probabilistic methods. They generally adopt one of two approaches: generative or discriminative modeling.
In this article, we provide an overview of generative and discriminative models, introduce common models of each type, explain the mathematical principles behind both approaches and discuss practical examples of the problem types for which each type of model can be used.
Given a set of example data points, D, and their associated labels, L, a generative model learns the joint probability distribution P(D, L). It then uses this underlying distribution to generate new data similar to the training examples or address classification problems.
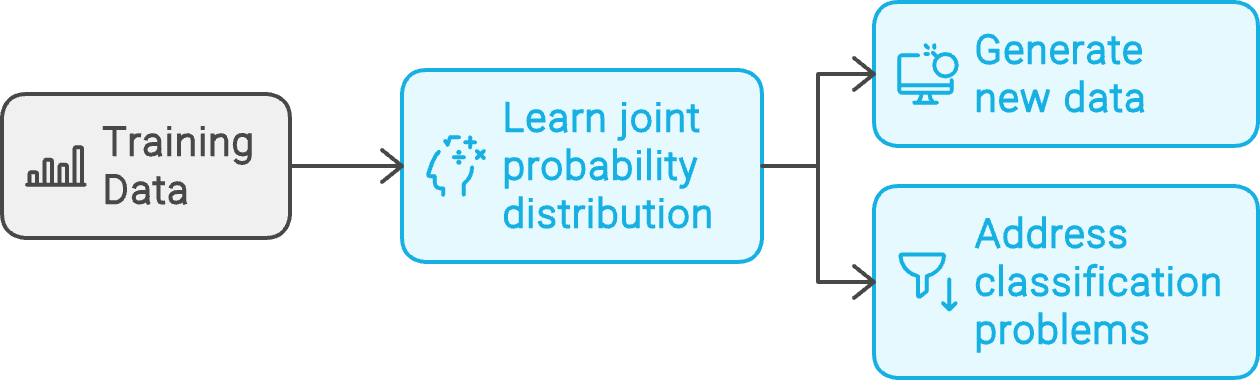
Generative model workflow. Created with napkin.ai
The following sections explain the fundamentals of generative models with examples.
Naive Bayes models are based on the Bayes theorem. This theorem gives the conditional probability P(A | B) of an event A when it is known that the event B is true. This is called the posterior probability of A given B.
Individually, the probability P(A) of event A is called the prior probability. Naive Bayes models assume that A and B are independent events - hence the prefix “naive.” If A and B are dependent, the traditional Bayes theorem no longer applies, and Naive Bayes models are not the right choice.
Bayesian models are generative models because they model the joint probability distribution. The training process learns the joint probability—P(A, B). After training, it can be used to predict the values of A with the highest probability P(A). Furthermore, Bayesian models can also be used for classification because they can compute conditional probabilities (using the Bayes rule).
To learn to use naive Bayes models in practice, follow the tutorial on building Naive Bayes models using scikit-learn and Python.
Gaussian mixture models (GMM) are a class of mixture models. Their unique premise is that the underlying data combines statistical distributions instead of a single distribution.
In a GMM, the population is assumed to be a combination of different subpopulations, each of which is a Gaussian distribution. Effectively, the data distribution is analyzed as a weighted average of a few individual Gaussian distributions.
GMMs capture the probability distribution of the underlying dataset. Thus, they are used for tasks like outlier analysis and unsupervised classification. These tasks involve building a statistical model of the population by treating the training dataset as a random sample.
The course on mixture models in R goes into the practical details of GMMs.
A generative adversarial network (GAN) is a neural network-based model. It consists of two parts: a generator and a discriminator. The generator network is trained to generate vectors similar to the training examples, while the discriminator is trained to distinguish between the original examples and those generated by the generator.
In essence, the generator and the discriminator have opposite training goals, making them adversarial. Hence, the word “adversarial” is used in the name.
The generator and the discriminator are trained together in the same training loop. As the generator gets better at creating realistic examples, the discriminator distinguishes the original examples from the generated ones. The training continues until the generator learns to generate examples that are so similar to the training data that the discriminator cannot distinguish between them.
After training, the generator is used to generate realistic synthetic data similar to the original examples.
A hidden Markov model (HMM) works with sequential datasets. Markov processes (or Markov chains) are used to model sequential data. The premise of a Markov model is that the next element, xn+1, in the sequence depends only on the previous element, xn, and not on any of the elements, {x1, x2, ... xn-1}, before it. Markov models assume that the sequential datasets can be represented by Markov processes with hidden states.
These states generate the next element in the sequence:
Markov models are represented with transition probabilities (going from one state to another) and emission probabilities (generating a particular sequence element given a particular state).
HMMs model the training datasets as Markov processes. The training goal is to determine the transition and emission probabilities to maximize the probability of generating the sequences in the example datasets. Thus, given a sequence, a trained Markov model can generate the successive elements of the sequence.
To learn about their practical implementation, follow the tutorial about Markov chains in Python.
Given a training dataset consisting of data points, D, and their associated labels, L, a discriminative model learns the conditional probability distribution P(D | L). It then uses this conditional probability distribution to predict the class of new data points.

Discriminative model workflow. Created with napkin.ai
Discriminative models are generally used to solve classification problems. The following examples demonstrate their use cases.
K-nearest neighbors (KNN) is one of the older machine learning models. It is based on the premise that, given a distribution of data points, similar items are located in proximity.
KNN models are nonparametric, with no parameters like regression coefficients. They are used for both classification and regression problems.
An input data point's category is the same as its k nearest neighbors. The predicted value of a datapoint is the average value of its k nearest neighbors. k (the number of nearest neighbors to consider) can be considered a hyperparameter of the model. It is used to tune the model's behavior, but it doesn’t directly affect the model’s output.
Logistic regression, like linear regression, tries to predict the value of a dependent variable based on one or more independent variables. In linear regression, the dependent variable takes on continuous values. In logistic regression, the dependent variable takes discrete values, such as:
Linear regression predicts numerical values. In logistic regression, the predicted quantity is the logarithm of the odds ratio.
For an event A, with probability P(A), the ratio of odds is P(A) / (1 - P(A)). Using the logarithm (of the odds ratio) leads to smoother and faster convergence during the training process. Given their ability to segregate inputs into classes, logistic models are used for discriminative purposes.
For a more hands-on introduction to this topic, refer to the guide on logistic regression in Python.
You can also implement logistic regression using R, a statistics-oriented programming language, as explained in the tutorial on logistic regression using R.
Support vector machines determine the optimal line that separates data points of different classes. In the 2-dimensional X-Y plane, given a collection of data points of two different categories, the SVM predicts a line that (ideally) cleanly separates points of one category from the other.
This line is the decision boundary. It becomes a hyperplane for data with three or more dimensions. Data points (from either category) that lie closest to this imaginary line are called the model's support vectors. These data points are the hardest to classify since their values are close.
The distance between the separating line and the support vectors is called the margin. SVM training aims to find the decision boundary that maximizes this margin. In practice, data points have more than two dimensions, and the separating line is a higher-dimensional hyperplane.
SVMs are also used for multi-class classification problems.
To learn more about SVMs, follow this guide on building SVMs using the Python scikit-learn package. Besides Python, you can also use R to implement SVMs, as discussed in this guide on SVMs in R.
A decision tree consists of several decision nodes organized in a tree-like structure.
The topmost node is the root. Nodes that lead to final outputs are called leaf nodes or terminal nodes. Intermediate non-leaf nodes are called internal nodes. The output from the root node feeds into the intermediate nodes. Each node's result (output) is either the final output or leads (branches) to another node.
Each node of the tree splits the dataset along a particular attribute. For example, a decision tree for approving loan applications might have nodes to segregate applications by their net income.
The training process determines the appropriate threshold value for each decision. For example, applications with net income below a certain amount are outright rejected. The rest are processed further in subsequent nodes, which consider other attributes, like net wealth.
For a hands-on guide to decision trees, follow the tutorial on building decision trees using Python, or the comple course on machine learning with tree-based models in Python.
The main drawback of decision trees is overfitting, leading to out-of-sample data problems. Decision forests try to solve this problem. A decision forest consists of many trees. Unlike standalone decision trees, which must consider the entire feature set, each tree in a forest only finds a random subset of the feature set. This randomness helps tackle the variance in noisy datasets.
The forest output is obtained by combining, for example, by averaging, the output of individual trees.
To learn how to implement random forests, refer to the guide on using scikit-learn to build random forest classifiers.
A neural network consists of groups of neurons. Each neuron implements a linear function that multiplies the neuron's weights with the input vector.
A non-linear activation function follows the linear function. The activation function decides the output of each neuron based on the output of the linear function. Thus, a simple neural network can conceptually be seen as a series of linear equations filtered by non-linear activations.
The input layer of a neural network multiplies the input (represented as a vector) by a set of weights and activation functions. This output is passed to the next layer, which performs a similar operation.
Hidden layers are between the input and output layers. The last hidden layer feeds into the output layer. Complex problems involve using neural networks with many hidden layers, which are called deep neural networks (DNNs).
In a classification problem, a common approach is to have as many output neurons as the number of classes. The predicted class corresponds to the neuron with the highest value. In a regression problem, a single output neuron contains the predicted output. The neurons' linear relationships model the linear regression equation.
For a more in-depth understanding of the topic, check out the blog post on neural networks.
Some tasks, like classification, can be solved using either model type. In general, however, discriminative and generative models often have unique use cases, as these models adopt different mathematical approaches. Understanding these differences and how they affect the suitability of either category of models to various problems is necessary.
Generative models predict the next value in a sequence or generate an image given a text (or vice versa). To do such tasks, the model has to learn which output to generate given different inputs. The model uses the joint probability distribution of the input and the output.
To understand the underlying mathematics, let’s start with a simple example. The behavior of a single random variable is described by its probability density function (PDF).
The PDF of the random variable X can be used to determine the probability of X at different values. For example, if the PDF of X is f(x), the probability that X lies between A and B is given by:
![]()
The probability of X over the entire range is 1. This is expressed as :
![]()
The above expression can also be written as:
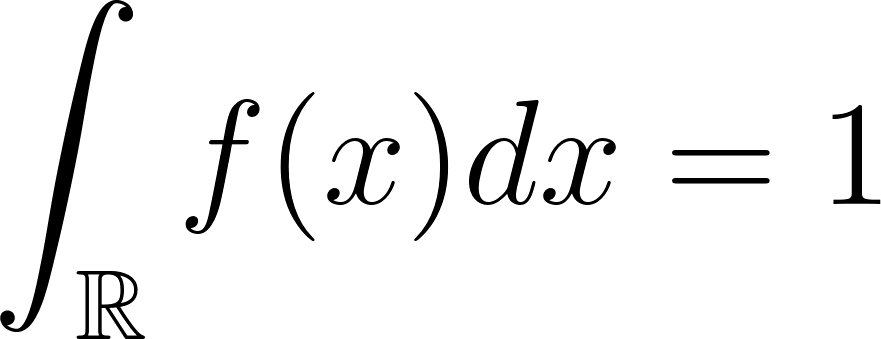
For a joint PDF of two variables, X and Y, the integral over the entire range is 1:
![]()
The joint probability distribution maps the entire probability space of both X and Y. To evaluate the probability that the joint probability P(X, Y) falls in a region G, integrate the joint PDF over G:
![]()
Discriminative models, instead, focus only on the conditional probability distribution. Generative models, if needed, estimate the conditional probability using the marginal probabilities.
Given a joint probability distribution fXY(x,y), the marginal probability of the random variable Y at the value y (for all values of X) is given as:
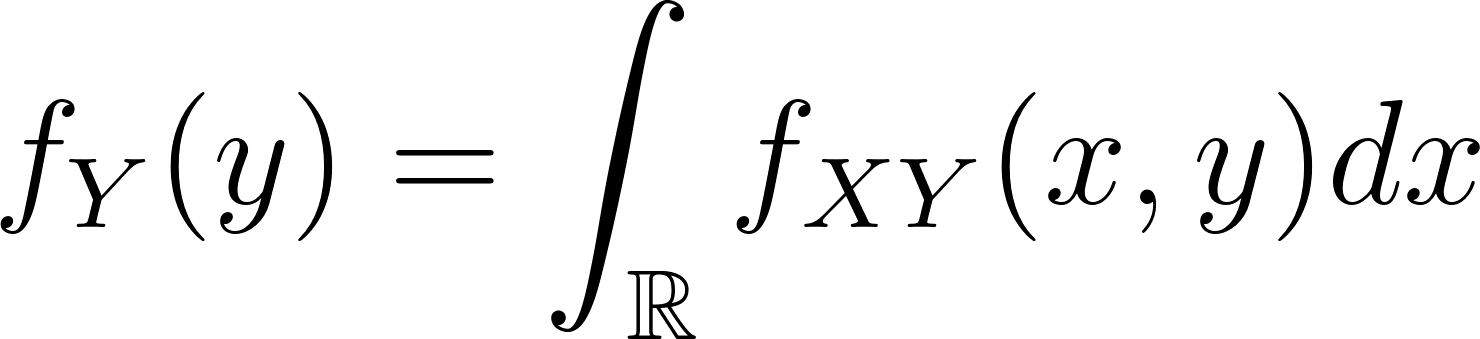
Similar to Bayes rule, the conditional PDF of X is then expressed as:
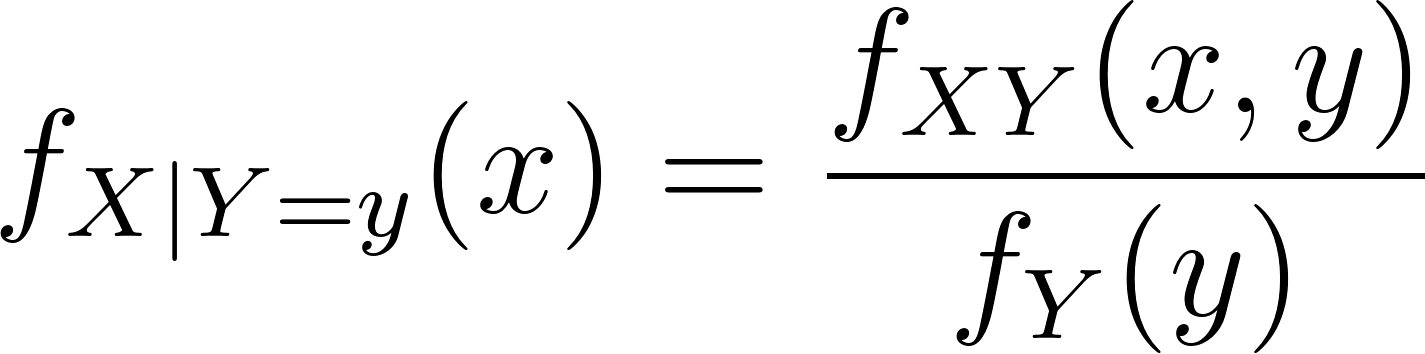
The above expression shows the integral version of the conditional probability, which is more commonly written as:
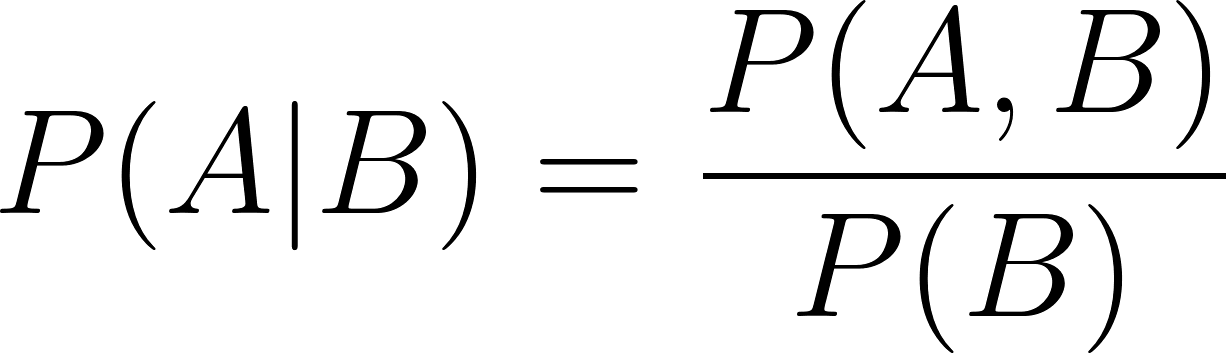
Similarly,
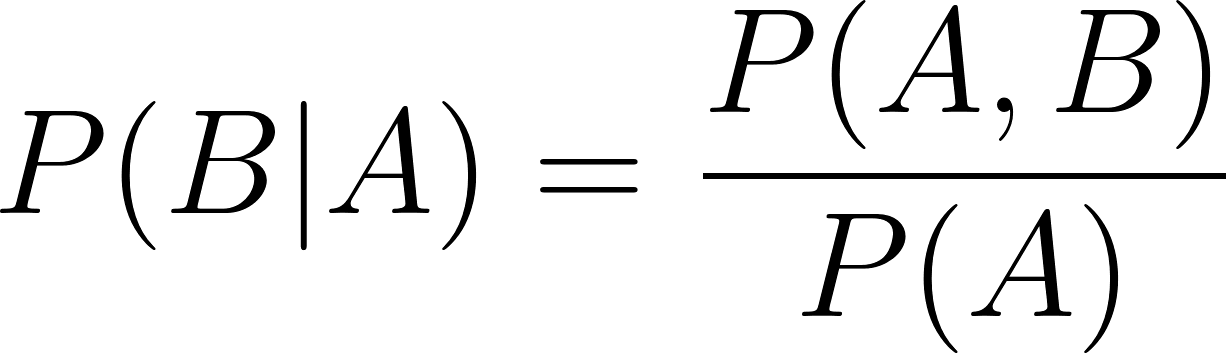
In the two conditional probability formulae above:
To compute a conditional probability, generative models follow two steps:
On the other hand, discriminative models follow a single (and simpler) step:
A generative model has the marginals P(A) and P(B) and the joint PDF P(A, B). Using these, it can evaluate P(A | B) or P(B | A) with equal ease. This is the underlying idea behind naive Bayes classifiers. Thus, generative models can do tasks like:
This makes generative models flexible and multipurpose. On the other hand, they inherently involve more complexity during training because:
Discriminative models, on the other hand, are concerned only with conditionals. Based on the training dataset, it is possible to estimate the conditional probabilities directly without estimating the joint or marginal probabilities.
Thus, discriminative models are simpler to train. However, a discriminative model that has learned the conditional probability P(A | B) can only perform tasks involving this particular conditional probability. It cannot do anything else.
Generative models are flexible enough for both generative and discriminative tasks. During training, the model learns the joint PDF and the marginals. During inference, the model must compute the conditional probability using the joint distribution and the appropriate marginal probability. Hence, inference on discriminative tasks is slower.
Discriminative models, on the other hand, have directly (numerically) learned the conditional probabilities. They estimate the conditional probability in a single step based on the input data during inference.
Furthermore, because discriminative models are focused only on estimating a single quantity (the conditional probability), they are observed to be more accurate. A joint PDF has more uncertainty built into it than a simple conditional probability. This added uncertainty is reflected in the relatively lower accuracy of generative models for classification tasks.
Based on the discussion in the previous sections, the table below summarizes the differences between generative and discriminative models.
|
Generative models |
Discriminative models |
|
|
Objective |
Capture the joint probability and marginal probability. Use Bayes' rule to compute the conditional probability. |
Capture only the conditional probability. There is no information on joint or marginal probabilities. |
|
Data generation |
Can generate new data points based on the training dataset. For example, a model trained on handwritten digits can generate new, fake digits. |
Cannot generate new data points. Primarily focused on distinguishing between different categories of data. |
|
Primary use case |
Can be used for both generative tasks (e.g., data synthesis) and discriminative tasks (e.g., classification). |
Can only be used for discriminative tasks such as classification or regression. |
|
Inference performance |
Running inference is slower due to the need for complex computations. Even simple tasks require calculating marginal and joint probabilities and applying Bayes' rule. |
Faster inference because it directly computes the conditional probability without involving Bayes' rule. |
|
Handling missing data |
Better at handling missing data by modeling the underlying probability distribution, making it easier to "fill the gaps." Lower risk of overfitting. |
Less effective at handling missing data. Higher risk of overfitting because the model focuses on finding the separating hyperplane between classes. |
|
Convergence |
They tend to converge faster and with fewer training examples but generally result in a higher model error, especially in classification tasks, due to the indirect computation of the conditional probability through modeling the joint probability distribution. |
They generally require more data to train and may converge more slowly. However, the result is a lower model error, especially in classification tasks, because they directly model the conditional probability without estimating the joint probability distribution. |
|
Model complexity |
They are typically more complex because they model the entire data distribution, including the interactions between features and labels. |
Generally more straightforward because they only need to model the decision boundary or separate hyperplane between classes. |
|
Examples of models |
Naive Bayes, Hidden Markov Models (HMMs), Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs). |
Logistic Regression, Support Vector Machines (SVMs), Neural Networks, and Decision Trees. |
|
Model flexibility |
More flexible in terms of application (can handle both generative and discriminative tasks). |
Less flexible (limited to discriminative tasks). |
|
Error rates |
Higher error rates in classification tasks due to indirect estimation methods. |
Lower error rates in classification tasks due to direct training on conditional probability. |
As the name suggests, generative models are uniquely suited to tasks that involve generating new data that fit the patterns in the training data.
Some common use cases of these models are:
For many computer vision models, having a large dataset of training images is essential. These models need to be trained on many variants of the same image or feature.
Taking pictures of the same object from different angles, backgrounds, or shades of color is not always realistic. Many task-specific image datasets also tend to be limited in size because creating them requires domain-specific skills. For example, you need access to pulmonologists, radiology labs, and consenting patients and hospitals to create an image set of X-rays of a specific lung disease.
In such cases, the most pragmatic option is to create a small but highly curated and relevant dataset and then synthetically generate new data points similar to the original dataset.
Generating new images given a text description or generating new text given some input text. The only class of models that can handle such tasks are generative models.
Image generation models like DALL-E, MidJourney, and Stable Diffusion are routinely used to generate images that suit a specific description and do not infringe existing copyright.
Similarly, LLMs are often used to generate fictional story plots, marketing slogans and taglines, document summaries, and other similar materials.
Generative models are used for tasks based on the underlying data's joint probability distribution. Modeling the joint distribution of asset returns to predict an investment portfolio's expected risk and return profile is standard in finance and risk management.
For example, an investment manager might want to know the probability of the prices of two different stocks rising or falling at the same time—joint PDFs can answer such questions.
The financial services industry has been using these statistical methods long before the term “generative models” was widely adopted.
Problems like unsupervised classification are uniquely suited to Gaussian mixture models. In these problems, you have an extensive collection of data points but do not know how many or what categories the data points belong to. It is reasonable to expect that the data comes from a combination of distributions, which a GMM can model.
If the number and list of categories had been known in advance, discriminative methods would have been more appropriate.
GMMs are also helpful in outlier analysis (anomaly detection, fraud detection, etc.), where the “usual” data, like the behavior of different customer groups, can be modeled as a combination of different distributions. Anomalous data points are those that differ significantly from any of the other patterns.
Problems involving sequences are often solved using hidden Markov models. An everyday use case is modeling genome sequences and re-sequencing.
HMMs are also used in speech recognition, where they help predict the next syllable given the sequence of preceding syllables. Sequence modeling is also standard for logistics applications like package delivery schedules. Similarly, transmission and spread of infectious diseases are often modeled using Markov chains.
Mathematically, discriminative models are used for applications where only the conditional probability is relevant but not the joint probability. Thus, discriminative models are typically used for classification problems and prediction problems.
Some examples are:
Supervised classification problems, where the classes (categories) are known in advance. This is the quintessential use case for KNNs and SVMs.
You have an extensive collection of data points, such as customer behavior data, including spending patterns, purchase amounts, buying frequency, return history, and so on. You need to use this information to classify the list of customers into different categories, such as high spenders, bargain hunters, regular customers, non-serious customers, etc. Contrast this to unsupervised classification problems, where, as discussed earlier, GMMs are commonly used.
In predictive tasks like classification and regression, the priority is often speed and accuracy. In principle, generative models are also capable of solving such problems.
In particular, generative models are preferred when there are issues like missing data points, when only a limited dataset is available for training, or when you expect to add new categories routinely.
However, for most standard use cases, generative models suffer from higher error rates and slower inference in predictive tasks because their computation involves the joint probability distribution. Hence, for standard classification and regression problems, where a large and healthy dataset is available for training, discriminative models are the preferred choice due to their better performance characteristics.
Discriminative models are preferred for tasks that focus only on the classification's outcome and not on modeling the underlying data.
For example, if you want to categorize audio recordings into their respective languages, you do not need a model that understands the language and the grammar. A speech recognition model would be overkill for a classification problem. It is sufficient to focus on the decision boundary using a discriminative model. So, you can use a simple neural network instead of an LLM or logistic regression instead of a Bayesian model.
Multi-step decisions, where the individual steps involve unambiguous choices, are good candidates for decision trees. Decision trees are often used as a preliminary filter to shortlist data points that require deeper analysis.
For example, consider fraud detection, often solved using complex models like GMMs. Humans almost always investigate high-risk transactions, regardless of the model used. So, an alternative approach is to use a decision tree to flag a list of potentially fraudulent transactions for further manual investigation.
Decision trees are also used in many business operations. The goal is to decide the right course of action based on predetermined conditions. Such tasks need neither generative models nor the more complex discriminative models like neural networks.
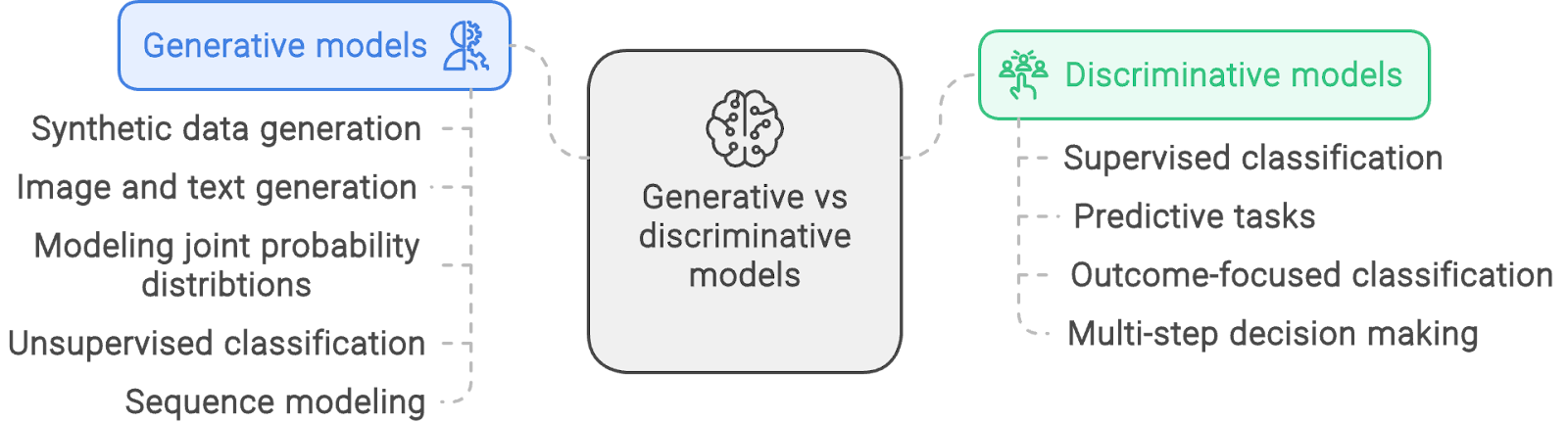
Example applications of generative vs. discriminative models. Created with napkin.ai
This article explained the fundamental principles and main differences between generative and discriminative models, the two major approaches to machine learning techniques.
Though most machine learning is based on probabilistic methods, generative models are based on the joint probability distribution, while discriminative models use only conditional probabilities. Thus, the two classes of models have different applications and performance characteristics. Considering the availability of a wide variety of models, choosing the right tool for the job becomes essential.
Beyond a conceptual understanding of model types and their differences, it is more important to build models yourself. Start with the blog post discussing supervised training methods and building a simple logistic regression model.
Learn more about machine learning with these courses!
Course
Course
Course
blog
Abid Ali Awan
11 min
blog
Kurtis Pykes
12 min
blog
Abid Ali Awan
10 min
blog
Matt Crabtree
10 min
blog
Zoumana Keita
14 min
Tutorial
Matt Crabtree


